昨天發文後想到另一個狀況,是因為系統架構設計的關係,網站上呈現的資料並沒有在第一次發請求時取得,而是在網頁載入後陸續以 AJAX 的方式取得資料顯示在畫面上,或者即時以 JavaScript 計算後顯示。雖然這樣做的目的不一定是為了反爬蟲,但仍然會增加開發爬蟲的困難。今天就來補充說明一下怎麼處理這種狀況吧! 絕對不是想拖稿
如果 JavaScript 都是在瀏覽器載入網頁後才會開始執行,那有沒有辦法在程式中打開瀏覽器,模擬正常使用者的操作之後再把資料抓下來呢?
有三個不錯的方法可以滿足我們的需求,接下來會分別介紹。會以 pythonclock 這個倒數的網站來作為範例。
import requests
from bs4 import BeautifulSoup
html_doc = requests.get('https://pythonclock.org/').text
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.find('div', class_='python-27-clock'))
用一般的 requests 方式來抓倒數時間的話,會發現抓到一個空的 div 區塊。
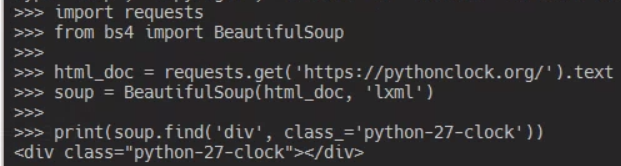
Selenium 可以把人操作瀏覽器的過程自動化,透過 WebDriver 的介面來操作不同的瀏覽器,今天以我比較常用的 Chrome 來作範例。
Chrome 的 web driver 可以到這邊下載,其他瀏覽器可以在官網中找到對應的下載位址。
pipenv install selenium
from selenium import webdriver
from bs4 import BeautifulSoup
# 指定剛剛下載的 webdriver 路徑
driver = webdriver.Chrome('./chromedriver.exe')
# 用瀏覽器連到 https://pythonclock.org/ 網站
driver.get('https://pythonclock.org/')
html_doc = driver.text
soup = BeautifulSoup(html_doc, 'lxml')
print(soup.find('div', class_='python-27-clock'))
執行時會發現自動打開 Chrome 瀏覽器並連到指定的網站,此時就可以抓到有內容的區塊了。
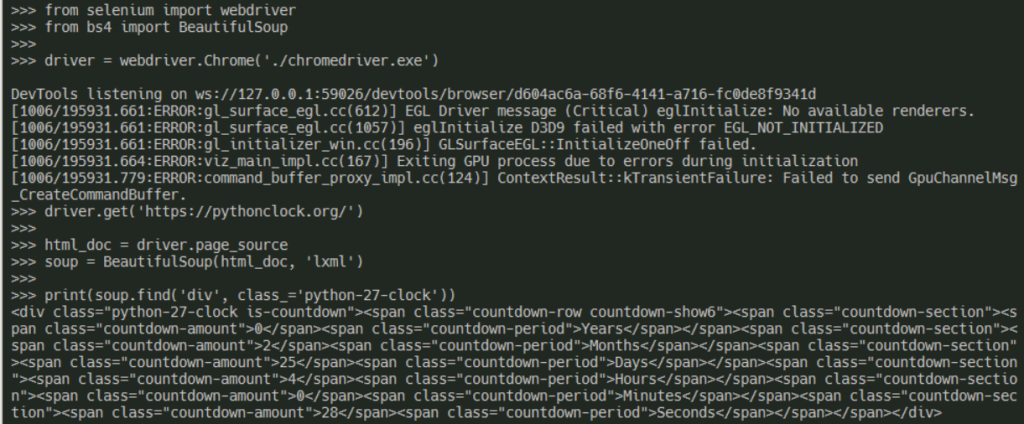
puppeteer 是 Google 開源的 JS 套件,可以用 Headless Chrome 的方式(也就是不會有真的瀏覽器視窗跳出來)來執行 Chrome 瀏覽器。也有大神做了一個 Python 的版本,Pyppeteer,來試試看。
需要搭配 asyncio 使用
pipenv install pyppeteer
import asyncio
from pyppeteer import launch
from bs4 import BeautifulSoup
async def main():
# 開啟瀏覽器程序
browser = await launch()
# 用瀏覽器連到 https://pythonclock.org/ 網站
page = await browser.newPage()
await page.goto('https://pythonclock.org/')
html_doc = await page.content()
soup = BeautifulSoup(html_doc, 'lxml')
await browser.close()
print(soup.find('div', class_='python-27-clock'))
asyncio.set_event_loop(asyncio.new_event_loop())
asyncio.get_event_loop().run_until_complete(main())
(10/6) 今天試的時候一直 timeout...研究一下再更新原因QQ
(10/7) 換了一台電腦就可以了,感覺是 Chromium 在不同環境中執行造成的...
