資料處理的目標就是我想把數值型變數變成類別型的變數,也許可以幫助決策樹的判斷(?,至少是畫成決策樹的時候比較有辦法閱讀,所以我決定將其寫為類別
最簡單的方法就是用分位距的方式,分為等分得10等分.
target = fraud_train$conam
quantile_1 = 0
for(j in 1:i)
quantile_1[j+1] = quantile(target,j*0.1)
另外一種想法就是用分群的方法,由電腦幫忙分群(但是我忘記有一種可以不用輸入分幾類就可以幫忙分群的方法,我記得那個方法只能用在單一變量)
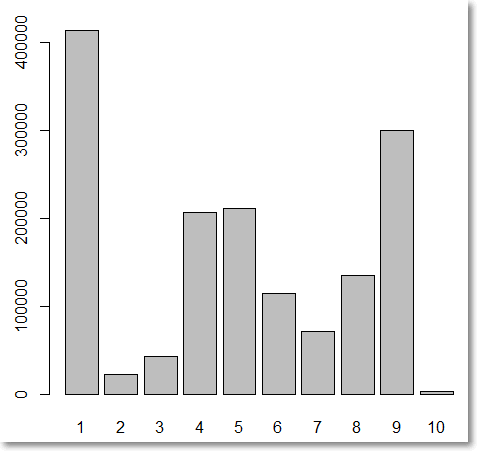
但是學校最常教的kmeans最近鄰法也免牆可以幫助我分類,這時候就不是等量分類了,而是靠得比較近的分為同一類.感覺更符合邏輯.
km <- kmeans(target, centers = 10, nstart = 10)
plot(table(km$cluster))


 iThome鐵人賽
iThome鐵人賽