資料降維其實對於分類計算還蠻用的,所以這一篇來講一下我們怎麼降低資料維度然後達到提升分類正確率提升。資料降維這個動作也可以被稱為特徵選取 (feature selection),以下我們都會使用『特徵選取』這個名稱來代表資料降維。
一樣的,我們直接用 Weka 上提供的工具來做。
在 Weka 先載入資料後,選取 “Select attributes” 後會跳出 Attribute Evaluator,然後點擊你要使用的 特徵選取 方法即可。
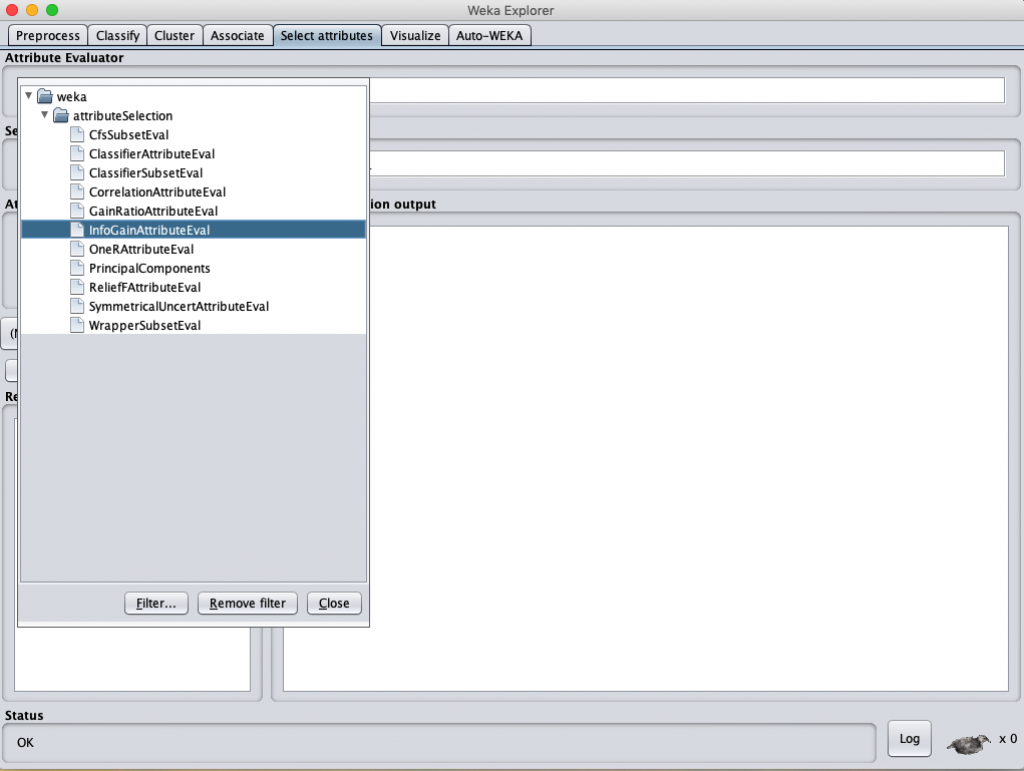
這邊有很多評估 attribute 的計算方式,操作方式可以直接參考這一篇說明以及註 1 的 paper 說明。
https://machinelearningmastery.com/perform-feature-selection-machine-learning-data-weka/
我們直接選了兩個 attribute selection :
這兩個都是針對個別 attributes 計算各自在資料及內的權重值,決策樹在建立節點時就是依據 IG 的 entropy 來判別可以區分出不同類別資料的最大差異。
