這一陣子總統大選幾乎天天有民調,各家調查結果大相逕庭,調查結果相差10~20%,但每一項民調都宣稱『信心水準95%,抽樣誤差為正負3.0%』,照理講不是應該只有 5% (1-95%) 的機率會猜錯嗎? 為什麼每次大選都跌破一大堆眼鏡呢? 基於好奇心,用力研究一下民意調查相關程序及其背後的統計理論基礎,將心得分享一下,期望與大家作進一步的討論,找出問題所在。
母體:依中選會推估2020年總統大選全國選舉人數約為1900萬人,投票率7成,有效投票人數約為1400萬人。
調查方法:
以《美麗島電子報》為例,透過『電腦輔助電話訪問系統』(Computer Assisted Telephone Interviewing System,簡稱CATIS)方式進行調查,依選民結構(年齡、性別、偏好政黨等)作『等比例分層隨機抽樣』,以1000人左右的成功完訪作為樣本,進行統計。
調查結果(2019/12/22):
其他家的民調也大同小異,參見2020年中華民國總統選舉民意調查 - 維基百科,自由的百科全書,擷取其中一張表如下,可以看到有效樣本均為1000人多一點: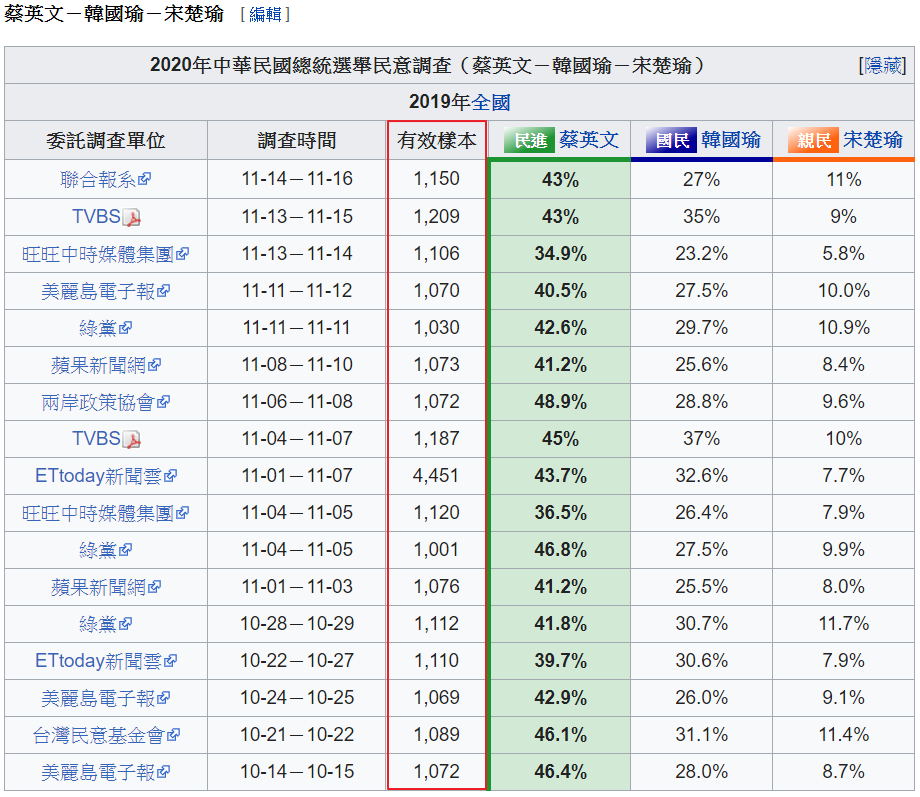
圖. 民意調查彙總表
計算之前,我們先將相關統計量的定義弄清楚,往下讀時先閉目養神一下,或喝口茶提神一下。
一般會假設母體符合『二項分配』(Binomial distribution),即某人當選的機率為p,因此,
其中 SQRT 為開根號。
依照『中央極限定理』(Central Limit Theorem),隨機抽取大小為n的多批獨立樣本,當批數很大時,其每批樣本的平均數分佈會趨近於常態分配(Normal distribution),基於此一定理,我們就可以使用常態分配來作區間估計,計算其信賴區間(Confidence interval),亦即,民意調查設定『信心水準95%』,即信賴區間會落在(μ - 1.96σ, μ + 1.96σ) 之間,換句話說,就是p有95%機率會落在此區間內,參見下圖。
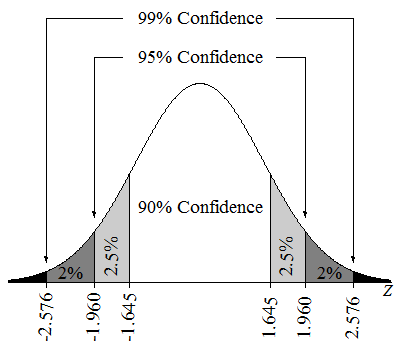
圖. 信心水準(Confidence level),圖片來源:Hypothesis Testing in Machine Learning: What for and Why
若民調設定抽樣誤差=3%,就是說如果調查結果支持特定候選人的百分比介於(47%,53%)之間,表示在『信心水準95%』的假設下,效果不顯著,無法判別該候選人是否會當選或落選,反之,在(47%,53%)範圍外,我們才可以依據調查結果大膽推論,該候選人會當選或落選。
所以,基於『信心水準95%,抽樣誤差為正負3.0%』的前提下,我們就可以計算需要調查多少樣本才可滿足此一條件。假設每一個候選人當選與落選的機率是均等的,即p=0.5,抽樣誤差=3%,要抽多少樣本呢? 計算如下:
# 基於
# 1.96 * σ = 0.03 (抽樣誤差)
# σ = (0.5 / sqrt(n))
# ==>
# 1.96 * (0.5 / sqrt(n)) = 0.03
# 將上式移項,求 n
n= (0.5/(0.03/1.96)) ** 2
print(n)
