Hive是基於Hadoop的資料倉庫工具,可對存儲在HDFS上的檔中的資料集進行資料整理、特殊查詢和分析處理,提供了類似於SQL語言的查詢語言–HiveQL,可透過HQL語句實現簡單的MR統計,Hive將HQL語句轉換成MR任務進行執行。
一、概述
1.1 資料倉庫概念
資料倉庫(Data Warehouse)是一個面向主題的(Subject Oriented)、集成的(Integrated)、相對穩定的(Non-Volatile)、反應歷史變化(Time Variant)的資料集合,用於支援管理決策。
資料倉庫體系結構通常含四個層次:資料來源、資料存儲和管理、資料服務、資料應用。
- 資料來源:是資料倉庫的資料來源,含外部資料、現有業務系統和文檔資料等;
- 資料集成:完成資料的抽取、清洗、轉換和載入任務,資料來源中的資料採用ETL(Extract-Transform-Load)工具以固定的週期載入到資料倉庫中。
- 資料存儲和管理:此層次主要涉及對資料的存儲和管理,含資料倉庫、資料集市、資料倉庫檢測、運行與維護工具和中繼資料管理等。
- 資料服務:為前端和應用提供資料服務,可直接從資料倉庫中獲取資料供前端應用使用,也可透過OLAP(OnLine Analytical Processing,連線分析處理)伺服器為前端應用提供負責的資料服務。
- 資料應用:此層次直接面向使用者,含資料查詢工具、自由報表工具、資料分析工具、資料採擷工具和各類應用系統。
1.2 傳統資料倉庫的問題
無法滿足快速增長的海量資料存儲需求,傳統資料倉庫基於關係型資料庫,橫向可延伸性較差,縱向可延伸性有限。
無法處理不同類型的資料,傳統資料倉庫只能存儲結構化資料,企業業務發展,資料來源的格式越來越豐富。
傳統資料倉庫建立在關聯式資料倉庫之上,計算和處理能力不足,當資料量達到TB級後基本無法獲得好的性能。
1.3 Hive
Hive是建立在Hadoop之上的資料倉庫,由Facebook開發,在某種程度上可以看成是使用者程式設計介面,本身並不存儲和處理資料,依賴於HDFS存儲資料,依賴MR處理資料。有類SQL語言HiveQL,不完全支援SQL標準,如,不支援更新操作、索引和事務,其子查詢和連結操作也存在很多限制。
Hive把HQL語句轉換成MR任務後,採用批次處理的方式對海量資料進行處理。資料倉庫存儲的是靜態資料,很適合採用MR進行批次處理。Hive還提供了一系列對資料進行提取、轉換、載入的工具,可以存儲、查詢和分析存儲在HDFS上的資料。
1.4 Hive與Hadoop生態系統中其他元件的關係
Hive依賴於HDFS存儲資料,依賴MR處理資料;
Pig可作為Hive的替代工具,是一種資料流程語言和運行環境,適合用於在Hadoop平台上查詢半結構化資料集,用於與ETL過程的一部分,即將外部資料裝載到Hadoop叢集中,轉換為使用者需要的資料格式;
HBase是一個面向列的、分散式可伸縮的資料庫,可提供資料的即時訪問功能,而Hive只能處理靜態資料,主要是BI報表資料,Hive的初衷是為減少複雜MR應用程式的編寫工作,HBase則是為了實現對資料的即時訪問。
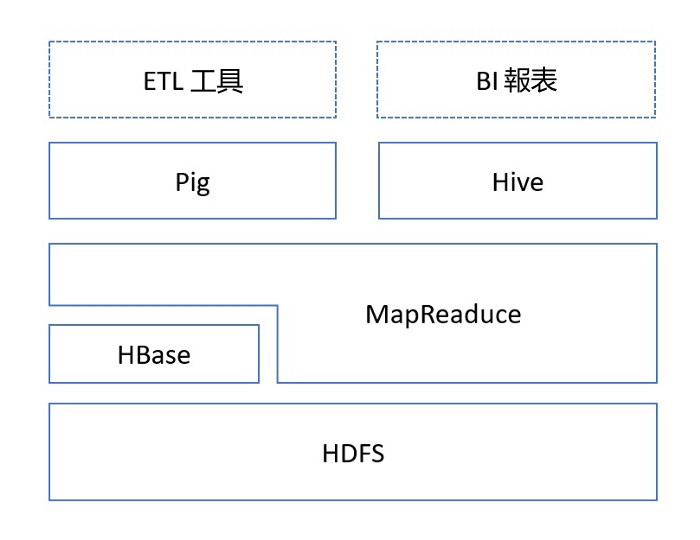
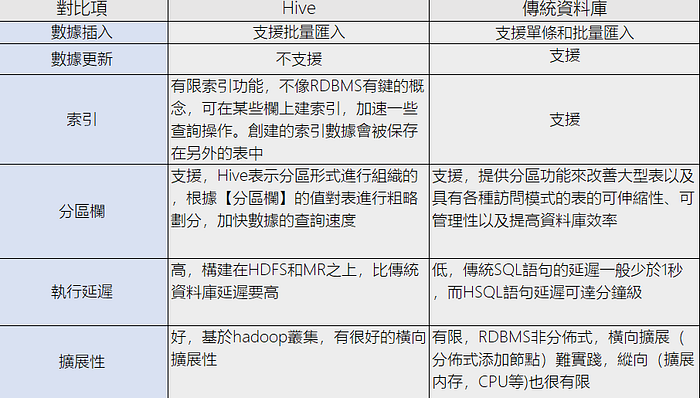
