今天是國慶連假第二天,也是我的鐵人賽第26天,讓我們繼續努力!昨天已經把相關係數小的資料們直接丟棄不理,並且從訓練資料中切出20%的資料當作驗證集。今天要將資料進行標準化或是正規化進行處理,這個舉動對我們訓練會有相當大的幫助哦!
因為在行與行(x1和x2)之間可能會有數字上很大的差異,這會對在訓練模型時有不好的影響,就好比x1落在100000~500000;x2落在1~5,這極大的差距可想而知,尤其當他們的相關係數都很大時(可能都是接近1),那x1會造成的影響就可能大於x2。
就像是今天房價與面積、樓層的關係:y = a * x1(坪數) + b * x2(樓層)
而面積可以是50~300(m^2);樓層平均大概只會落在1~5,這樣數字的差距會使得目標函數變扁,進而造成在訓練過程中疊代速度變慢!可以看下方的圖:
1.在還沒進行處理前: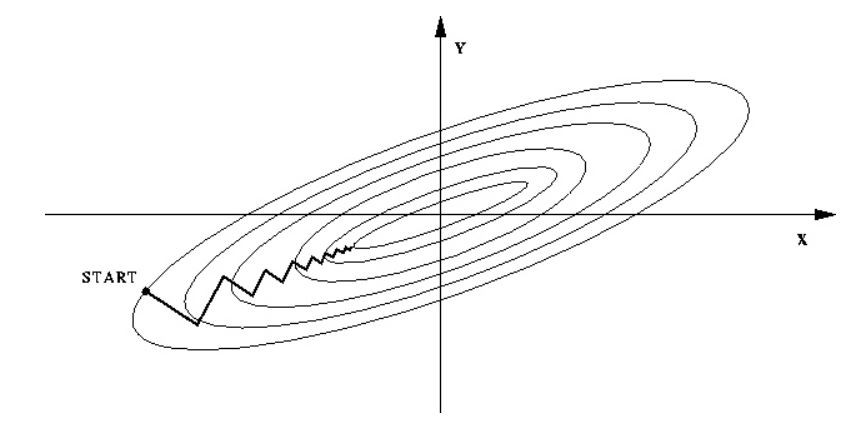
2.處理後: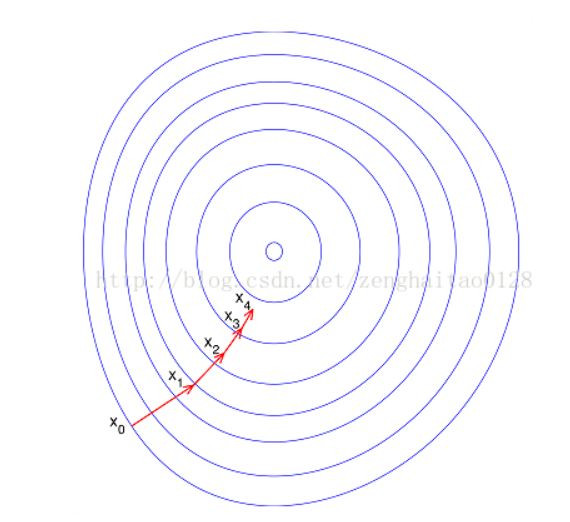
上方兩圖出處
這時候標準化/正規化就很重要啦!
那麼以下兩者對數據處理動作的優點都是:
1.提升模型精準度
2.提升收斂速度
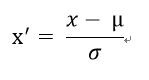
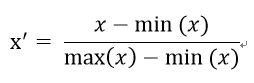
先將原本的訓練資料和驗證資料都先標準化!
from sklearn import preprocessing #引入所需函式庫
normalize = preprocessing.StandardScaler() #取一個短的名字
# 標準化處理
X_trian_normal_data = normalize.fit_transform(X_train_dataset) #將訓練資料標準化
X_validation_normal_data = normalize.fit_transform(X_validation_dataset) #將驗證資料標準化
print(X_trian_normal_data)
print('*'*50)
print(X_validation_normal_data)
輸出:
[[ 2.13150648 1.86572881 1.78757018 0.60188649 1.68363344 1.43474327]
[-0.79485211 -0.38726187 -0.71540986 -1.21671763 -1.05711061 -0.79116606]
[-0.79485211 -0.43096212 -0.52782035 -1.08041967 0.31326141 -0.19886401]
...
[-0.06326246 -2.55770764 0.4208466 0.7459729 0.31326141 0.31223535]
[ 0.66832719 0.77807813 1.06133079 0.0742187 0.31326141 -0.25618356]
[ 0.66832719 0.34350342 0.09122504 0.62330474 0.31326141 0.05907398]]
**************************************************
[[-0.10448035 1.80908987 3.08966184 1.77891255 0.30770478 0.05915902]
[-0.10448035 -0.50234569 -0.48512908 0.13380716 -0.92311434 -0.99987664]
[-0.79784997 -0.68477796 -0.43691417 -0.52458613 -0.92311434 -0.51376191]
...
[-0.10448035 -0.67537423 1.13581016 1.79822542 -0.92311434 -1.10404408]
[-1.49121958 -1.22831325 -1.05911606 -1.39366529 -2.15393345 -2.04155105]
[-0.79784997 -1.0214313 -1.35070145 -0.68611196 -0.92311434 -0.79154175]
明天會開始架設神經網路!敬請期待!

