有些網站可能不太希望自己的內容被爬取,例如比價網站爬取各個線上購物的網站後,讓消費者很容易比價,就有可能讓某些網站流失消費者。另外如果太多外部的爬蟲在對伺服器發送請求,也可能造成負載過高而影響到正常使用者的操作。因此有些網站會加入反爬蟲的機制來對付這種非正常的請求。
今天會簡單介紹幾種反爬蟲的方式,同時說明如何避開這些機制。
大部分的爬蟲都是盡量在短時間內蒐集最多的資料(我們前幾天的範例便是如此),甚至會用到類似 aiohttp 的非同步模組來進一步提高爬取速率,因此會在短時間內發送很多請求。
網站可以限制請求的頻率來防止這類的爬蟲,例如同一個 IP 每分鐘只能請求 10 次。
利用 random.uniform() 和 time.sleep(secs) 方法,在每次發請求前讓程式暫停一個隨機的秒數,讓請求頻率降低,且間隔不固定也比較不會被認為是爬蟲。
import requests
from datetime import time
import random
for page in range(1, 11):
requests.get('https://.......')
# 隨機暫停 1~5 秒
time.sleep(random.uniform(1, 5))
全名是 Completely Automated Test to Tell Computers and Humans apart,常見的有幾種:

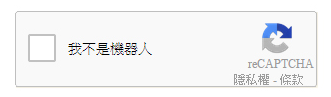

如果是文字辨識,可以嘗試以 pytesseract 來處理,其他兩種就...還不知道怎麼辦。
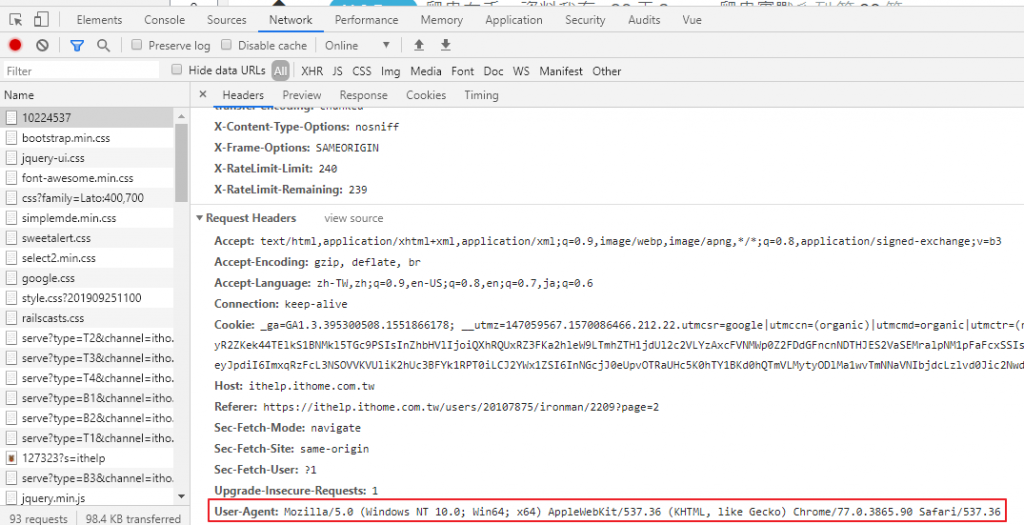
User-Agent(簡稱 UA)是包含在請求標頭中的一段資訊,可以用來表示使用者的裝置類型,不同瀏覽器版本、不同裝置、不同網路爬蟲或不同應用程式的 UA 都會不同。例如:
| Source Type | User-Agent |
|---|---|
| Edge | Mozilla/5.0 (Windows NT 10.0; Win64; x64; ServiceUI 14) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362 |
| Chrome | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36 |
| Googlebot | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Bingbot | Mozilla/5.0 (compatible; Bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| DuckDuckBot | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
| wget | User-Agent: Wget/1.13.4 (linux-gnu) |
| curl | curl/7.64.0 |
| requests | python-requests/2.22.0 |
網站可以很輕鬆的把「明顯」是來自爬蟲的請求擋掉。
發請求的時後把 UA 換掉就可以了,可以換成一個固定的值:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}
requests.get('https://ithelp.ithome.com.tw/articles?tab=tech', headers=headers)
或者用 fake-useragent 套件來幫我們產生一個隨機的 UA:
pipenv install fake-useragent
from fake_useragent import UserAgent
ua = UserAgent()
headers = {'User-Agent': ua.random()}
requests.get('https://ithelp.ithome.com.tw/articles?tab=tech', headers=headers)
今天介紹了幾種常見的反爬蟲方式,如果有興趣深入了解的讀者可以參考下方的連結。明天要進入這個系列的重頭戲了! 快結束了才講到重點是怎樣


 iThome鐵人賽
iThome鐵人賽