因為在 Day 27:第三招 資料面改善 的實驗中發現使用 TF-IDF 的資料集得到比較好的結果,因此我們這邊繼續利用此資料集來進行特徵選取的動作。
依據上述特徵選取方式,利用 Information Gain 選出來的特徵可以參考這裡:
https://github.com/deternan/PTT_Stock/blob/master/source/feature%20selection/InfoGainAttributeEval_tfidf.txt
而利用 GainRation 選出來的特徵可以參考這裡:
https://github.com/deternan/PTT_Stock/blob/master/source/feature%20selection/GainRatioAttributeEval_tfidf.txt
從計算出的結果可以發現,每個 attribute (feature) 都會有一個數值 (也有可能為 0),我們就直接採用大於 0 的 feature 來重新組成一個新的資料集。
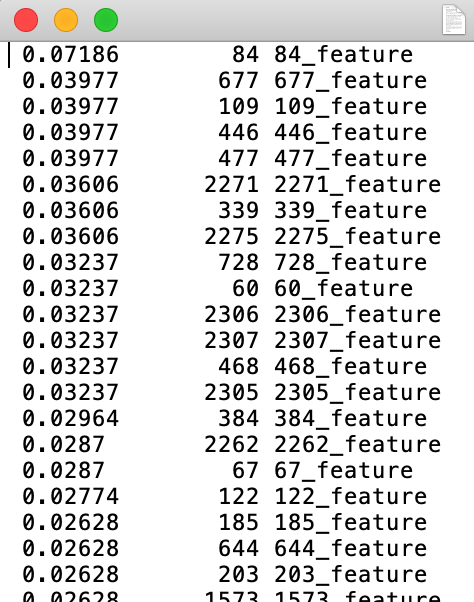
