上一篇想辦法去改善分類演算法但似乎改善幅度不高,正所謂山不轉路轉,如果分類器改善不了,那何不來改善一下資料面的問題呢?
針對資料的部分我們會用以下三種方式重新處理一下資料集,其中用兩個不同的方式重新把文字轉向量,最後是加入正規化的部分。方法依序是:
以下會針對這三個方式一一講解,之後再把重新編碼後的數值再進行一次分類計算,以便比較是否不同的編碼方式可以改善分類演算法?
為了公平起見,依然還是採用原先標記好的資料再來進行文字轉字詞
https://github.com/deternan/PTT_Stock/blob/master/source/tagging.txt
TF-IDF
有關 TF-IDF 的簡介可以直接連到 Wiki 的介紹,這邊就不多說了。
https://zh.wikipedia.org/wiki/Tf-idf
主要公式如下,而原本公式上 documents 的數量就是原始資料 instances 的數量。
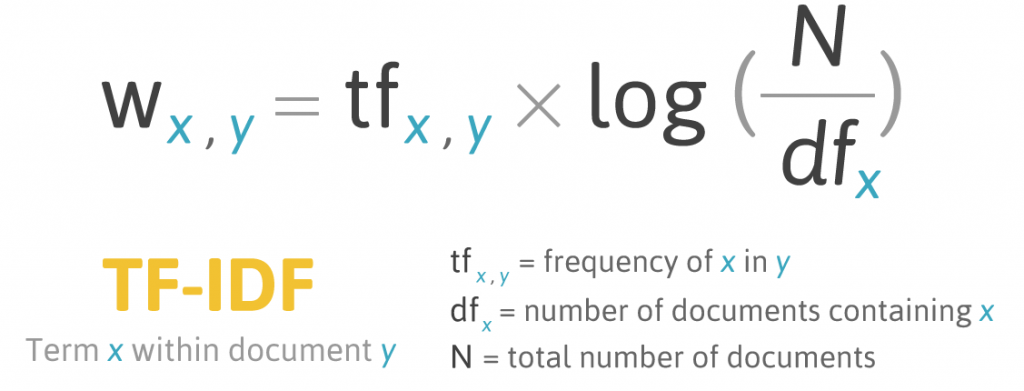
把文章轉成 TF-IDF 向量的程式碼可以從這逼邊下載:
https://github.com/deternan/PTT_Stock/tree/master/src/main/java/ptt/tf/idf
所以的變數存放在 Parameter 類別裡,如果要自行轉檔的話記得要換成自己的路徑。然後執行 TfIdfMain.java 類別即可。
轉換後的向量檔也可以從這邊下載:
