昨天已經將自己的model成功訓練完畢了,也看到loss有逐步下降!今天是第29天了,今天要將訓練好的model拿來估計一下測試集,並且預測結果打包成CSV檔上傳至kaggle!
因為我們在做model訓練時,輸入只有相對係數高的那些行,所以如果這時候做測試集時若是輸入不一樣的shape會造成bug的出現,因此有必要也對測試集進行相同的手法!
for i in df_test.columns: #查找原本資料中所有columns
if i not in high_corr:
#如果沒有在訓練時相關係數大於0.6的話就拔掉,因為真正影響房價的不是小於0.6的
df_test = df_test.drop(i,axis=1)
#i是跑過test裡面的columns所有人,axis=1是指定要丟掉"行"
print(df_test) #看一下刪掉相關係數小的人樣子
X_test_dataset = df_test.values #只要數值就好不要dataframe形式
from sklearn import preprocessing
normalize = preprocessing.StandardScaler()
# 標準化處理
X_test_normal_data = normalize.fit_transform(X_test_dataset)
print(X_test_normal_data) #看一下標準化的結果
輸出片段: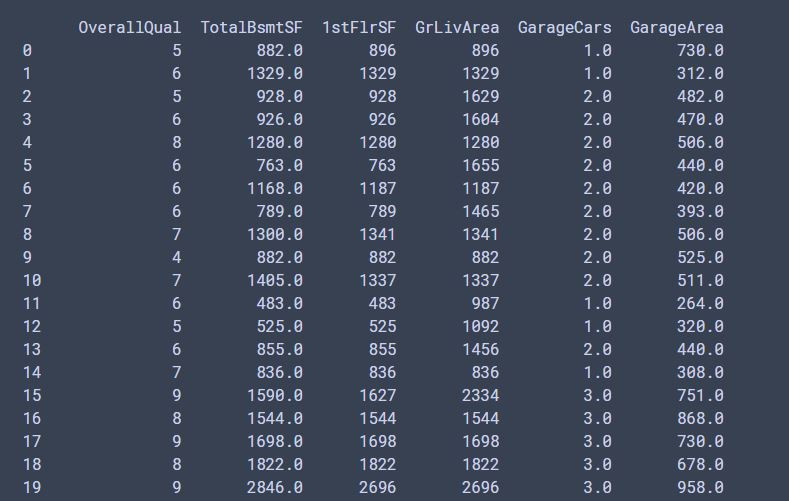
model.load_weights('good.h5') #召喚之前儲存的model
pred = model.predict(X_test_normal_data) #括號內填入要預測的資料
print(pred)
輸出:
[[128880.6 ]
[157887.36 ]
[150417.52 ]
...
[150471.03 ]
[108754.164]
[243079.23 ]]
with open('house_predict.csv', 'w') as f: #開啟一個檔案,house_predict.csv是名字;w是寫入
f.write('id,SalePrice\n') #寫入最上方的列,並用\n往下一列
for i in range(len(pred)): #len(pred)看整個test有多長,然後用for去跑全部
f.write(str(i + 1461) + ',' + str(float(pred[i])) + '\n')
#寫入,這邊特別注意「+1461」,因為它給的sample_submission是從1461開始
#中間加上逗號是因為前面有介紹過csv檔是以逗號為間隔的檔案
#str(float(pred[i]):先把它變成浮點數,再用str()把它變回字串
#後面的'\n'是要換下一列的意思
#注意到中間全部是用「+號」隔開,這是字串的基本招式唷
可以去存放自己py程式碼的資料夾找找,會看到一個csv檔如下:
點選右上Submit Predictions,然後點選下面的紅框框,這樣就可以選你預測好的CSV檔案囉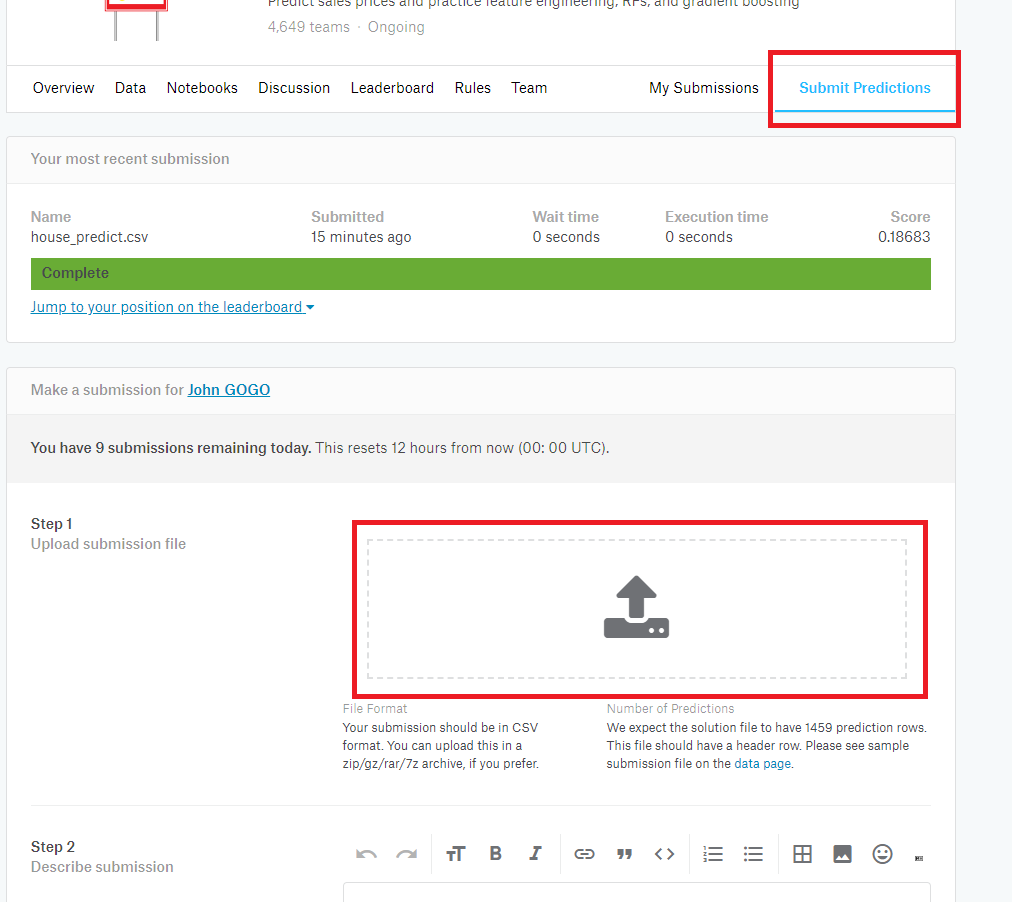
繳交後可以點Leaderboard去看自己和其他人的排名!
那最右邊是你繳交後過了幾分鐘,再來是繳交第幾次(這個比賽一天只能交10次哦)、你的分數(這邊是越低越好哦)!
不過我也只有在3000多名,所以還是有很大的進步空間呢。
終於打到第29天了,明天會做個總結,還有可以從哪個方向去努力試圖讓分數更好!
(DAY27 28還在補充完畢囉!)

