昨天的內容我們學會了將匹配的結果繪製出來,
並透過遮罩只繪製出我們想要保留的部分,
而今天的內容則是想要說說,要怎麼選擇那些我們想保留的部分?
std::sort(match_result_with_crosscheck.begin(), match_result_with_crosscheck.end());
之前的內容中有提到,我們把差異的程度排序一下,
透過計算最小與最大的差異,只取可能前60%或是前20組的匹配,
這可能是比較粗略的過濾法,
而openCV在BFmatch裡面有設計了一個參數,
當我們在建構這個匹配器的時候,除了選擇適合計算描述符距離的演算法,
也可以透過第二個參數來控制匹配器要不要做cross_check,
cv::Ptr < cv::BFMatcher> match_description = cv::BFMatcher::create(cv::NORM_L2,true);
我建立了兩個匹配器一個有做cross_check,一個沒有。
而我都只將距離作排序選擇輸出前20組匹配結果。
第一張是沒有做cross check的結果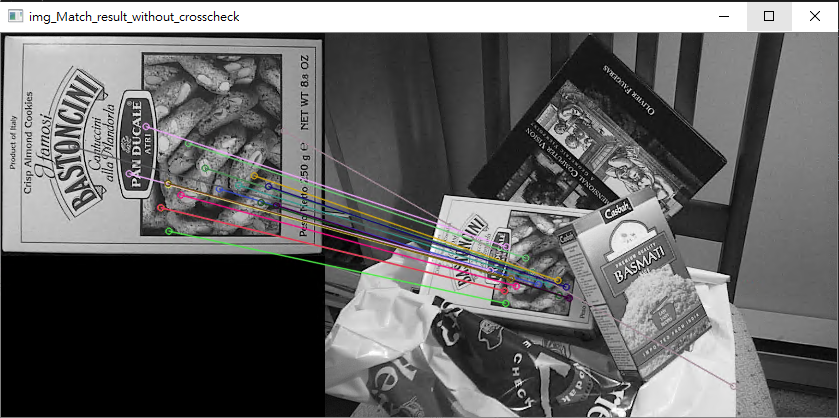
第二張則是有做cross check的結果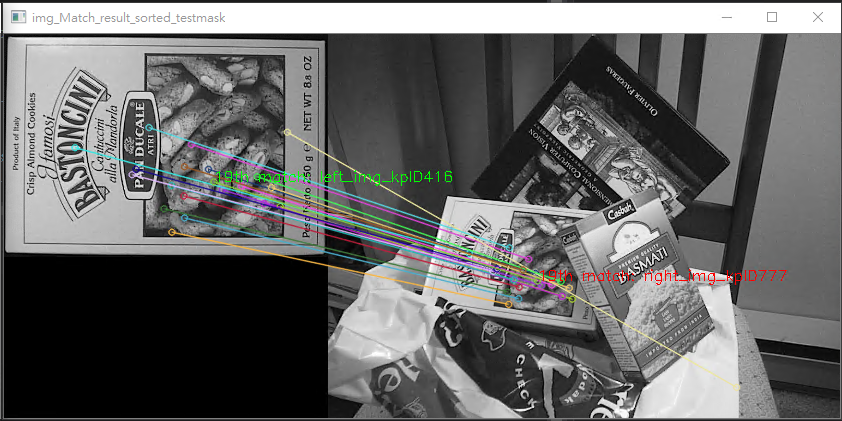
你如果很細心的玩大家來找碴,你也許會注意到,
沒有做cross_check的在某些地方可能會有兩組匹配在很相近的位置,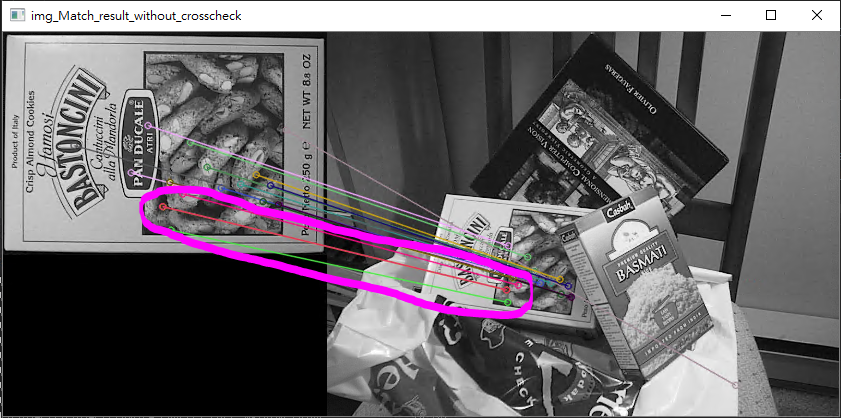
而如果你有接觸一些人工智慧,你也許知道有一種kNN演算法再做分類,openCV也有提供一樣的實作,
我們可以透過這個演算法,來分類好的匹配,跟比較不好的匹配。
而要注意這裡存放結果的地方,就不是單單一層vcetor,
而是vector再包了一層vector。
std::vector < std::vector< cv::DMatch >> knn_match_result;
match_description2->knnMatch(descript_of_box, descript_of_scene, knn_match_result,10);
而這裡你可以選擇Brute-force暴力匹配的匹配器來做kNN,
也可以選擇另外一個DescriptorMatche,Flann-based,
Fast Libary for Approximate Nearest Neighbors,在做kNN的時候
如果你的數據很大,那麼在執行的效率上可能會比BF要來的有效率,
Ptr<DescriptorMatcher> matcher = DescriptorMatcher::create(DescriptorMatcher::FLANNBASED);
而你可以利用這個knn來做一些你想要做的事情,
這邊就只簡單得做個ratio_test,來區分好壞
const float ratio_thresh = 0.7f;
std::vector<cv::DMatch> good_matches;
for (size_t i = 0; i < knn_match_result.size(); i++)
{
if (knn_match_result[i][0].distance < ratio_thresh * knn_match_result[i][1].distance)
{
good_matches.push_back(knn_match_result[i][0]);
}
}
第一層代表了這是第幾個queryDescriptors的匹配結果,
而第二層則是依序排列了跟這個query_index前幾個相近的train_index,
這邊只是單純比較第一跟第二的距離比值(或是說最近跟次要近的距離比值)
,如果比值小於閥值(ratio_thresh),
代表這組匹配沒有模稜兩可的匹配,那麼這組匹配可能是個優良的匹配,而這邊我只利用到了最近與次要近的部分,所以我的kNN當初設定是前10個近的也許只需要設定為2
那我就可以將這組匹配另外塞進good_matches裡面存放結果。(所以這邊不需要mask做遮罩)
而最後我們再將這些好的匹配繪製出來。
cv::Mat img_Match_Knn_ratio;
cv::drawMatches(image01, SURFkeypoints_ofbox, image02, SURFkeypoints_ofscene, good_matches, img_Match_Knn_ratio, cv::Scalar::all(-1), cv::Scalar::all(-1), std::vector<char>(), cv::DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
cv::imshow("img_Match_Knn_ratio", img_Match_Knn_ratio);
其結果如下
而未來也許會再補充RANSAC。