https://github.com/deternan/PTT_Stock/blob/master/source/tagging_tfidf.arff
我們同樣測試之前提到的三個分類演算法,用此資料集來進行分類計算,得到的結果分別是:
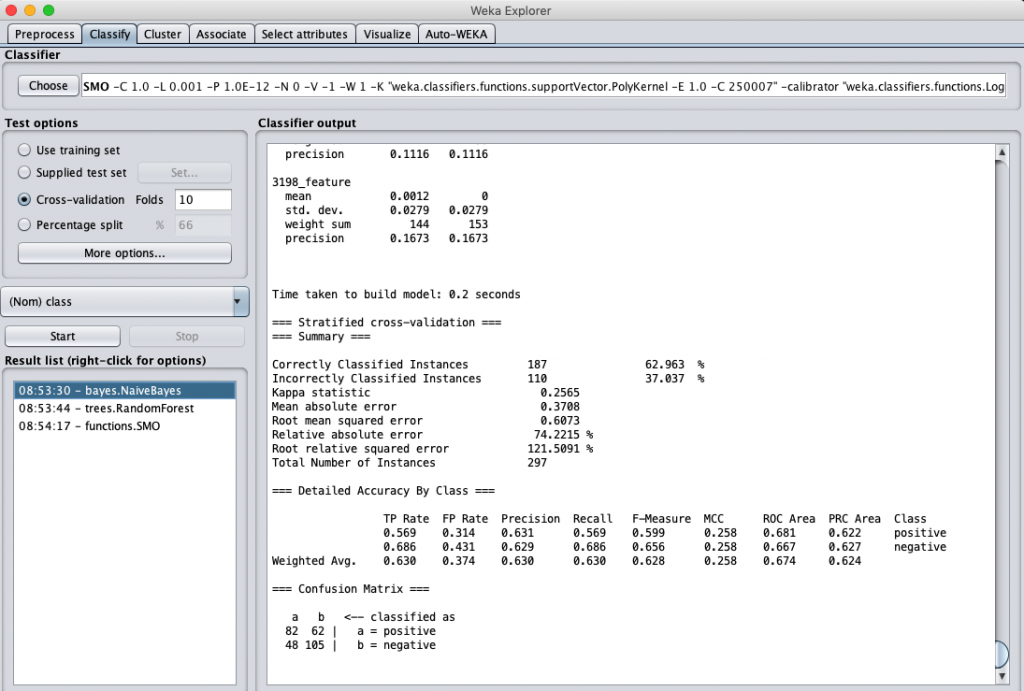
Naïve-Bayes classification accuracy
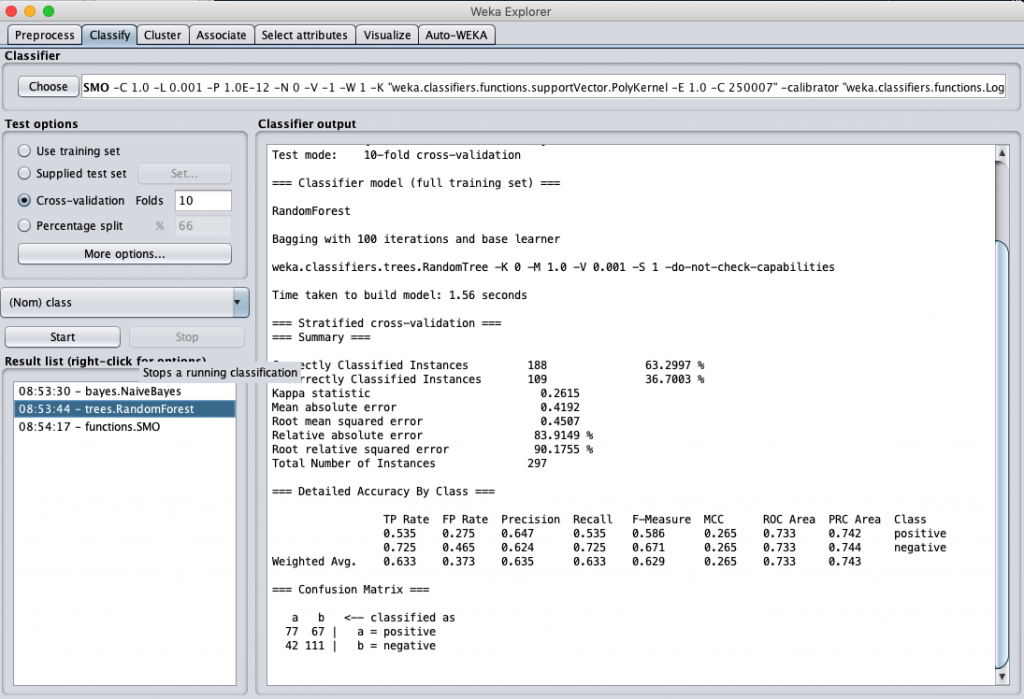
Random Forest classification accuracy
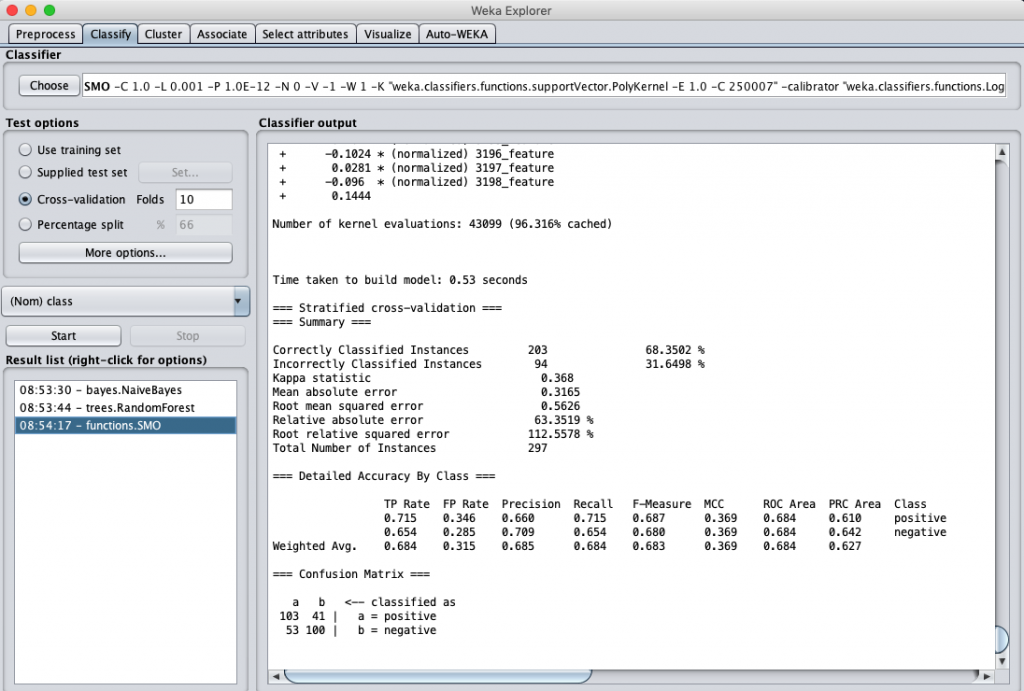
SVM classification accuracy
