
在機器學習的工作流程當中,除了資料前處理、特徵工程、建模等工作之外還有一道非常重要的步驟,即不斷地進行優化實驗來確保我們產出的機器學習模型能達到最好的表現。而為了確保我們進行的優化實驗不但在訓練資料集(Training Data)上能夠達到好的表現外,在測試集(Testing Data)也要有同樣優異的表現,達成模型的 泛化(Generalization) ,因此,為了避免在優化過程中產生 過適(Overfitting) 的問題,導致模型在訓練集雖然有好的表現,卻無法於測試集有一致的成績,在進行優化實驗時,還必須從訓練集當中切分出一組 驗證集(Validation Data) ,以此資料集作為超參數優化、特徵工程調整與表現衡量等依據。在接下來的內容我將和各位介紹如何使用Google Cloud Platform的BigQuery從訓練集切分一部份的資料出來,作為優化實驗當中的訓練集與驗證集。
假設今天我們想要將原始訓練集中80%的資料作為訓練集,剩下的20%作為驗證集,一個簡單的方式就是使用為每筆資料賦予0至1的隨機值,再將隨機值小於0.8的資料做為訓練集,剩下的資料為驗證集(見圖1)。但是這樣的做法其實是會有問題的,而其中最主要的問題便是在優化實驗當中,有個被稱作 再現性(Reproducibility) 的重要概念,指的是我們在實驗當中須確保使用的驗證資料是固定、一致且被重複使用的,才能確保我們在實驗當中是往正確的方向修正與前進,若使用原先的隨機值方法,每次我們重新執行程式碼時,就會產生不一樣的結果,違反再現性。
而為了達成此再現性的要求,我們在切分資料時就必須採用另一種做法(見圖2)。同樣是要將原始訓練集中80%的資料作為訓練集,剩下的20%作為驗證集,在這邊我們主要是透過使用 FARM_FINGERPRINT 函數(註1),對某欄位進行 雜湊(Hash) 處理,將原始資料轉換成一固定且保有隨機性的值,再使用 MOD 函數對轉換後的值以10取餘數後,將小於8的數值作為80%的訓練集。採用此方法我們在每次執行後都能得到一樣的切分資料,大大地幫助優化實驗之進行。
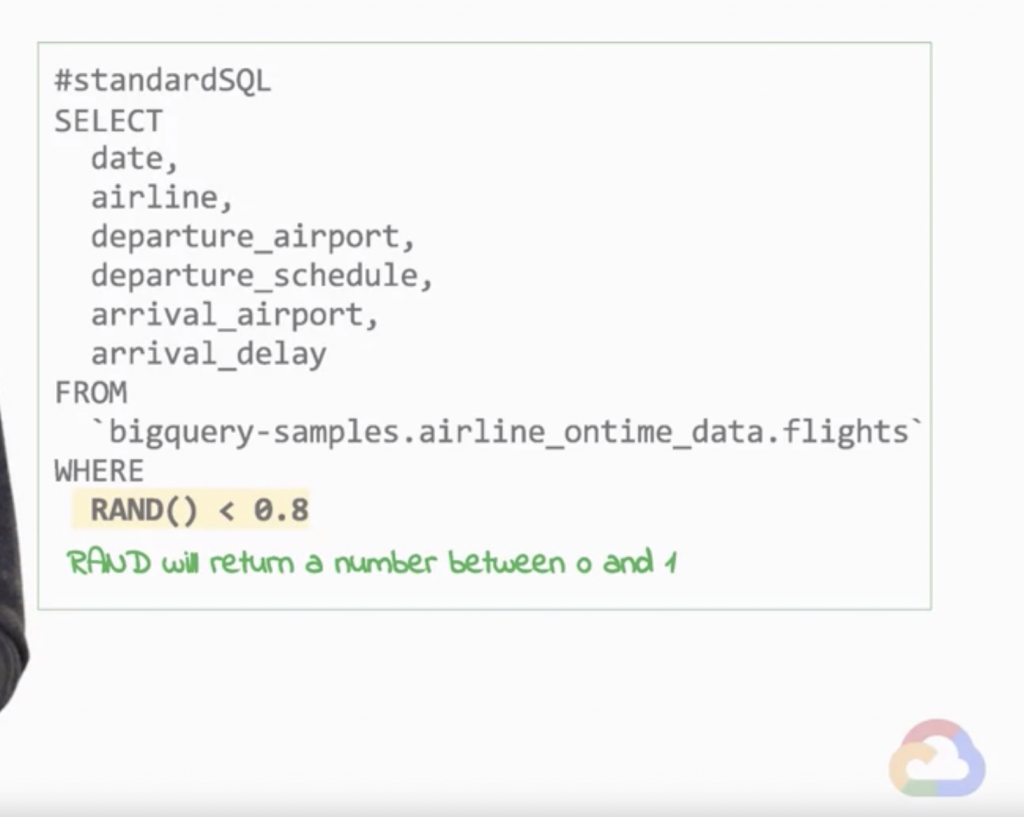
圖1
Source: Coursera - Launching into Machine Learning

圖2
Source: Coursera - Launching into Machine Learning
註1: https://cloud.google.com/bigquery/docs/reference/standard-sql/hash_functions


 iThome鐵人賽
iThome鐵人賽