在利用Many to Many的RNN訓練語音辨識的問題時,會遇到一些小問題:
當我們要分辨一個語音檔(sequence)時,Output的字詞也會是一組sequence,代表每個時間點是屬於哪個字詞。當我說出「好棒」這個詞時,電腦可以正確辨別。但當我說出「好棒棒」時,電腦可能無法把第一個「棒」和第二個「棒」分開來,導致把「好棒棒」辨識成「好棒」,這兩個詞的意思可是完全不一樣呢(笑)。
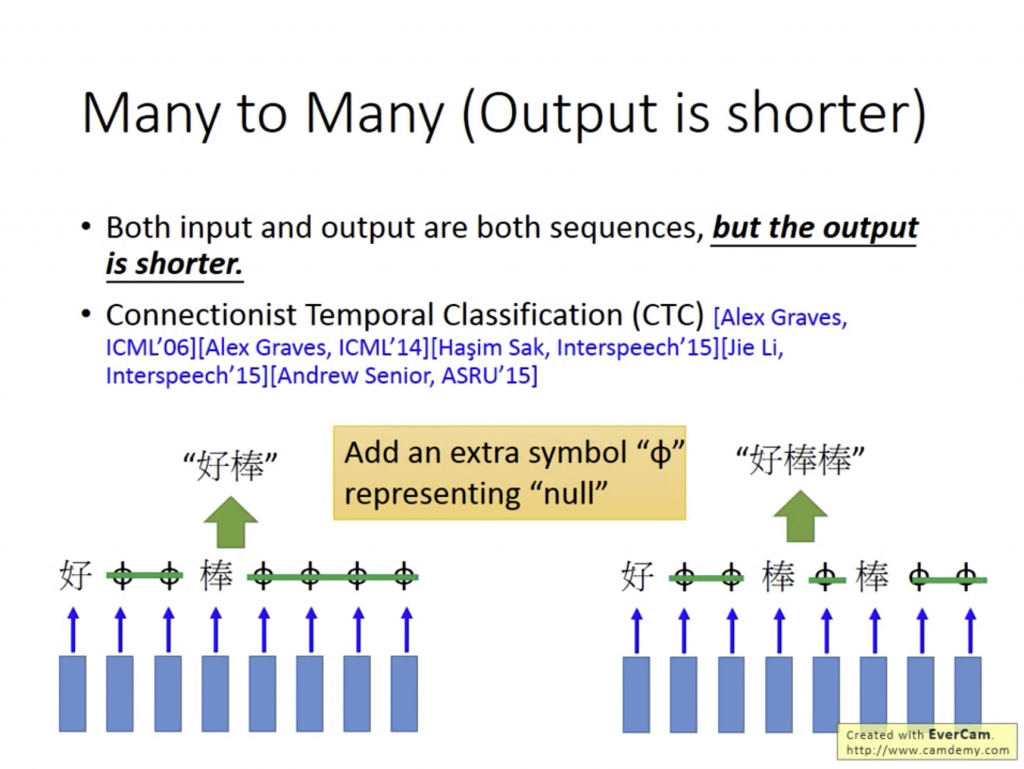
使用CTC的中心精神,就是適當在Output時可以輸出Null值,讓字和字之間斷開。但這會有訓練上的問題,必須要讓電腦窮舉出所有有可能的種類並判斷。
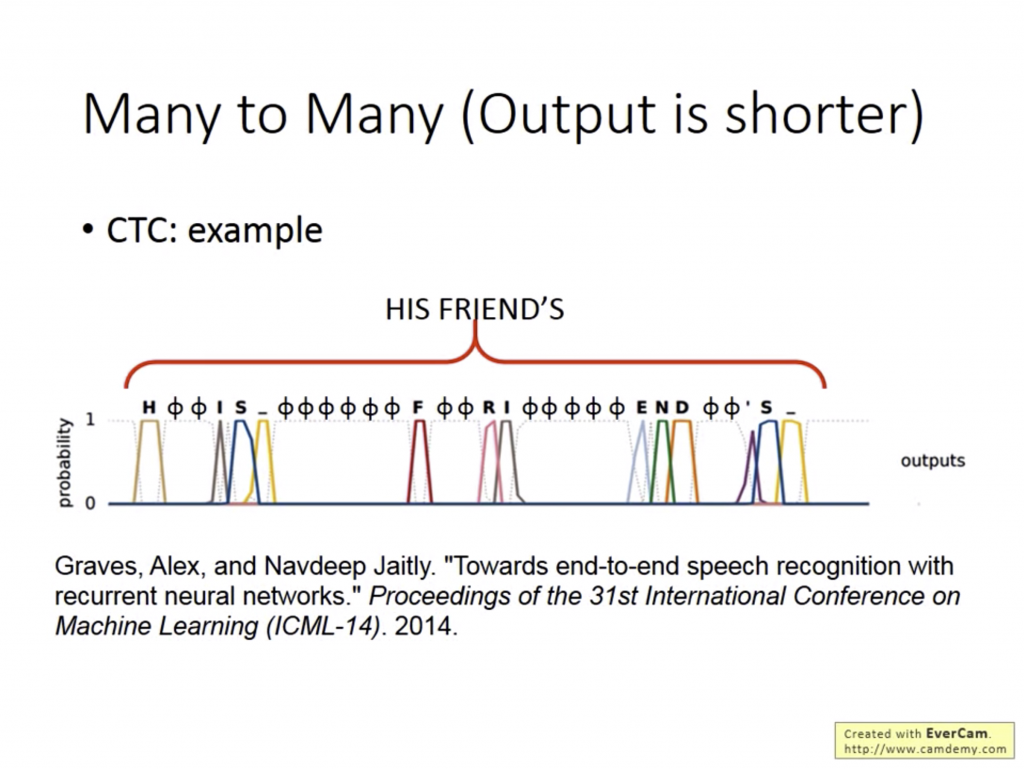