例如上述這個由 Information Gain 計算出的特徵分數,第 84 個特徵 等大於 0 的特徵會被從原始的 TF-IDF 資料集中組成,然而分數為 0 的就不採用,也因此達到“特徵選取”的這個動作。
讀取原始由文章產生出的 TF-IDF 檔之後再讀入特定的特徵編號,重新組成新檔案的轉檔程式可以從這邊下載,也是要記得要修正一下你自己存放相關位置的位址就是了。
https://github.com/deternan/PTT_Stock/blob/master/src/main/java/FeatureSelection/Arff_Translation.java
經過轉檔後的資料集如下:
經過 Information Gain 選出了58 個 attributes
Information Gain:
https://github.com/deternan/PTT_Stock/blob/master/source/tagging_tfidf_fs_ig.arff
而 GainRatio 也是選出了58 個 attributes
GainRation:
https://github.com/deternan/PTT_Stock/blob/master/source/tagging_tfidf_fs_gr.arff
好,那現在就有了兩個新的資料集,接下來就是丟入分類器再去計算一次,看看是否真的能改善分類成效?
針對 Information Gain 選出的 58 個 attributes 來進行分類計算結果依序如下
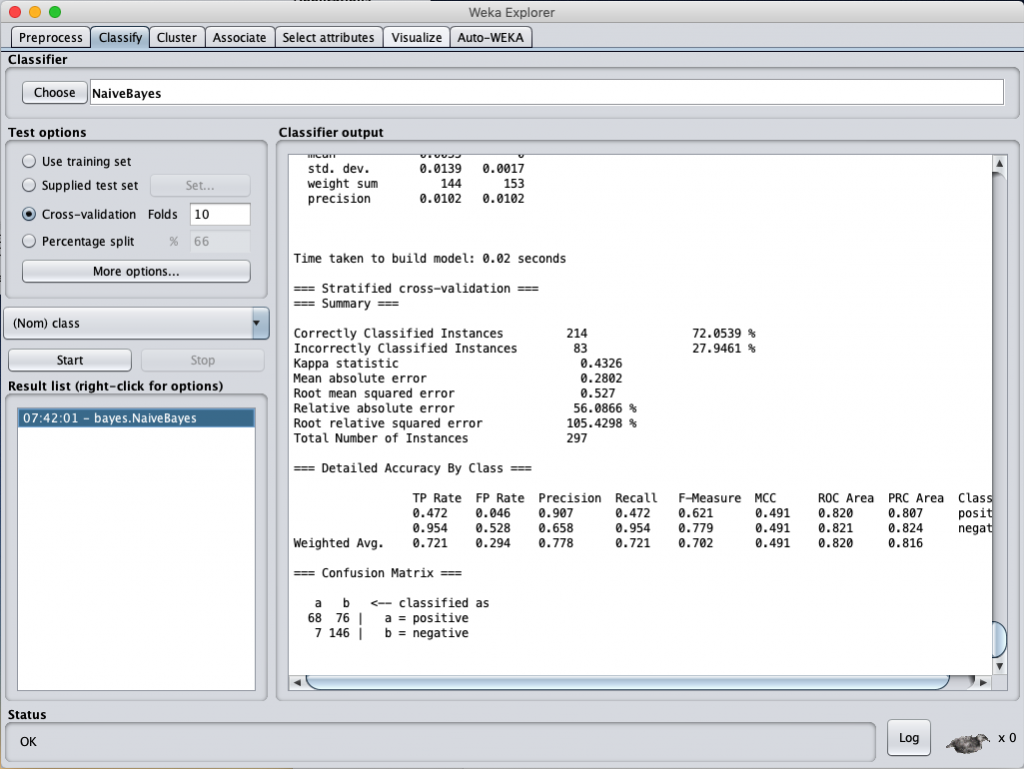
Naïve-Bayes classification accuracy (selected by Information Gain)
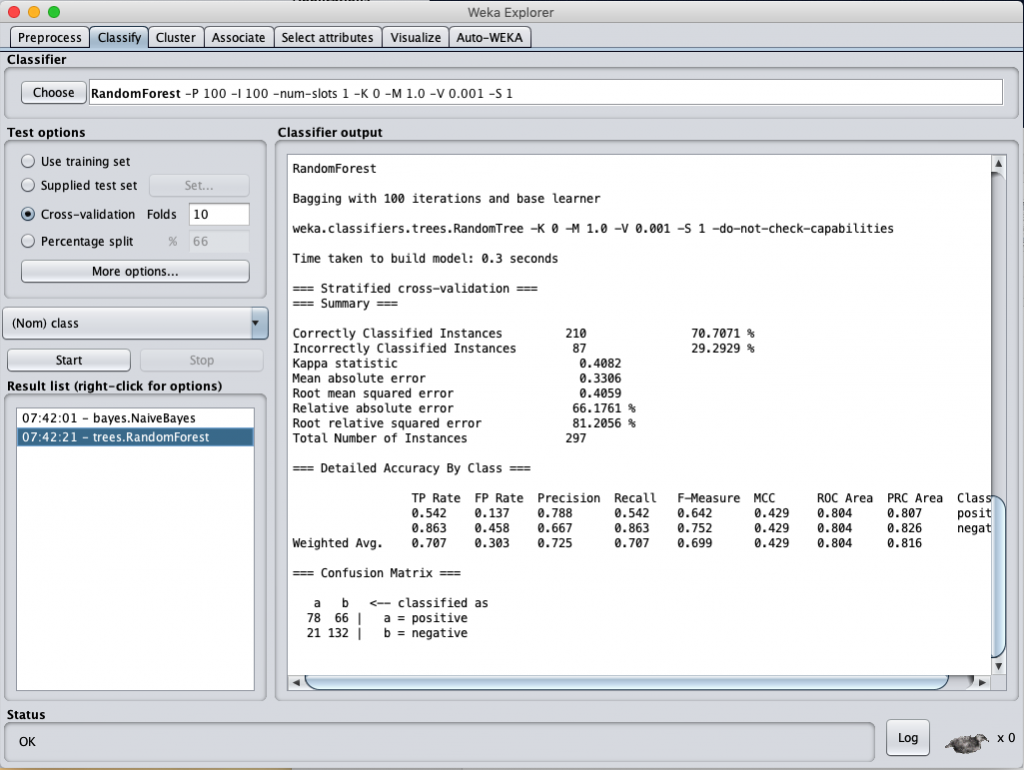
Random Forest classification accuracy (selected by Information Gain)
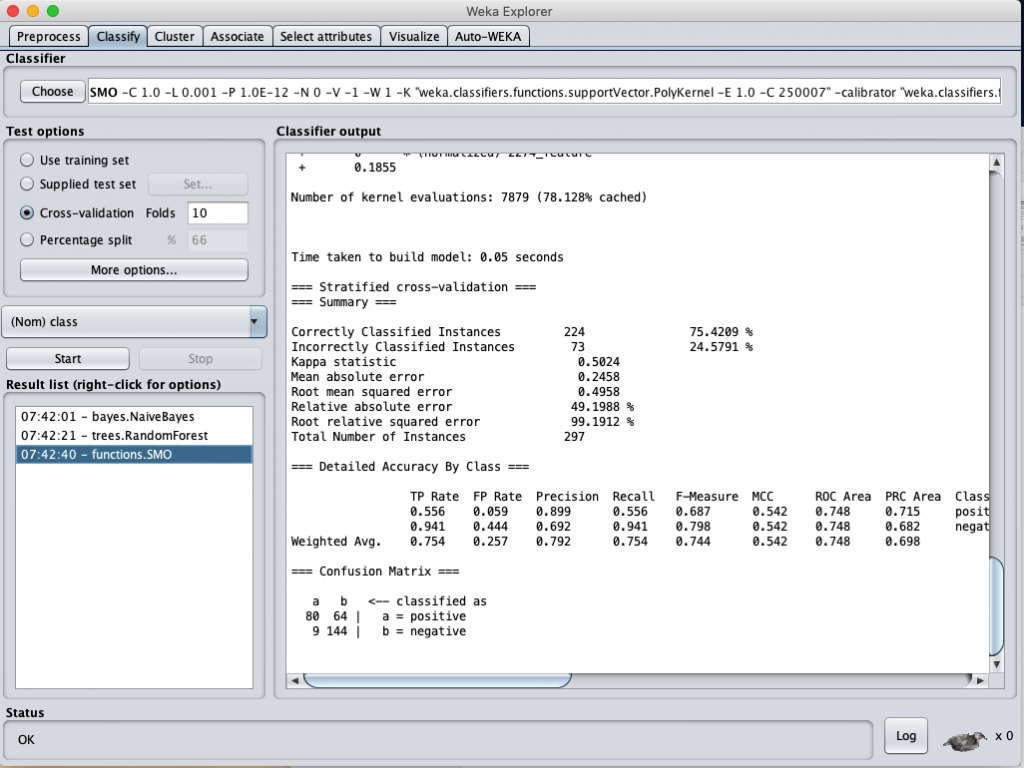
SVM classification accuracy (selected by Information Gain)
而利用 GainRatio 選出的 58 個 attributes 來進行分類計算結果依序如下
