通常想找一個Model的variance夠小和bias夠小,
達到一個trade-off(平衡),
如此可得到最小的testing error。
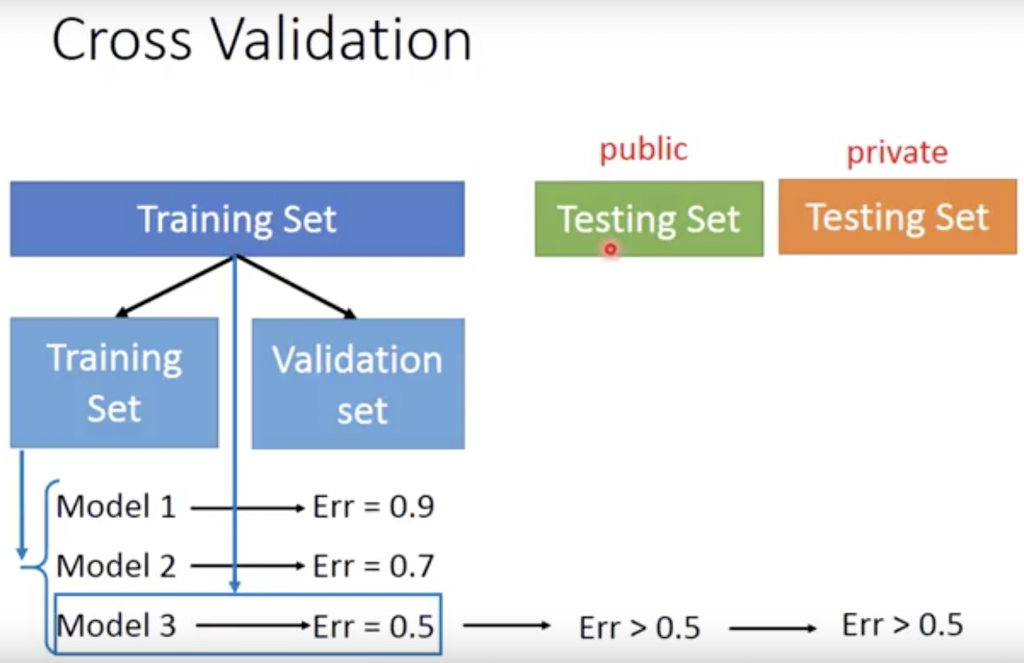
參考影片ML Lecture 2: Where does the error come from?,
先將Training Set分兩群為Training Set和Validation Set,
得到最小Error的Modle 3,
再用全部Training Set和public Testing Set可能得到Error > 0.5,
如此private的Testing Set才會是真正的Error > 0.5。
資料切分方法,有分為以下兩種:
通常用於資料量多,以33%分切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
通常用於資料量少,以下切分5等分,分別驗證取平均值
cross_val_score(estimator, train_X, train_Y, cv=5).mean()
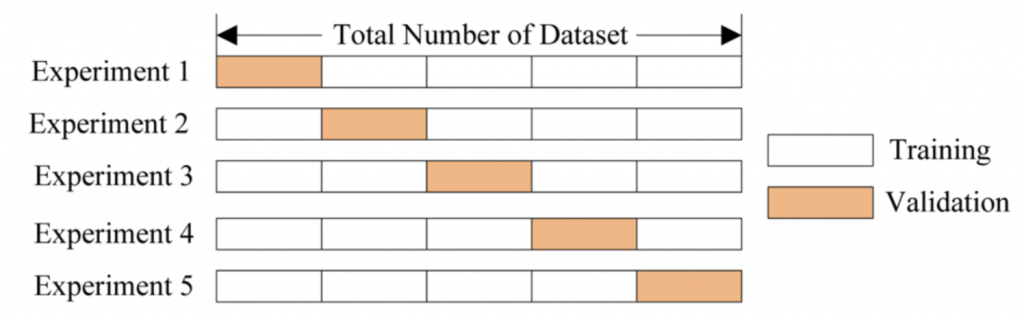
切的等份和百分比,
通常需要視資料特性,
以經驗法則和try and error判斷。
以上,打完收工。


 iThome鐵人賽
iThome鐵人賽