假如我輸入一個聲音檔,輸出是由所有字母、空格、符號和Null組成的sequence,這時電腦可以藉由Null的輔助判斷出這個字詞長怎樣,即使他聽到的單字在之前的Training data中沒有出現過,藉由CTC也有可能將其辨識出來。Btw, 這個技術也在google translate中全面套用了。
當I/O都是sequence且兩個sequence長度沒有一定關係時,問題會變成非常複雜。但偏偏很多很好用的東西就是RNN的many to many(no limitation)類別QQ
當我要把一段英文翻譯成中文時,我們並不知道翻譯前後兩個sequence的長度,而這就是這個類別最好的例子。以翻譯"Machine Learning"時大概的流程會長這樣:
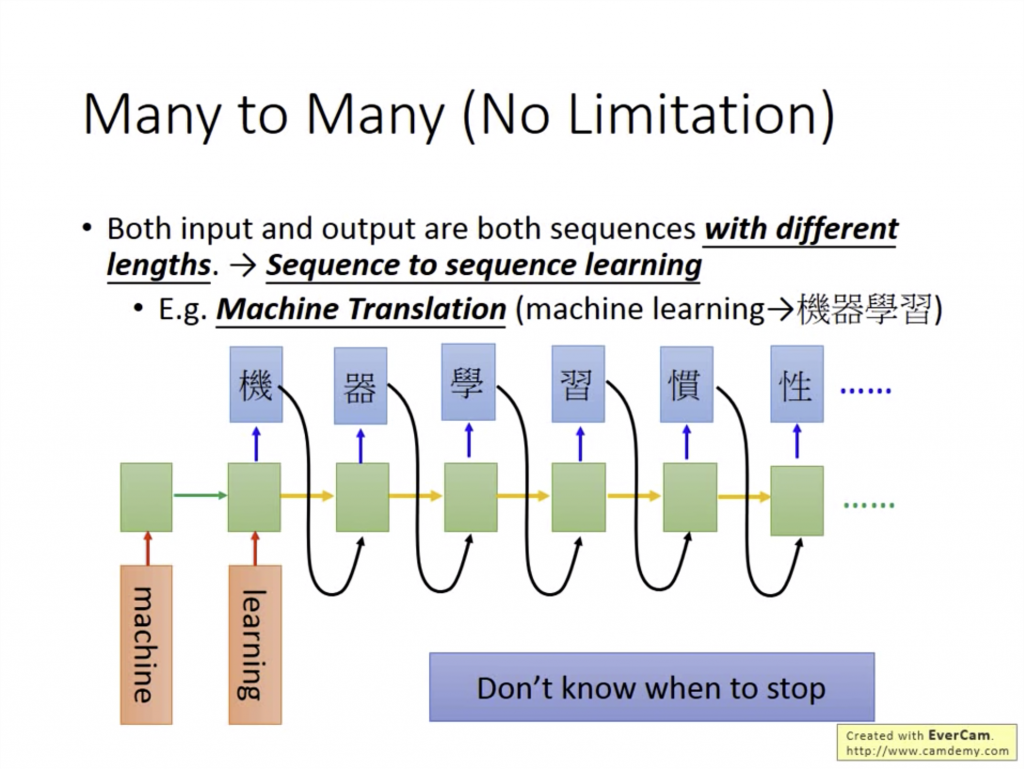