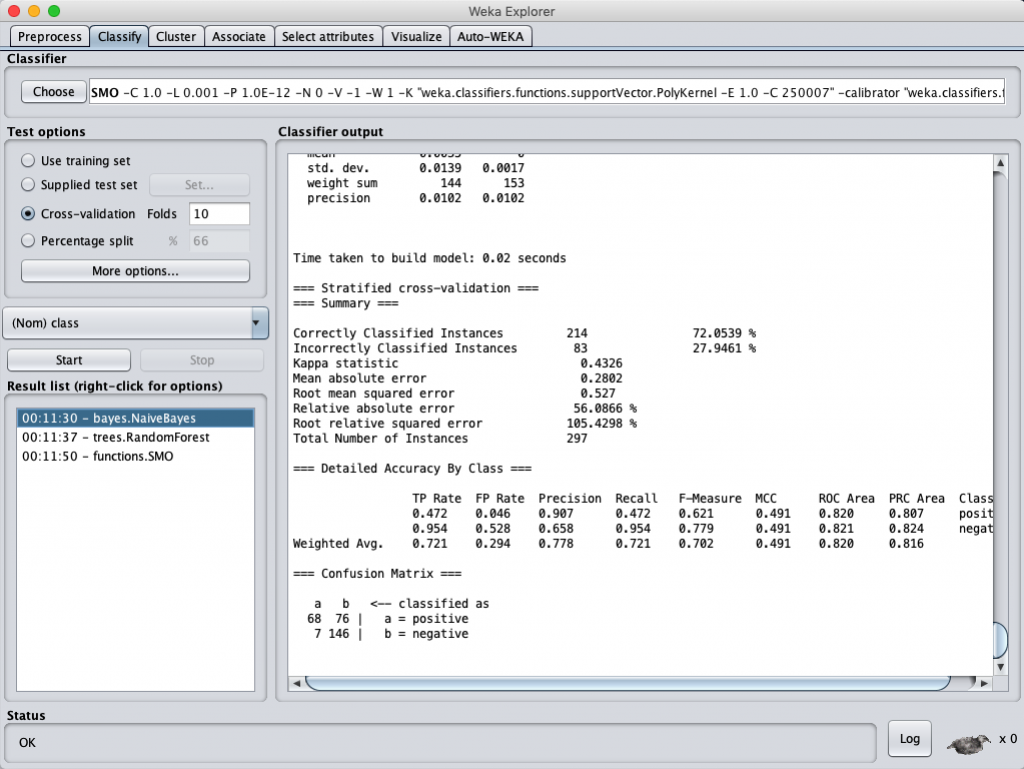
Naïve-Bayes classification accuracy (selected by GainRation)
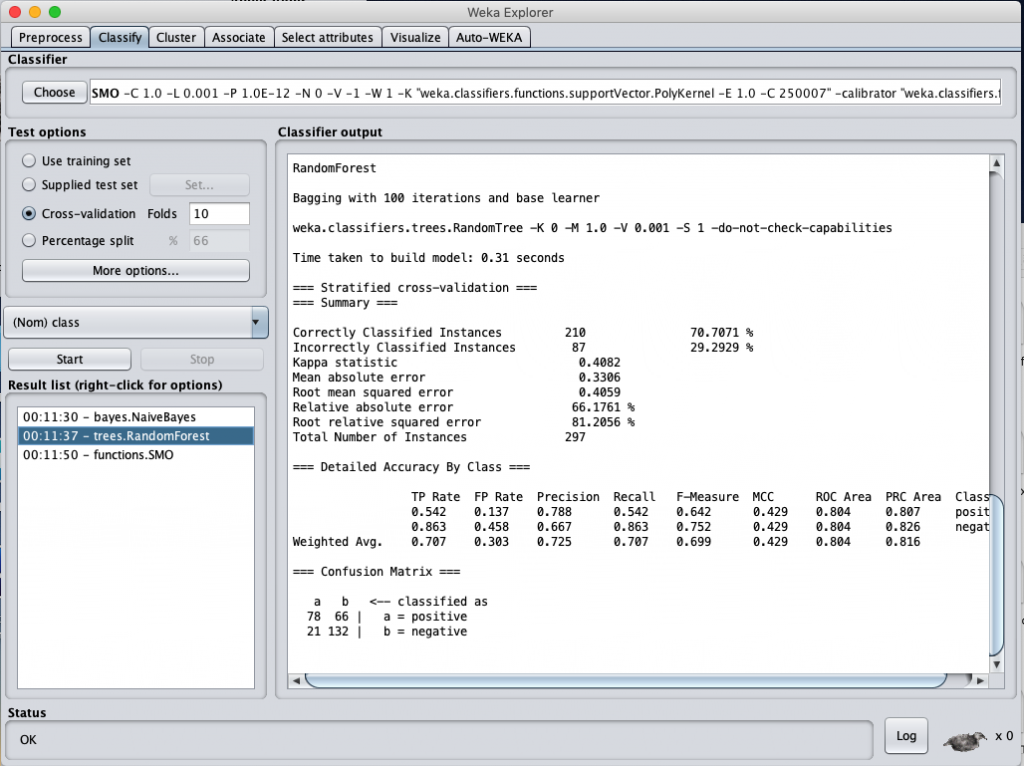
Random Forest classification accuracy (selected by GainRation)
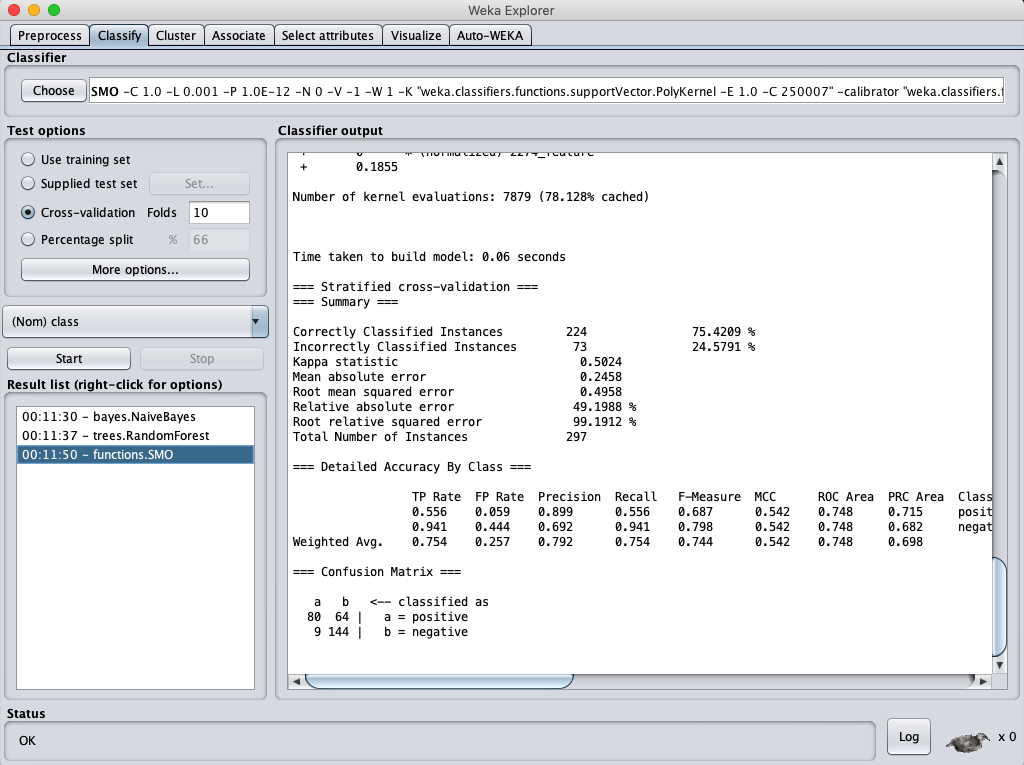
SVM classification accuracy (selected by GainRatio)
來做個總結的表格,這樣看比較方便:

從上表可以看得出來,經過 feature selection 選出的 attributes 再進行分類計算,得到的正確率都比沒經過 feature selection 的正確率要該出將近 20 %,看來把維度降低再計算還蠻有用的。
但比較特別的是,不管是經過 InformationGain 或是 GainRatio 選出的 58 個 attributes 再進行分類計算幾乎得到相同的結果。這一度讓我懷疑是不是我跑錯資料了?但進去看了一下資料集,發現兩個選出的特徵完全一模一樣,只是每個 attributes 的分數不同而已。那也難怪計算出來的結果會一樣,因為資料集根本完全一樣。如果真的要區別出兩個各自的 feature selection 功效,或許不能把 attribue score 只定為 0,或許要設一個門檻值 (threshold)可能比較有用。
好的,那有關分類正確率的改善就在這邊告一段落了,明天再來把全部的改善方式做個比較與總結了。
註 1 :
https://oaji.net/articles/2017/2698-1528114152.pdf
註 2 :
https://arxiv.org/ftp/arxiv/papers/1612/1612.08669.pdf
免責聲明:本文章提到的股市指數與說明皆為他人撰寫文章內容,包括:選股條件,買入條件,賣出條件和風險控制參數,只適用於文章內的解釋與說明,此提示及建議內容僅供參考之用,並不構成投資研究、認購、招攬或邀約任何人士投資任何投資產品或交易策略,亦不應視為投資建議。

