
在上一篇文章中,我們談到了決策樹(Decision Trees)這個演算法,並知道該演算法能夠解決非線性的問題,但是在解決機器學習的問題上,單個決策樹模型可能還是稍顯不夠強大,而今天即將要介紹的 隨機森林(Random Forests) ,就是一個基於決策樹,且利用一些技巧改進以得到更優秀表現的模型。
從隨機森林名稱的字面上或許可以猜到,他與樹和森林之間的關係似乎是有關聯的。沒錯! 隨機森林模型簡單來說就是將多個決策樹模型組合起來的一個模型(見圖1),在預測上他可以將多個決策樹的結果進行投票(Voting,以多數的結果為最終結果,適合在分類問題上使用)或者平均(適合在回歸問題上使用)作為隨機森林的輸出。而這樣一個將多個模型組合起來成為一個較強模型的技術就稱為 整合學習(Ensemble Learning) (註1)。
整合學習的概念以一句俗諺來說就是 三個臭皮匠勝過一個諸葛亮 ,我們相信結合多個較弱的模型組成一個較強的模型,有機會在準確性與穩定性等方面增進表現。而整合學習下有多種方法,比如說Bagging、Boosting、Blending與Stacking等,這些方法都是在機器學習領域,於增進模型表現上所經常使用的技巧,而今天介紹的隨機森林就屬於其中的Bagging。
或許你會想問說隨機森林是如何建出多個決策樹模型,以作為建構隨機森林的基礎呢? 其使用的方式為同時針對資料與特徵進行抽樣,以抽樣的結果建立決策樹模型,因此每一個決策樹模型都是有所差異的,而這也是使用整合學習上一個很重要的考量點,我們要使用盡量不相似的模型,以增加決策的多樣性,如此情況可以反映至最終表現與穩定性的提升。
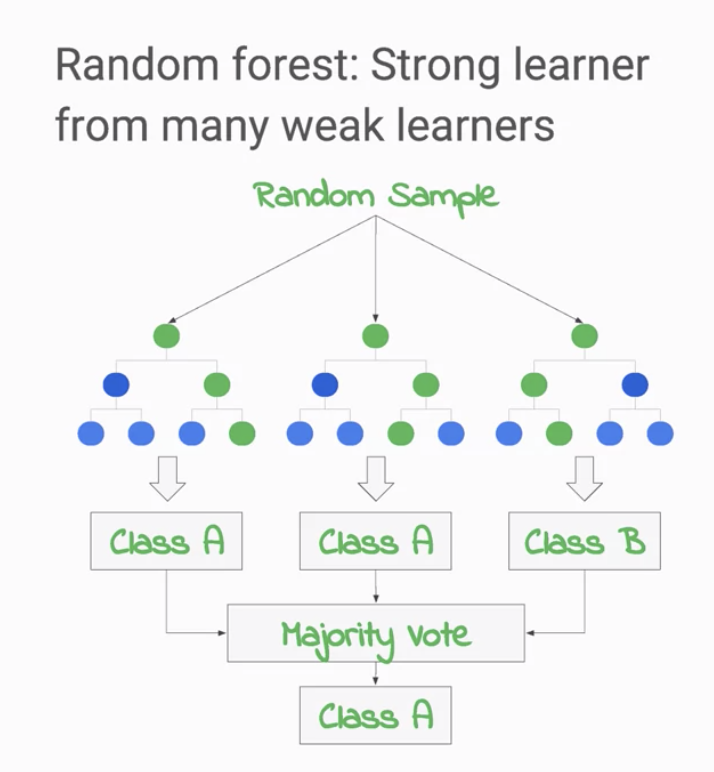
圖1
Source: Coursera - Launching into Machine Learning
註1: https://en.wikipedia.org/wiki/Ensemble_learning

 iThome鐵人賽
iThome鐵人賽