當所有Input進去後,Output才會一個一個吐出來,當「機」「器」「學」「習」四個字成功吐出來後,因為模型沒有什麼時候要停下來的資訊會導致會一直輸出到電腦掛掉qwq。
STORY TIME
鄉民的神奇信仰:
這個邪教儀式輕則三日重則七日,
只要持續拜、功德金持續納,慈姑觀音一定會幫你斷:
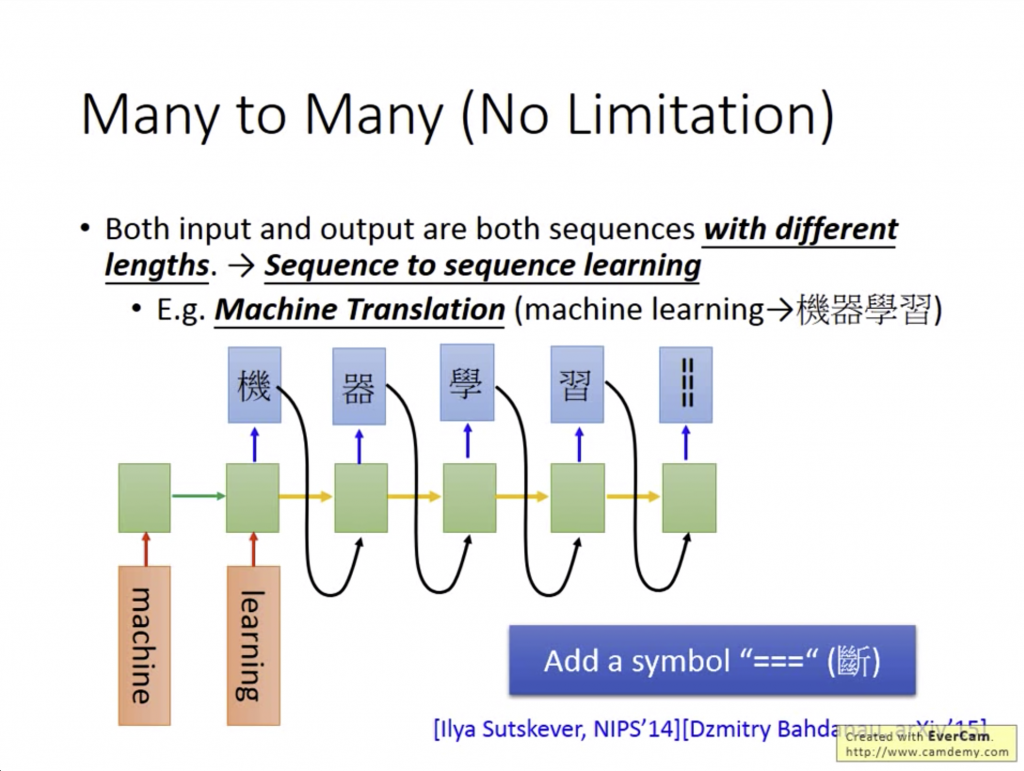
所以一樣,必須要引入「斷」這個symble,讓Training的時候知道要斷在哪裡:
Google在2016年12月釋出一個想法,Input sequence是一個聲音檔案,Output sequence是翻譯的文字。

這可以應用到台語翻譯:因為台語發展的一開始並沒有文字,為了教學方便才硬把他變成國字和羅馬拼音。如果利用這個方法,訓練資料只需要搜集台語發音和中文文字就好了www




 iThome鐵人賽
iThome鐵人賽