1.5 Hive與傳統資料庫的對比
1.6 Hive的部署和應用
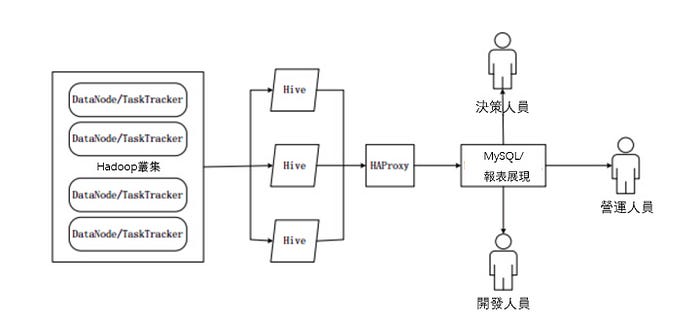
1.6.1 Hive在企業大數據分析平台中的應用
當前企業中部署的大數據分析平台,除Hadoop的基本元件HDFS和MR外,還結合使用Hive、Pig、HBase、Mahout,從而滿足不同業務場景需求。
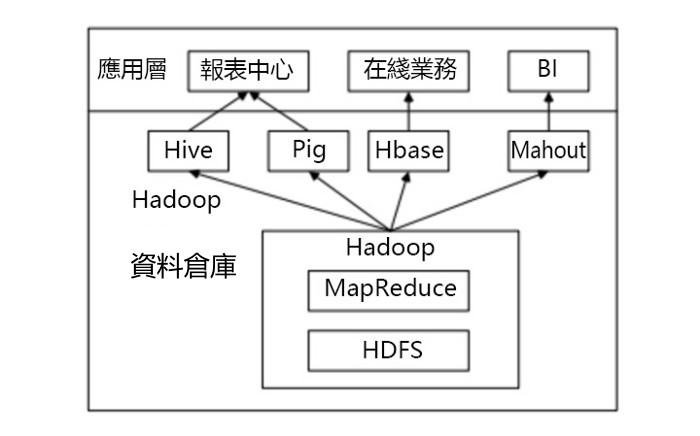
上圖是企業中一種常見的大數據分析平台部署框架 ,在這種部署架構中:
- Hive和Pig用於報表中心,Hive用於分析報表,Pig用於報表中資料的轉換工作。
- HBase用於線上業務,HDFS不支援隨機讀寫操作,而HBase正是為此開發,可較好地支援即時訪問資料。
- Mahout提供一些可延伸的機器學習領域的經典演算法實現,用於創建商務智慧(BI)應用程式。
二、Hive系統架構
下圖顯示Hive的主要組成模組、Hive如何與Hadoop交互工作、以及從外部訪問Hive的幾種典型方式。
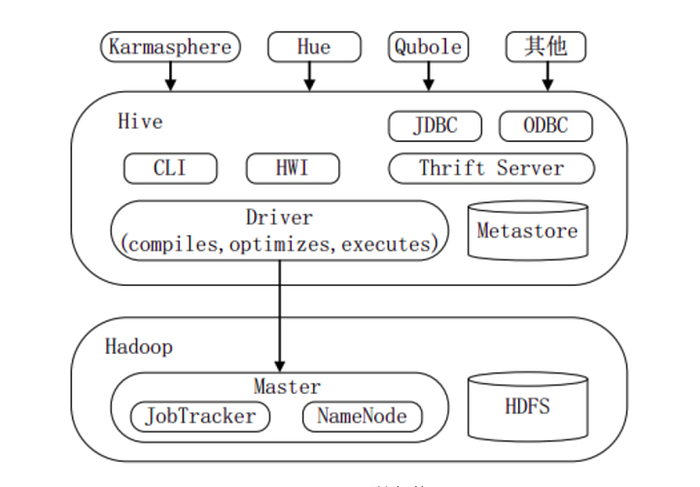
Hive主要由以下三個模組組成:
- 使用者介面模組,含CLI、HWI、JDBC、Thrift Server等,用來實現對Hive的訪問。CLI是Hive自帶的命令列介面;HWI是Hive的一個簡單網頁介面;JDBC、ODBC以及Thrift Server可向使用者提供進行程式設計的介面,其中Thrift Server是基於Thrift軟體框架開發的,提供Hive的RPC通信介面。
- 驅動模組(Driver),含編譯器、優化器、執行器等,負責把HiveQL語句轉換成一系列MR作業,所有命令和查詢都會進入驅動模組,透過該模組的解析變異,對計算過程進行改善,然後按照指定的步驟執行。
- 中繼資料存儲模組(Metastore),是一個獨立的關係型資料庫,通常與MySQL資料庫連接後創建的一個MySQL實例,也可以是Hive自帶的Derby資料庫實例。此模組主要保存表模式和其他系統中繼資料,如表的名稱、表的列及其屬性、表的分區及其屬性、表的屬性、表中資料所在位置資訊等。
喜歡圖形介面的使用者,可採用幾種典型的外部訪問工具:Karmasphere、Hue、Qubole等。
三、Hive工作原理
3.1 SQL語句轉換成MapReduce作業的基本原理
3.1.1 用MapReduce實現連接操作
假設連接(join)的兩個表分別是用戶表User(uid,name)和訂單表Order(uid,orderid),具體的SQL命令:
SELECT name, orderid FROM User u JOIN Order o ON u.uid=o.uid;
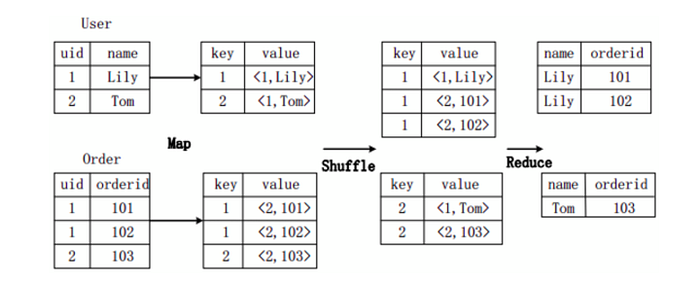
上圖描述了連結操作轉換為MapReduce操作任務的具體執行過程。
首先,在Map階段,
- User表以uid為key,以name和表的標記位元(這裡User的標記位元記為1)為value,進行Map操作,把表中記錄轉換生成一系列KV對的形式。比如,User表中記錄(1,Lily)轉換為鍵值對(1,<1,Lily>),其中第一個“1”是uid的值,第二個“1”是表User的標記位元,用來標示這個鍵值對來自User表;