誒 … 結果好像有變好耶 !! ?
不錯 不錯 ~
word2vec model
我們原本將文字轉向量值是使用 fasttext 進行 (model也是)。這邊想嘗試看看如果使用 Google 的 word2vec 進行轉換,然後再來進行分類計算,看看結果是否可以改善?
利用 word2vec 轉向量值的 code 也幫大家準備好了,可以直接從下方網址,不過自己要記得改 model 位置就是了。
https://github.com/deternan/PTT_Stock/blob/master/src/main/java/ptt/arff/TaggingData_to_Arff_Word2Vec.java
轉換後的向量檔也可以從這邊下載,下載後也可以直接在 Weka 上執行。
https://github.com/deternan/PTT_Stock/blob/master/source/tagging_word2vec_txt.arff
一樣用 Weka 跑三個分類演算法,得到的結果分別是:
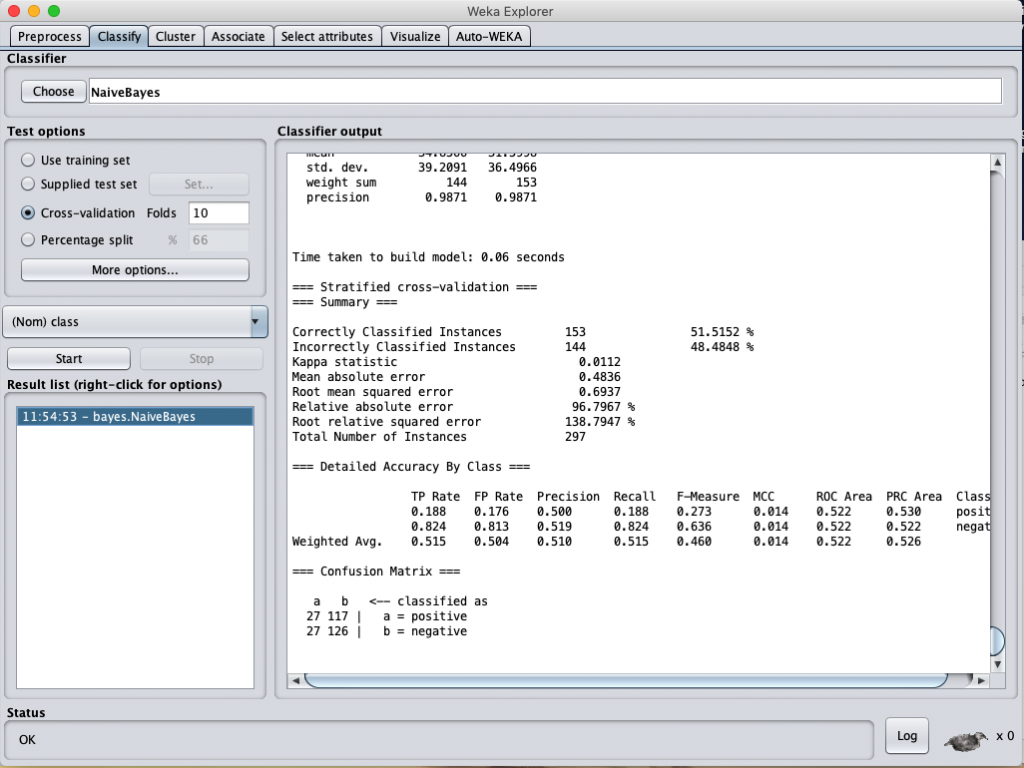
Naïve-Bayes classification accuracy
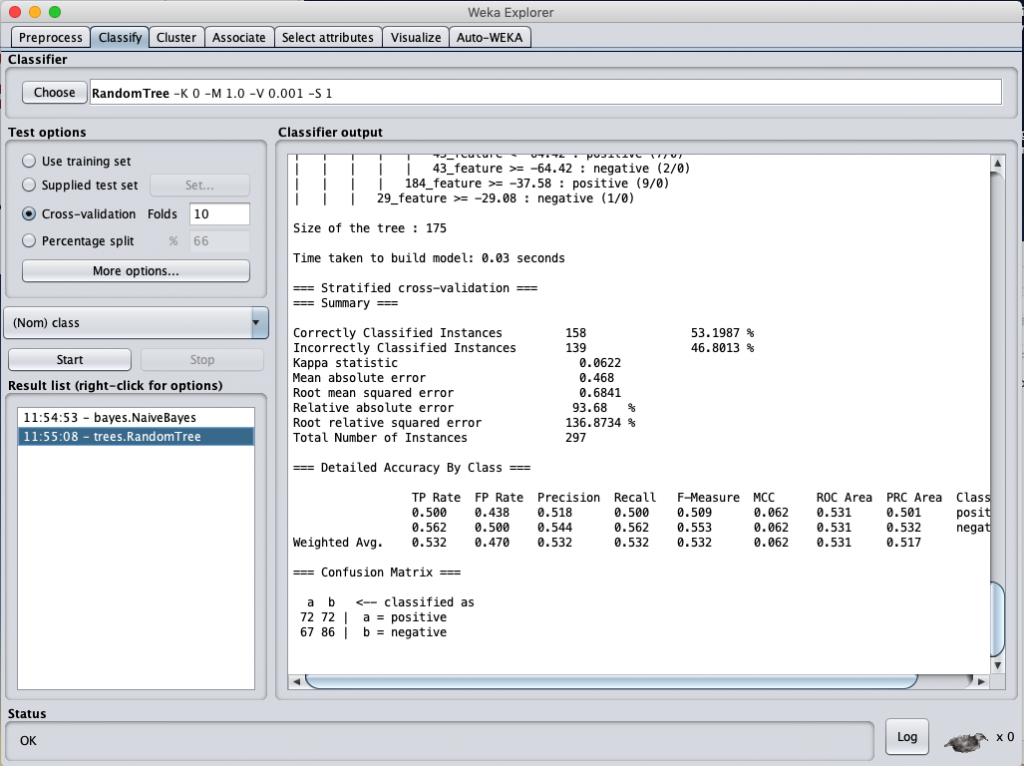
Random Forest classification accuracy
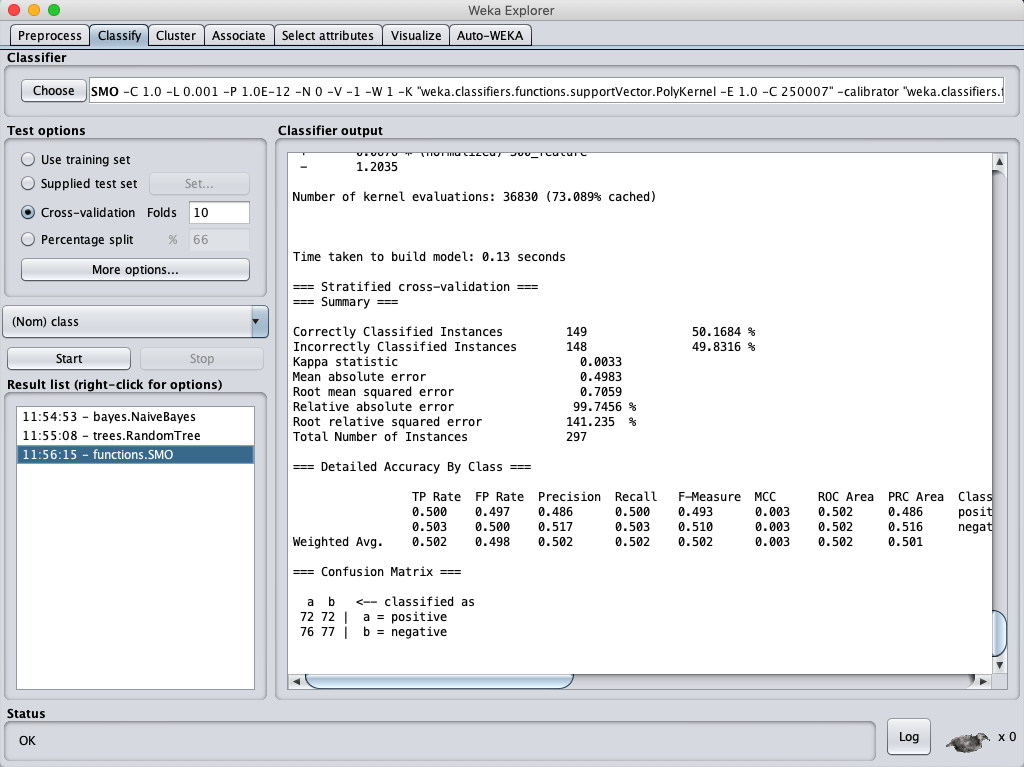
