今天會開始進入另一個用於機器學習的函式庫-keras,它更是為了深度學習創建的!今天會介紹基本的keras應用帶大家做一些基礎的練習!
在這裡也要先跟有在關注我的朋友們說聲抱歉,最近學校的事情實在是太多了,我也沒有存明天、後天的文章,都是當天花3~4小時去整理的,那我會在這周末把自己整頓好,並且花更多時間在這上面的!我也會努力保持著一篇文章該有的質量!還請你們繼續關注!

圖片來源
昨天有提到keras是一個深度學習的開源函式庫,它Keras開發的重點就是支持快速的實驗,它能夠提供簡單而快速的原型設計,意思就是Keras是個高度模組化的函式庫,它可以讓用戶快速的去建造神經網路並訓練模型。
用Tensorflow和keras幾乎都可以做到一模一樣的事情,但我認為在實作Tensorflow時,會比較了解自己在幹嘛,而Keras相較Tensorflow比較簡單快速建造,然而,也是因為太過方便而造成比較不靈活的狀況發生。但也是因為Keras建造簡單,可以大大降低初學者進入深度學習的門檻!
那因為keras建置簡單,我會以實例的方式向大家介紹比較基礎、重要的指令,開始!
from keras.models import Sequential #引入Sequential函式
model = Sequential()
那,Sequential()是啥玩意呢?Sequential()就是我們定義模型的開始,在上面有提到,Keras常用來做深度學習,昨天也有說到深度學習的第一步就是建構神經網路架構,那麼我們就是要靠Sequential()進行建造網路架構,常用的方法以下有兩種:
1.直接在Sequential()裡面定義層數、激勵函數:
from keras.models import Sequential #引入Sequential函式
from keras.layers import Dense, Activation #引入層數及激勵函數
model = Sequential([
Dense(512, input_shape=(784,)),
#Dense:全連接層
#輸入的張量,784神經元(或稱組數輸入)
#512是輸出的神經元數量(或稱組數)
Activation('relu'), #設定激活層並採用relu
])
print(model.summary()) #顯示目前網路架構
輸出:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_17 (Dense) (None, 512) 401920
_________________________________________________________________
activation_16 (Activation) (None, 512) 0
=================================================================
Total params: 401,920
Trainable params: 401,920
Non-trainable params: 0
_________________________________________________________________
None
2.用add疊加上去
from keras.models import Sequential #引入Sequential函式
from keras.layers import Dense, Activation #引入層數及激勵函數
model = Sequential() #定義模型
model.add(Dense(512,input_shape=(784,))) #加入神經層第一層(輸入784)輸出512
model.add(Activation('relu')) #激勵層
print(model.summary()) #顯示架構
輸出:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_18 (Dense) (None, 512) 401920
_________________________________________________________________
activation_17 (Activation) (None, 512) 0
=================================================================
Total params: 401,920
Trainable params: 401,920
Non-trainable params: 0
_________________________________________________________________
None
那什麼是Param呢?就是參數的意思,也就是每層神經元的權重(w)個數。
怎麼算出來的?Param = (輸入維度+1) * 輸出的神經元個數,但是每個神經元都要考慮到有一個Bias,所以要再加上1。
來算一下上面的,(784 + 1) * 512 = 401,920
下圖JOHN國的房價,JOHN國的房價很簡單,只受到坪數大小的影響。
id | price | sqft_living
------------- | ----------
1 | 500000 | 55
2 | 275000 | 27
3 | 360000 | 33
4 | 780000 | 70
5 | 145000 | 13
6 | 280000 | 26
7 | 860000 | 89
8 | 200000 | 21
9 | 90000 | 10
10 | 680000 | 67
上code:
from keras.models import Sequential
from keras.layers import Dense
from keras import optimizers
model = Sequential()
model.add(Dense(1,input_shape=(1,))) #加入神經層第一層(1維)輸出1維(因為資料和輸出都是一維的)
sgd = optimizers.sgd(lr=0.0001)
#sgd是隨機梯度下降法,括號內學習率寫0.0001(資料比較少,過大的學習率會無法找到最佳解)
model.compile(loss = 'mse',optimizer = sgd) #設定model的loss和優化器(分別是MSE和SGD)
model.fit(x_data,y_data,epochs = 200) #1.x資料(坪數)2.y標籤(房價)3.epcohs是指疊代200次
pred = model.predict(x_data) #訓練好model使用predict預測看看在訓練的model跑的回歸線
W, b = model.layers[0].get_weights() #抓出全重和偏差
print('Weights=', W, '\nbiases=', b)
plt.plot(x_data,pred) #畫出回歸線
plt.plot(x_data, y_data, 'o') #畫出原本的點
輸出:
1.剛開始訓練: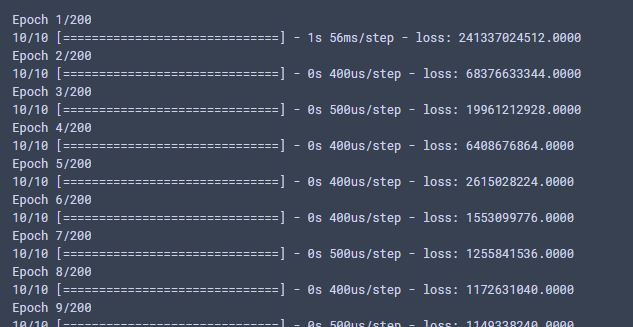
2.訓練結束: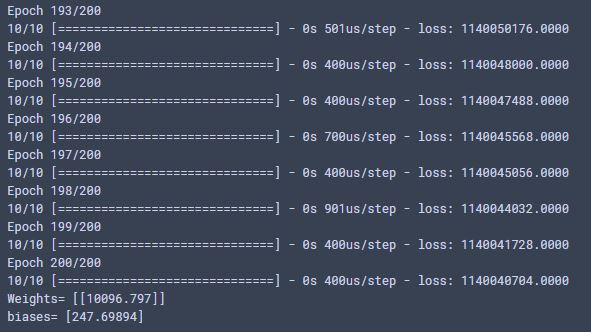
3.輸出圖: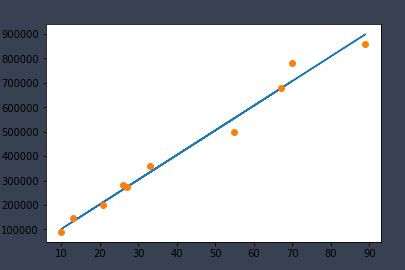
基本上,Keras就是這幾個基礎的步驟,比較重要的就是前面的網路架構和一些參數要再細細討論!
今天把Keras重要的部分介紹完畢了,比較細節的地方會在房價預測一併分享,因為Keras比較好上手,沒有太多的眉角!那明天會先介紹有名的資料科學網站-Kaggle,要繼續關注哦~


 iThome鐵人賽
iThome鐵人賽