- 同樣,Order表以uid為key,以orderid和表的標記位元(這裡表Order的標記位元記為2)為值進行Map操作,把表中的記錄轉換生成一系列KV對的形式;
- 接著,在Shuffle階段,把User表和Order表生成的KV對按鍵值進行Hash,然後傳送給對應的Reduce機器執行。比如KV對(1,<1,Lily>)、(1,<2,101>)、(1,<2,102>)傳送到同一台Reduce機器上。當Reduce機器接收到這些KV對時,還需按表的標記位元對這些鍵值對進行排序,以改善連接操作;
- 最後,在Reduce階段,對同一台Reduce機器上的鍵值對,根據“值”(value)中的表標記位元,對來自表User和Order的資料進行笛卡爾積連接操作,以生成最終的結果。比如鍵值對(1,<1,Lily>)與鍵值對(1,<2,101>)、(1,<2,102>)的連接結果是(Lily,101)、(Lily,102)。
3.1.2 用MR實現分組操作
假設分數表Score(rank, level),具有rank(排名)和level(級別)兩個屬性,需要進行一個分組(Group By)操作,功能是把表Score的不同片段按照rank和level的組合值進行合併,並計算不同的組合值有幾條記錄。SQL語句命令如下:
SELECT rank,level,count(*) as value FROM score GROUP BY rank,level;
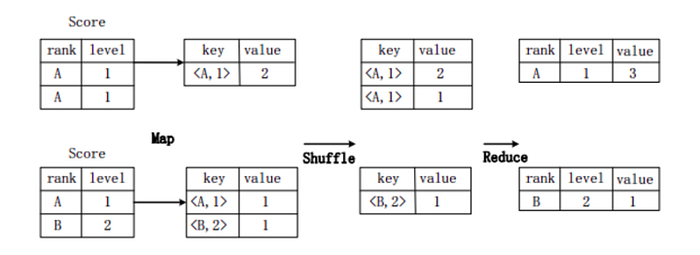
上圖描述分組操作轉化為MapReduce任務的具體執行過程。
- 首先,在Map階段,對表Score進行Map操作,生成一系列KV對,其鍵為<rank, level>,值為“擁有該<rank, level>組合值的記錄的條數”。比如,Score表的第一片段中有兩條記錄(A,1),所以進行Map操作後,轉化為鍵值對(<A,1>,2);
- 接著在Shuffle階段,對Score表生成的鍵值對,按照“鍵”的值進行Hash,然後根據Hash結果傳送給對應的Reduce機器去執行。比如,鍵值對(<A,1>,2)、(<A,1>,1)傳送到同一台Reduce機器上,鍵值對(<B,2>,1)傳送另一Reduce機器上。然後,Reduce機器對接收到的這些鍵值對,按“鍵”的值進行排序;
- 在Reduce階段,把具有相同鍵的所有鍵值對的“值”進行累加,生成分組的最終結果。比如,在同一台Reduce機器上的鍵值對(<A,1>,2)和(<A,1>,1)Reduce操作後的輸出結果為(A,1,3)。
3.2 Hive中SQL查詢轉換成MR作業的過程
當Hive接收到一條HQL語句後,需要與Hadoop交互工作來完成該操作。HQL首先進入驅動模組,由驅動模組中的編譯器解析編譯,並由優化器對該操作進行最佳化計算,然後交給執行器去執行。執行器通常啟動一個或多個MR任務,有時也不啟動(如SELECT * FROM tb1,全資料表掃描,不存在投影和選擇操作)

上圖是Hive把HQL語句轉化成MR任務進行執行的詳細過程。