SVM classification accuracy
結論:好像沒有比較好,怎麼反而好像更低了 ?
Normalization
為了讓資料的標準差不至於過大,通常在進分類等數學計算時資料都會先進行前處理的動作,最常見的就是 data normalization (資料正規化)了。資料正規化是將資料個數值的大小經過一些計算(例如:Standard Score)來將資料數值限縮在一定範圍內,通常範圍會定在 0 至 1 或是 -1 至 1 之間。
在 Weka 也可以先針對資料進行正規化,讀入檔案後進行分類計算前,只要在 Filter 中依照 “weka” → “filters” → “unsupervised” → “attribute” 選擇 『Normalization』
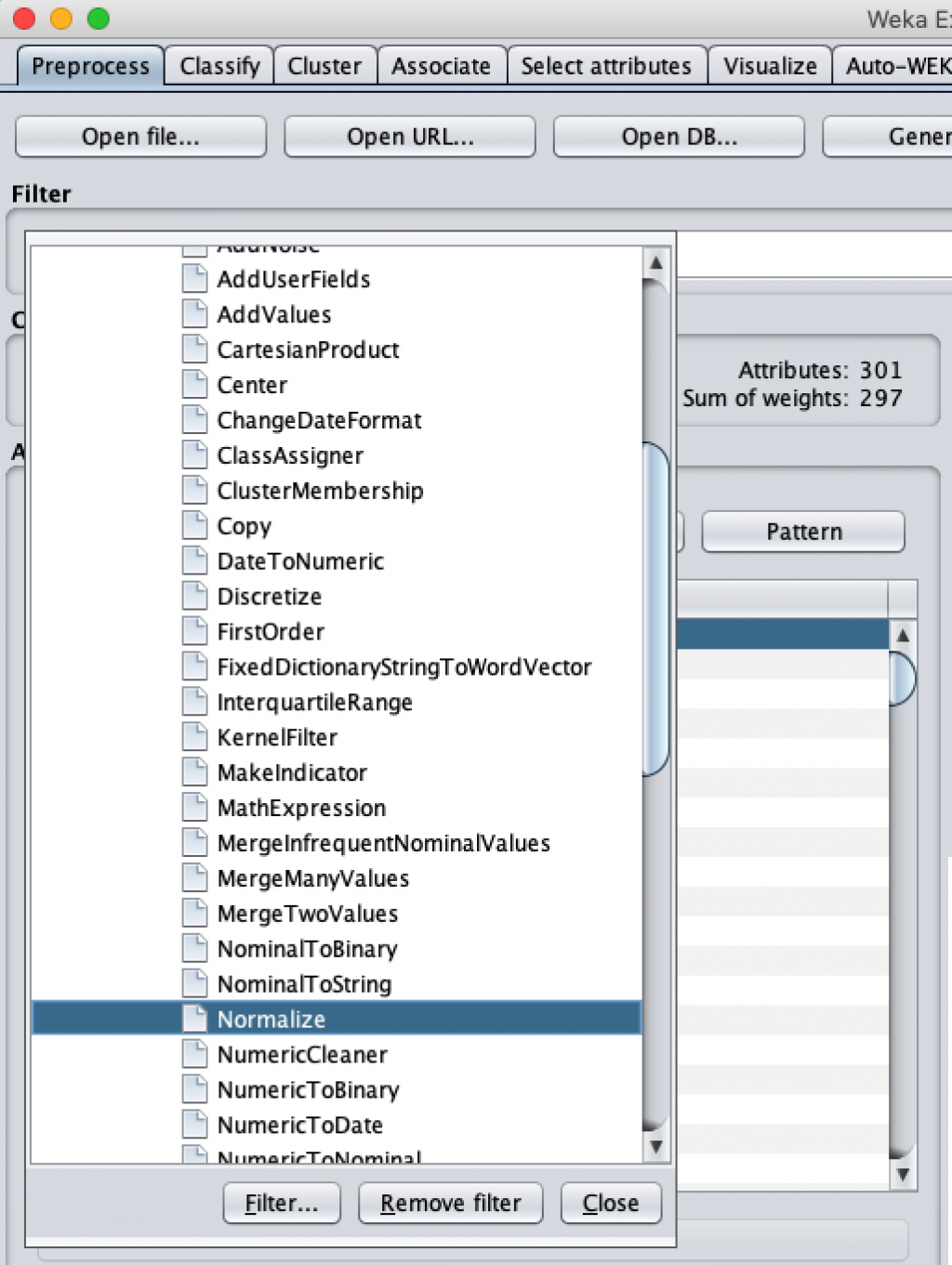
然後會看到指令列上出現了 將數值限縮在 0 至 1 的範圍
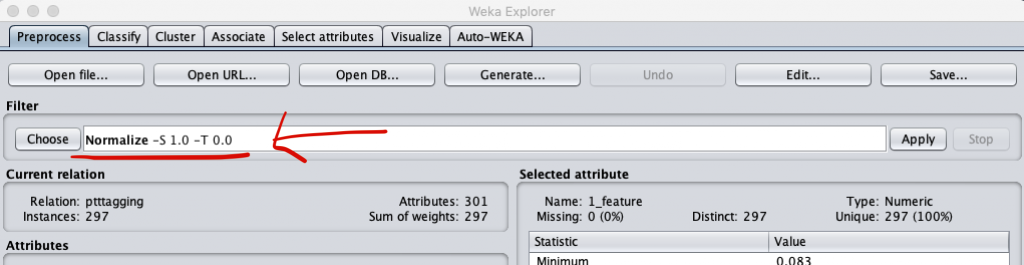
之後再執行各分類(或其他)計算時,原本讀入的資料都會被先正規劃後才載入各演算法內。
同樣的,我們也是用三個演算法來跑一下正規劃後的資料,而資料 model 是採取 fasttext 轉換後的數值。得到的結果依序如下
一樣用 Weka 跑三個分類演算法,得到的結果分別是:
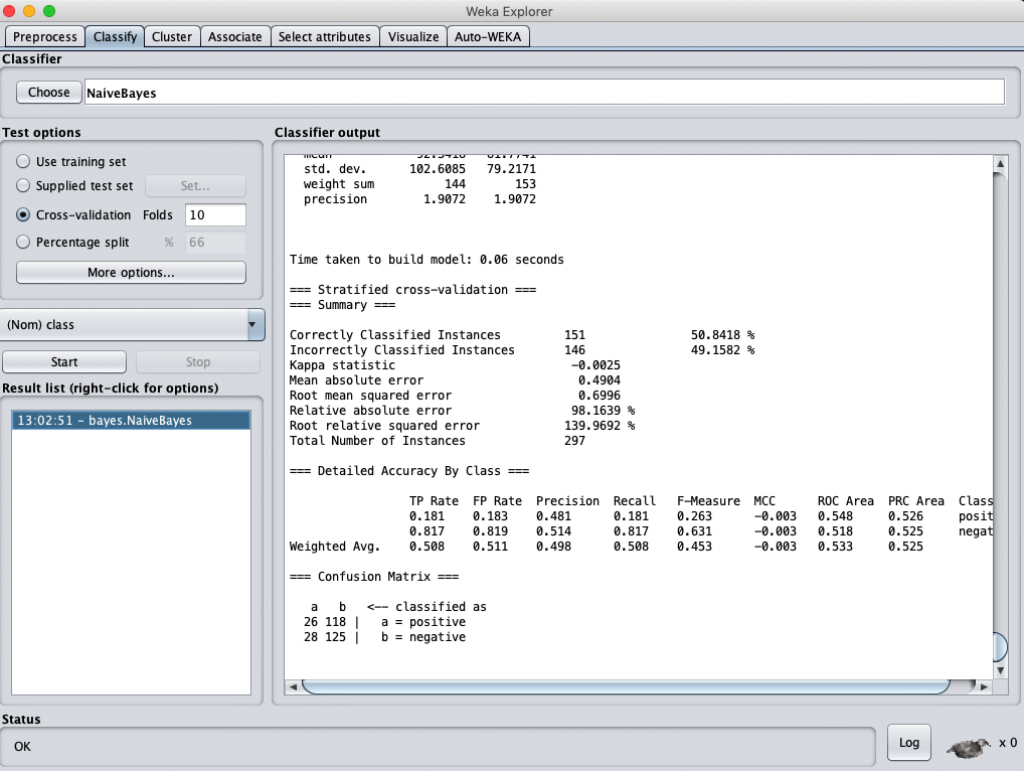
Naïve-Bayes classification accuracy (data normalization)
