寫了好幾天的爬蟲,不知道大家有沒有感覺同一支程式中要關注的事情太多。目前我們爬蟲的流程大概是這樣:
每支爬蟲程式都包含了上述的邏輯,但不同目標網站的爬蟲,差異都只有在 3 和 4 兩個步驟,其他部分基本上都是相同的。隨著爬蟲數量增加,相同的程式片段會越來越多,雖然可以用封裝的方式將相同邏輯都提取到父類別中,但父類別可能也會越來越龐大。如果可以用 AOP 的方式,把不同功能的程式碼都隔離開,未來維護擴充都會方便許多。
藉由類似 Scrapy 的爬蟲框架,可以節省不少開發成本,接下來幾天就會跟大家一起了解 Scrapy 的功能。
Scrapy 框架的架構如下圖:
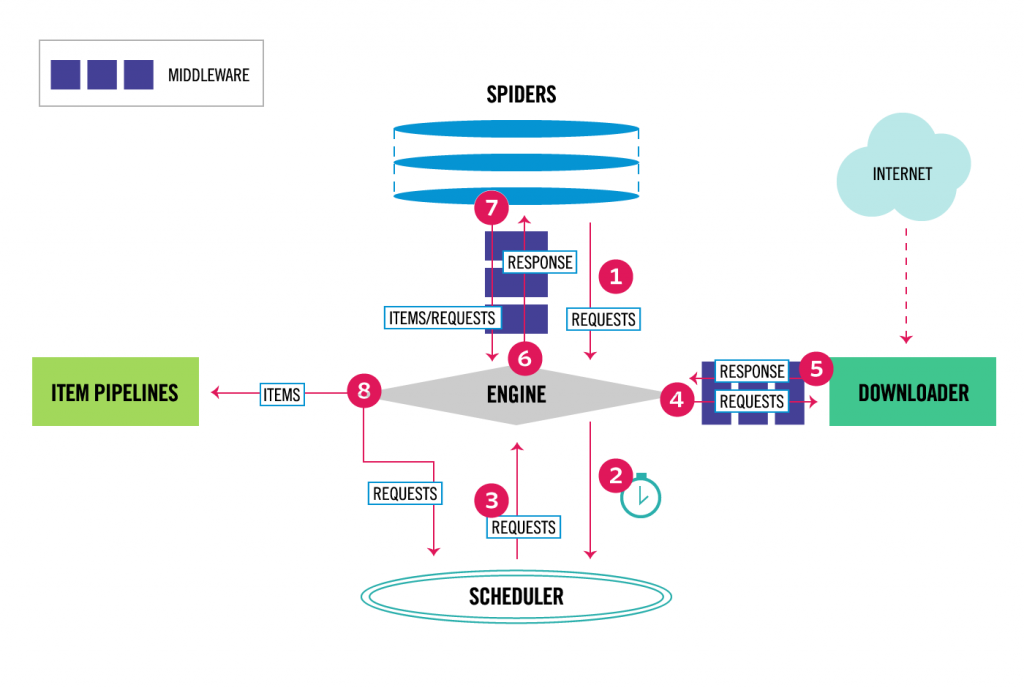
Scrapy 中的資料流向都是由圖片正中央的 Scrapy Engine 來控制,一次完整的流程會是:
Engine 收到 Spider 發來的首次請求
Engine 把剛剛收到的請求加進 Scheduler 的排程中,同時要求其提供接下來要爬取的請求
Scheduler 回傳下次要爬取的請求給 Engine
Engine 將請求發送給 Downloader,發送的過程可能會經過數個 Downloader Middlewares
Downloader 產生一個回應並送回 Engine,過程也可能會經過數個 Downloader Middlewares
Engine 收到 Download 傳來的回應後,傳給 Spider 做處理,過程可能會經過數個 Spider Middlewares
Spider 處理回應後,將爬取到的項目和新的請求回傳給 Engine,過程也可能會經過數個 Spider Middlewares
Engine 將項目傳給 Item Pipelines,同時告知 Scheduler 已處理完這個請求並要求其提供下一個請求
Scheduler 中沒有新的請求Scrapy Engine:負責控制整個框架中的資料流和事件Scheduler:將 Engine 送過來的請求加到佇列中;決定下一個要提供給 Engine 的請求Downloader:負責發送請求和接收回應,並將回應傳回給 EngineSpiders:實際在處理網站爬取邏輯的類別,會回傳爬取出的項目或新的請求給 EngineItem Pipeline:一系列處理爬取項目的邏輯,例如資料清理、驗證或儲存Downloader middlewares:處理 Engine 和 Downloader 之間傳遞的輸入輸出Spider middlewares:處理 Engine 和 Spider 之間傳遞的輸入輸出以 Scrapy 的架構來說,「爬蟲」只要專注在爬取時定位取得資料的邏輯就可以了,其他的邏輯都提取到 middlewares 或 pipeline 中,或者由 Scrapy 自動完成。明天我們就可以來建立第一個 Scrapy 專案囉!