計算得知樣本筆數(n)要大於 1067,故每家民調公司的樣本筆數均為1,000筆左右。
如果調查10,000筆呢?
# n=10,000時,抽樣誤差=?
import math
n=10000
err=1.96 * (0.5 / math.sqrt(n))
print(f'{err*100}%')
計算得知抽樣誤差=0.98%。
同樣在『信心水準95%』的假設下,調查10,000筆,若結果落在(49.02%,50.98%)範圍外,我們就可以大膽推論,該候選人會當選或落選。換個角度說,在同樣的區間估計(47%,53%)下,更多的樣本可以得到更大的信心水準,透過以下計算,幾乎已達6倍標準差了,也就是說調查結果幾乎可以百分之百信任了(真的嗎?)。
# n=10,000時,信心水準=?
import math
n = 10000
s = 0.5 / math.sqrt(n)
# 47% 標準化
lower_bound=(0.47 - 0.5)/s
upper_bound=(0.53 - 0.5)/s
# 計算信心水準
i, e = integrate.quad(norms, lower_bound, upper_bound)
print(f'標準差: {s:.2f}')
print(f'標準化: {lower_bound:.2f}, {upper_bound:.2f}')
print(f'信心水準: {i:.2f}')
結果為:
標準差: 0.01
標準化: -6.00, 6.00
信心水準: 1.00
以上就是行之多年的民意調查的理論基礎,看似非常嚴謹,但是歷年的實證結果卻非常差,原因可能如下:
如果排除以上因素,單就學理探討,以上決定抽樣人數(1,067人)的方法也有缺陷:
如果要額外考慮型二誤差(Type II error),可使用檢定力分析(Power Analysis),接下來,我們就來看看這種方法計算出來的結果。有關型一誤差、型二誤差,可參閱『淺談機器學習的效能衡量指標』系列文的介紹。
型二誤差(β):即虛無假設為假時,卻拒絕虛無假設,即兩組候選人有明顯差距,卻誤認無差距。
檢定力(Power):即型二誤差的檢定能力,如果檢定力不足,就不能排除隨機誤差是造成有差異的原因。一般檢定力會設成0.8以上。
效應值(effect size):實驗組和控制組之間差異的大小,其絕對值越大表示效應越強,也就是現象越明顯。應用在民調上,就是兩組候選人的差距在多少百分比以上,才被認為有明顯的差異。通常會參考 Cohen's d 效應值統計表來作設定。
| # | d Value | 意義 |
|---|---|---|
| 1. | 0 - 0.2 | 可忽視的 |
| 2. | 0.2 - 0.5 | 小 |
| 3. | 0.5 - 0.8 | 中 |
| 4. | 0.80 + | 大 |
Wikipedia 定義的效應值統計表:
| # | d Value | 意義 |
|---|---|---|
| 1. | 0.10 | 小 |
| 2. | 0.30 | 中 |
| 3. | 0.50 + | 大 |
分別設定檢定力、效應值後,就可以使用『檢定力分析』計算抽樣人數。筆者直接使用 Python statsmodels 套件可就可以輕易算出來了。