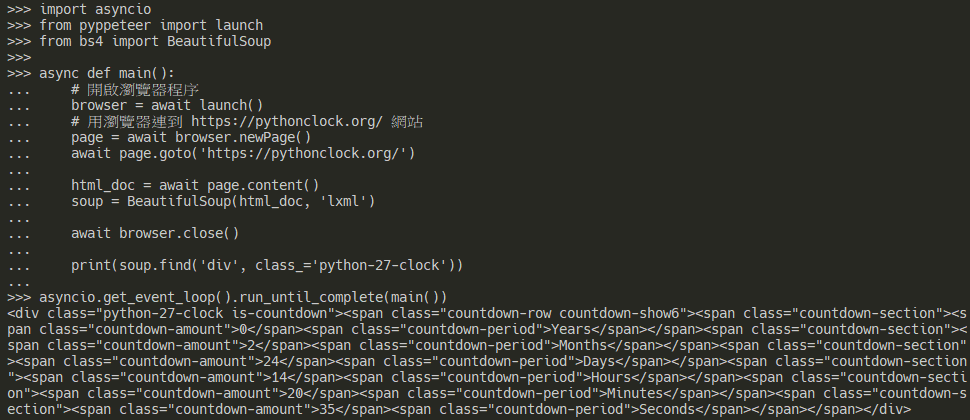
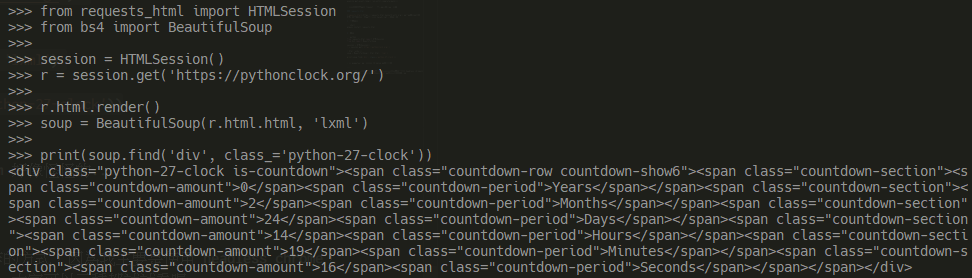
requests-html 也是一個滿好用的 HTML 剖析套件,同時也支援執行 JavaScript 後的結果。
pipenv install requests-html
from requests_html import HTMLSession
from bs4 import BeautifulSoup
session = HTMLSession()
r = session.get('https://pythonclock.org/')
r.html.render()
soup = BeautifulSoup(r.html, 'lxml')
print(soup.find('div', class_='python-27-clock'))
(10/6) 跟 puppeteer 一樣,今天 Chromium 好像怪怪的...
(10/7)
requests-html底層也是呼叫 pyppeteer,所以會有一樣的問題,今天換了一台也可以了
今天介紹了三種用程式模擬瀏覽器操作的方式,因為我主要是使用 headless chrome,所以現在都是用 pyppeteer 比較多,大家可以三種都試試看喔~

