前面幾篇文章中,咱們大致上學習完了應用層的一些性能優化的基本知識,接下來咱們要來學學資料庫層的高性能優化方向。
在這裡先說一下一個重點 :
資料庫絕對是一個系統的性能核心,請把優質的 DBA 們當寶來餵食
接下來幾篇資料庫層文章將會以『 MySQL 』來進行說明,雖然不同的資料庫可能實作上會有些不同,但是大致上原理不會差距太大。
開始第一篇文章,咱們將要先理解一些 MySQL 的基本架構,接下來才能理解那些地方可能可以進行性能優化,又是那一些地方可能是會拖後腿,但是又是必要存在的地方,這篇也算是資料庫篇的小目錄。
本篇文章分成以下幾個章節 :
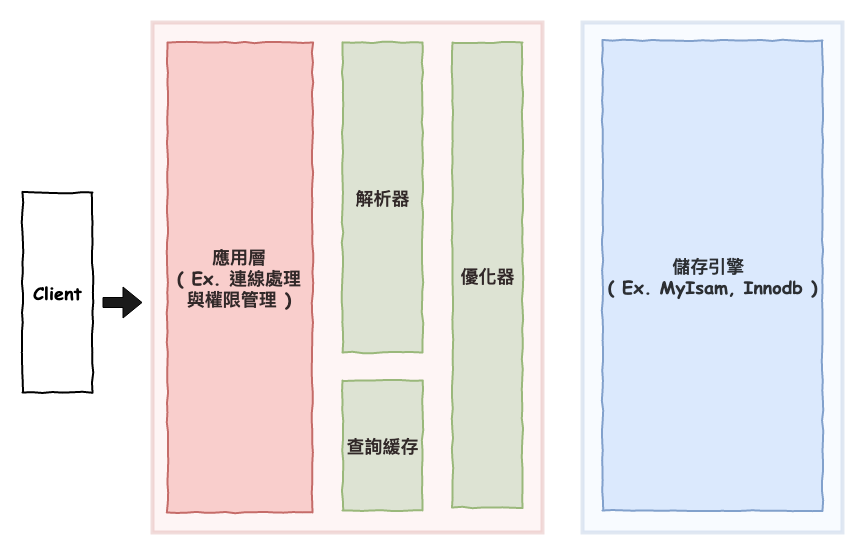
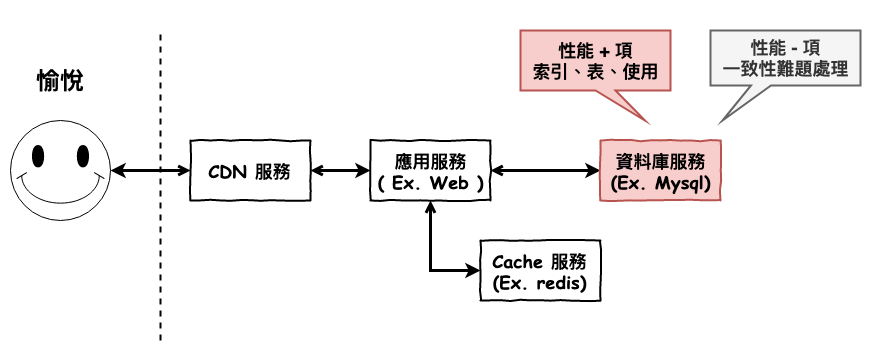
圖 1 : mysql 的基本架構
基本上分為以下幾個部份 :
應用層主要處理兩個工作 :
其中連接處理任務就是每當一個 client 端發送一個請求到 mysql 時,它會在從 thread poll 中分配一個 thread 來處理此請求,然後之後從此 client 來的任務,都會由此 thread 來處理。
mysql 並沒有使用之前說的非阻塞 I/O 模型 ( reactor ) 來處理請求的,原因可能在於,mysql 的任務是屬於 cpu 運算密集與磁碟 I/O 密集任務,因此比較不適合使用 reactor 這種使用 epoll 的模型。
另一種可能原因為當時 mysql 出來時間很早,那個時空背景的確沒有很好的 i/o 處理模式,所以到了現在真的支援非常的困難。
服務層最重要的有以下幾個部份,這幾個部份與我們操作 sql 性能習習相關。
首先來說說『 SQL Parser 』,它會將你所下達的 sql 指令,依據規則,將它轉化成抽象語法樹( Abstract Syntax Tree,AST )。
SQL -> PARSER -> AST
ast 基本上是用來描述語法的資料結構,像一些 ids 所提供的工具,都需要將你寫的語法產生 AST 才能幫你進行程式碼的 style 修改或啥的。
接下來『 Optimizer 』部份。這裡會將你的 AST 進行優化,比較白話文的說法就是 mysql 會自動將你的 sql,以它覺得最有效率的方法來處理。
最後是 『 SQL Cache 』。每當進行搜尋時,都會先至此處理看看有沒有緩存命中,有的話就直接取得,無的話,則將進行 Parser、Optimizer、執行。
有 : 回傳 Cache
無 : SQL -> Parser -> Optimizer -> 執行
這裡就是實際上要決定,如何處理與儲放你的資料,而用什麼儲存手法就由各種不同的存儲引擎來決定。
Mysql 基本的預設存儲引擎為 :