# 檢定力分析(Power Analysis)
from statsmodels.stats.power import tt_ind_solve_power
tt_ind_solve_power(effect_size=0.1, nobs1 = None, alpha=0.05, power=0.8, ratio=1, alternative='two-sided')
得到結果,應抽樣人數=1570.
# 檢定力分析(Power Analysis)
from statsmodels.stats.power import tt_ind_solve_power
tt_ind_solve_power(effect_size=0.1, nobs1 = None, alpha=0.05, power=0.9, ratio=1, alternative='two-sided')
得到結果,應抽樣人數=2102.
# 檢定力分析(Power Analysis)
from statsmodels.stats.power import tt_ind_solve_power
tt_ind_solve_power(effect_size=0.1, nobs1 = None, alpha=0.05, power=0.9, ratio=1, alternative='two-sided')
得到結果,應抽樣人數=175.
顯然,這個方法比現行的民調方法有彈性,也比較週全。
目前民調的理論基礎並不堅實(Solid),調查結果也因差異很大,又不準確,倍受質疑,到底改善的方向為何,期待統計大神們出來說清楚、講明白,因為台灣一天到晚在選舉,每逢總統大選,幾乎天天有民調,到底要信哪一家民調? 還是只能信上帝?
寫得好,受教了。
我有個疑問~
2.採市話抽樣:目前手機盛行,已有一大部分家庭未安裝市話,這些人就被排除在樣本之外。
3.採用電話簿抽樣:電話簿中不登記者約有50%,即母體有一半被排除在樣本之外。
若在充分的隨機抽樣之下,應該不會發生【支持A的人都有裝市話,支持B的人都不裝市話】的情形吧?裝或不裝市話;電話簿有登記或沒登記,應該都同時擁有A和B的支持者才對,按理,也應屬常態分配,它的影響,是否足以推翻民調之可信度?
民調不能作為總統當選之依據,但卻是目前諸多政黨之【黨內初選】之依據,若上述二個因素能成立,那落選者怎會心服?
又,若把表列17家的民調再綜合平均一下(先假設公布數字是真實的),那麼,就統計學上來看,平均之後的數字,有否可能更為精準些?
您既然提出了問題,想必心中也有因應之道,先不管有沒有誰要採行啦,就技術上來討論,您認為怎麼做比較能達到更精準?
有人說市話和手機各半,看起來有道理,不過也有盲點,【各半】或【各佔?%】,要怎麼訂?有什麼科學根據這麼訂?
我剛查了一下,到2018年上半年止,全國手機門號有2,894.5萬支,遠超過可能的投票人口了,這個要怎麼考量呢?
年輕人可能有手機沒市話,但中老年人大部份是有手機也有市話,萬一他剛好接到二通,這也會失準啊,還有,有些業務員,手機可不止一支哦,所以,如果都要把這些因素拿來討論,根本就不必做民調了。
 I code so I am
I code so I am