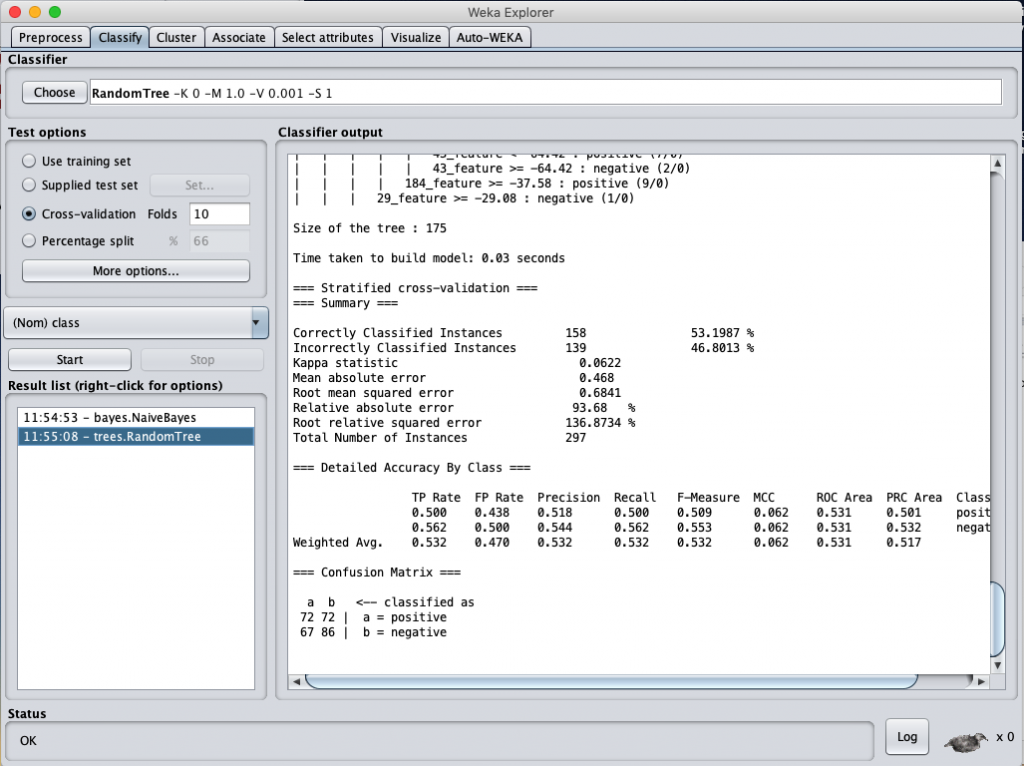
Random Forest classification accuracy (data normalization)
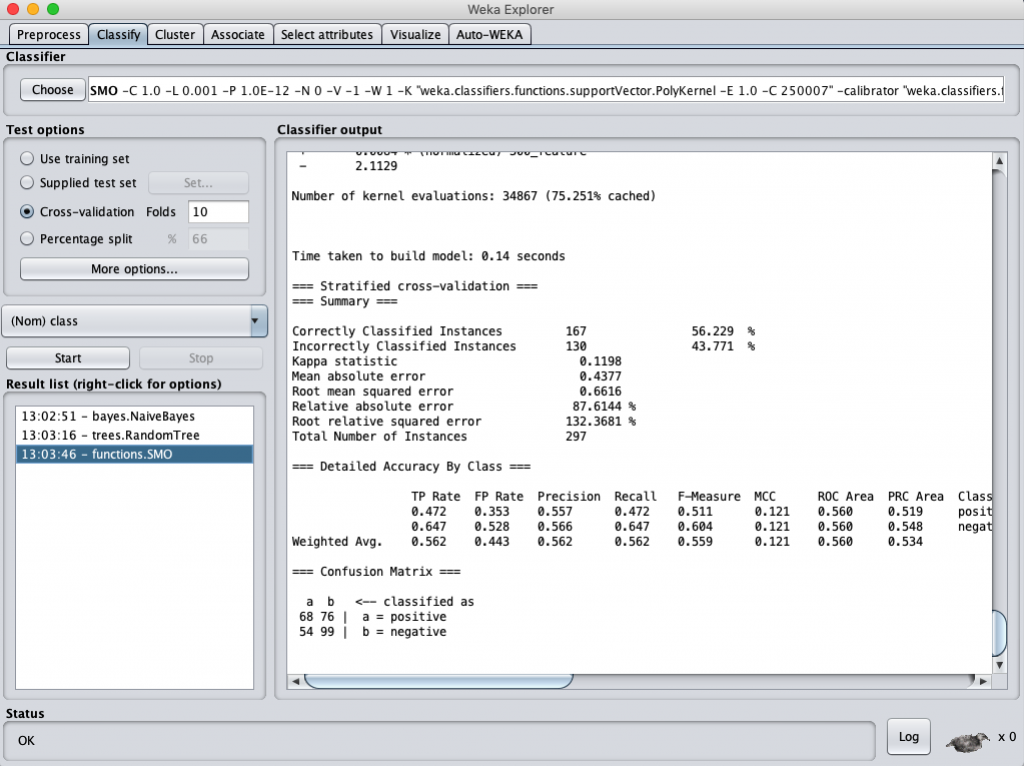
SVM classification accuracy (data normalization)
依序跑完了三個我們假設可能的改善方式,這裡一下這三個方式各自又使用分類演算法得到的結果如下表:

從數據看起來用了 TF-IDF 的編碼方式反而得到了最好的分類結果,或許這也算是給了我們一條未來如何改善的一個明燈吧。