Mysql 事實上內部有一個 cache,它叫『 query search 』,但看了不少篇文章都是建議,如果是 99% 以上的任務都是讀取相關的,才建議開啟,否則不要開啟。
會有這樣的結論有兩個原因 :
BTW 如果你們公司本來就已經打開緩存了,那可以使用以下的指令看看,你們 cache hit 到底是多少,來決定要不要繼續開這查詢緩存。
SHOW GLOBAL STATUS WHERE Variable_name='Qcache_hits' OR Variable_name='Com_select';
接下來咱們簡單的看一下一個 sql 它在 mysql 中是會如何運行的。
如下圖 2 所示 :
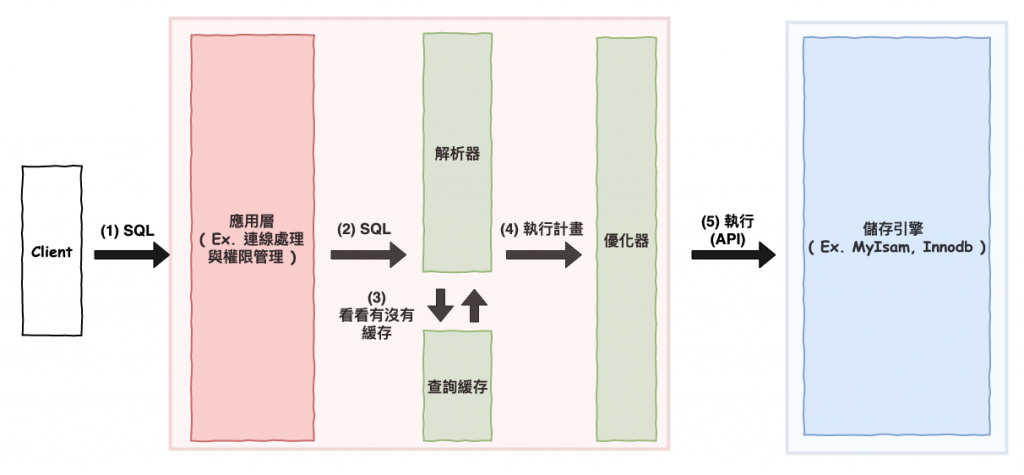
圖 2 : mysql 的運行流程。
咱們基本上理解完 MySQL 基本架構以後,接下來咱們要來看看性能優化的方向,與有沒有什麼地方是性能的減項,但是又一定是需要它的地方。
基本上在下圖的兩個地方 :
首先咱們最重要的地方在於存儲引擎,雖然咱們應用端不太會直接和他接觸,但是如果你不理解它,會完全的無法理解,為什麼要進行之後要說的優化,因此咱們這個部份會往以下幾個地方探討。
索引基本上就是資料庫的心臟,索引設計好,帶你上天堂,設計不好,帶你下地獄。而在 mysql 中,就是描述你的資料如何儲的方法,當然不是儲一般檔案那麼簡單,而是需要設計一套規則,來加速查詢,這才是索引真正要做的事情。
基本上咱們理解完資料如何儲以後,就可以來理解一些咱們實際上如何的優化 sql 性能的技巧,基本上分為以下幾個部份,然後這一些都是會在優化器裡面處理掉。
資料庫性能大敵就是 :
一致性難題
咱們先簡單的看兩個簡單例子,基本上以下兩個例子,就是咱們資料庫最常見的問題,但這只是冰山一角,之後的文章會更詳細的說明,然後你會發現,下面兩個真的只是個小角落。
在之後的文章中咱們詳細的說明 mysql 它到底是如何的處理『 一致性 』這難題的呢 ?
這是一個老掉牙的範例,但是也是最真實的範例。
假設有一個情境要實作 :
帳戶 A 轉帳 1000 元至帳戶 B
而基本上你的操作步驟為:
但如果在進行完 1 後,資料庫掛了,你要如何處理呢 ? 這就是咱們的第一個問題。
假設有一個情境要實作 :
用戶 A 投了 Z 一票,用戶 B 也投了 Z 一票
而基本上你的操作驟為 :
但問題來了,如果 1、2 是幾乎同時間取出 Z 的票數,要如何處理呢 ?
本篇文章咱們簡單的理解一下 mysql 的架構與一些性能優化的方向,這方向也就是咱們接下來幾篇的重點,接下來資料庫篇要正式的開始囉。
最後咱們重複說一句話 :
資料庫絕對是一個系統的性能核心,請把優質的 DBA 們當寶來餵食
這點真的很重要。

