學習幾個方向:深度學習,補充數學知識,詞嵌入,變分自編碼器
注意:請搭配每日課程觀看以達到最好效果
Faster.ai
看完今日教學,理解卷積,協同處理,自編碼器,變分自編碼器

3.得到最大似然估計
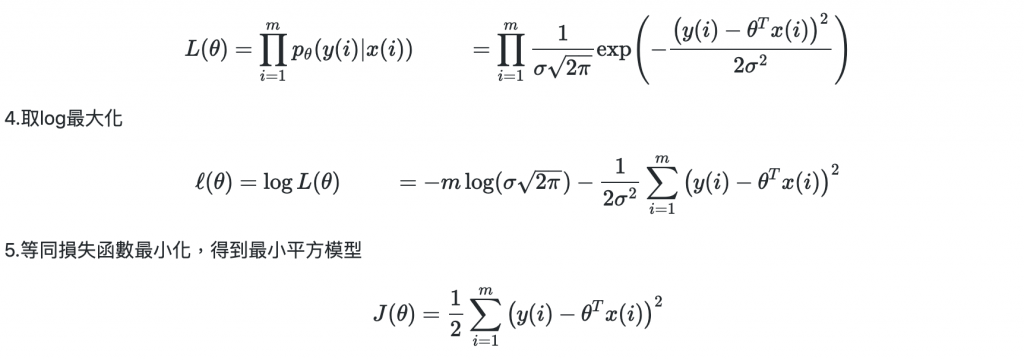
6.將最小平方模型,偏微分為

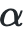 :學習率
:學習率


1.Pytorch中Dataset
len: 取得資料集長度
getitem: 取得第i筆資料
Pytorch 中使用: torch.utils.data.Dataset
2.有三種查看資料的方式
1.Batching批次查看資料
2.Shuffling不照順序查看資料
3.提供多核心處理器使用者的方式
Pytorch 中使用: torch.utils.data.DataLoader
另外還介紹了one-hot跟embeddings
One-hot: 最原始表示詞中每個字的方法,每個都對應成一個向量,所以用矩陣表示出來是稀疏的
Embeddings: 將大型稀疏矩陣表示的更簡潔,所以說是稠密的
輸入編碼成保有原始特徵但少量的資訊,再解碼回去,編碼有點像CNN
但如果我們隨意選潜在向量,因為潜在向量沒有結構,我們可能會拿到無意義資訊
所以需要變分自編碼器
編碼: 將複雜模型對應更成簡單分佈
解碼: 對分佈採樣
將原始資訊對應成分佈,而非離散值,因為要確保之後採樣值跟原始盡量接近,但也不能不採樣用實際資料,因為要生成新的圖
之後用KL散度觀察原始與生成分佈是相近的
生成網絡: 從潛在空間(latent space)中隨機取樣作為輸入,其輸出結果需要盡量模仿訓練集中的真實樣本
判別網絡: 將生成網絡的輸出從真實樣本中盡可能分辨出來
兩個網絡相互對抗、不斷調整參數,最終目的是使判別網絡無法判斷生成網絡的輸出結果是否真實
loss方法程式
分類的程式
介紹如何寫Pytorch模組
操作資料及範例
Embedding程式
AE,VAE應用與撰寫
識別手寫數字
推薦系統中的協同處理
非監督學習中的自編碼器
變分自編碼器
為什麼不直接最大化準確率?
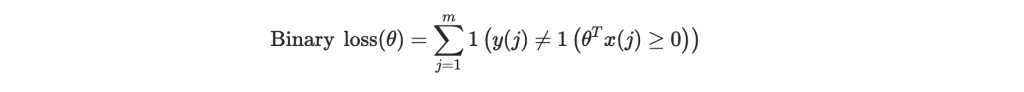
Binary Cross Entropy Loss是凸函數,我們用離散最佳化問題取代,但他斜率是0,無法微分更新
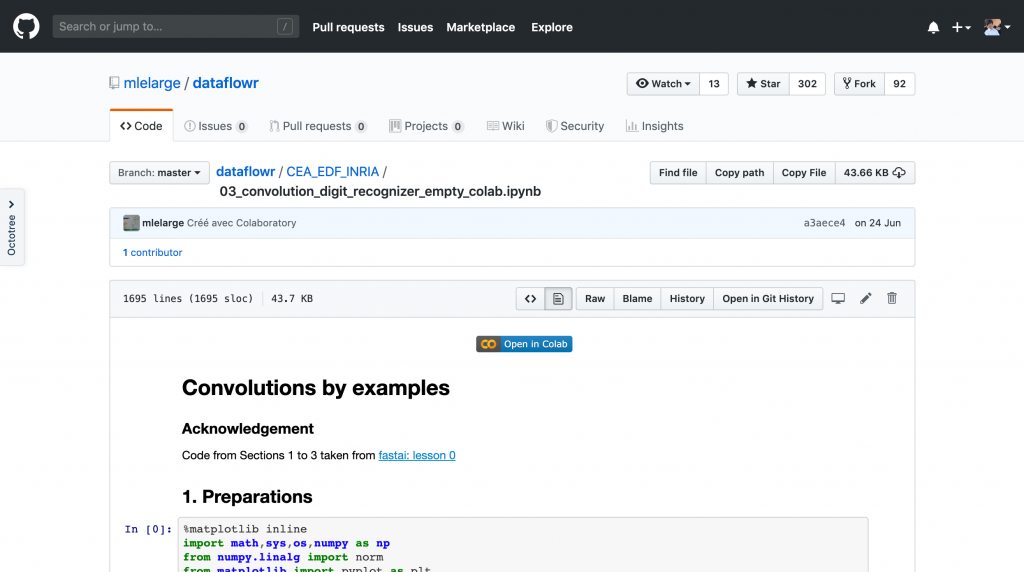
回到我們昨天最後的問題,我們可以直接點藍色colab按鈕更快存取
會跳出colab頁面,更名後
可以在Google Drive看到黃色colab檔案
https://mlelarge.github.io/dataflowr-web/cea_edf_inria.html
https://www.itread01.com/content/1543994346.html
https://zh.wikipedia.org/wiki/生成对抗网络

