流程漸漸來到了中段,
開始進行機器學習三步驟,
分別為「選擇模型」、「評估模型」、「最佳參數」。
1. 選擇模型
- 一個模型中會有「許多參數」
- 不同參數的模型就會產⽣「不同的 ŷ」
- 模型產生的 ŷ 跟真實答案的 y 越接近越好
- 模型通常有線性回歸、決策樹、神經網路路等
2. 評估模型
- 「回歸模型」通常使用MAE、MSE、R-sequare
- 「分類模型」通常使用AUC、F1-score
- 模型的訓練⽬標是將損失函數的「損失降至最低」
3. 最佳參數
- 模型的參參數組合可能有無限多組
- 可使用梯度下降 (Gradient Descent)、增量訓練 (Additive Training) 找最佳參數
- 避免過擬和(Over fitting)
學習曲線
目的:用來觀察模型是否擬合?
參考文章學習曲線判斷模型狀態:欠擬合 or 過擬合,
AB爲欠擬合,C爲正好擬合 (接近1),D爲過擬合
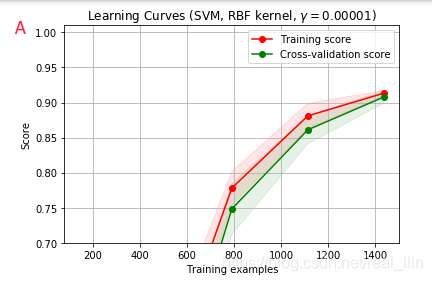
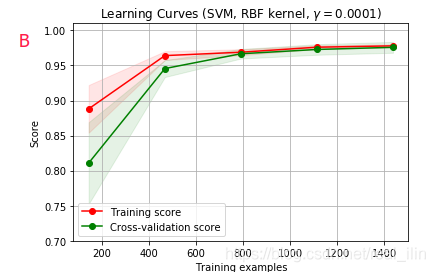
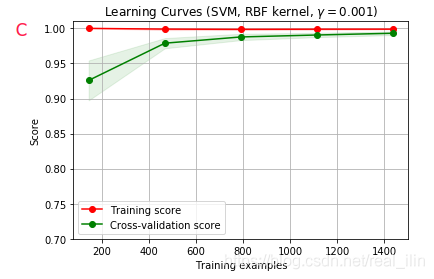
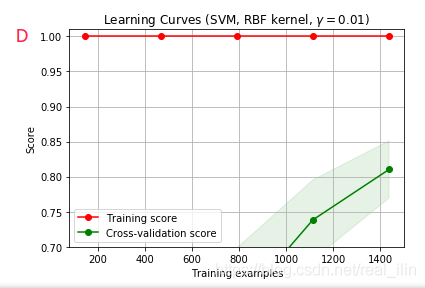
過擬和
解決方法:
- 增加資料量
- 降低模型複雜度
- 使用正規化 (Regularization)
⽋擬合
解決方法:
通常在最後選「最佳參數」,
會需要判斷是否擬合,
尤其現實很多情況會有over fitting問題。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