- 由驅動模組中的編譯器–Antlr語言識別工具,對使用者輸入的SQL語句進行詞法和語法解析,將HQL語句轉換成抽象語法樹(AST Tree)的形式;
- 遍歷抽象語法樹,轉化成QueryBlock查詢單元。因為AST結構複雜,不方便直接翻譯成MR演算法程式。其中QueryBlock是一條最基本的SQL語法組成單元,包括輸入源、計算過程、和輸入三個部分;
- 遍歷QueryBlock,生成OperatorTree(操作樹),OperatorTree由很多邏輯操作符組成,如TableScanOperator、SelectOperator、FilterOperator、JoinOperator、GroupByOperator和ReduceSinkOperator等。這些邏輯操作符可在Map、Reduce階段完成某一特定操作;
- Hive驅動模組中的邏輯優化器對OperatorTree進行優化,變換OperatorTree的形式,合併多餘的操作符,減少MR任務數、以及Shuffle階段的資料量;
- 遍歷最佳化後的OperatorTree,根據OperatorTree中的邏輯操作符生成需要執行的MR任務;
- 啟動Hive驅動模組中的物理優化器,對生成的MR任務進行優化,生成最終的MR任務執行計畫;
- 最後,有Hive驅動模組中的執行器,對最終的MR任務執行輸出。
Hive驅動模組中的執行器執行最終的MR任務時,Hive本身不會生成MR演算法程式。它透過一個表示“Job執行計畫”的XML檔,來驅動內置的、原生的Mapper和Reducer模組。Hive透過和JobTracker通信來初始化MR任務,而不需直接部署在JobTracker所在管理節點上執行。通常在大型叢集中,會有專門的閘道機來部署Hive工具,這些閘道機的作用主要是遠端操作和管理節點上的JobTracker通信來執行任務。Hive要處理的資料檔案常存儲在HDFS上,HDFS由名稱節點(NameNode)來管理。
四、Hive HA基本原理
在實際應用中,Hive也暴露出不穩定的問題,在極少數情況下,會出現埠不回應或進程丟失問題。Hive HA(High Availablity)可以解決這類問題。
在Hive HA中,在Hadoop叢集上構建的資料倉庫是由多個Hive實例進行管理的,這些Hive實例被納入到一個資源池中,由HAProxy提供統一的對外介面。用戶端的查詢請求,首先訪問HAProxy,由HAProxy對訪問請求進行轉發。HAProxy收到請求後,會輪詢資源池中可用的Hive實例,執行邏輯可用性測試。
如果某個Hive實例邏輯可用,就會把用戶端的訪問請求轉發到Hive實例上;
如果某個實例不可用,就把它放入黑名單,並繼續從資源池中取出下一個Hive實例進行邏輯可用性測試。
對於黑名單中的Hive,Hive HA會每隔一段時間進行統一處理,首先嘗試重啟該Hive實例,如果重啟成功,就再次把它放入資源池中。
由於HAProxy提供統一的對外訪問介面,因此,對於程式開發人員來說,可把它看成一台超強“Hive”。
五、Impala
5.1 Impala簡介
Impala由Cloudera公司開發,提供SQL語義,可查詢存儲在Hadoop和HBase上的PB級海量資料。Hive也提供SQL語義,但底層執行任務仍借助於MR,即時性不好,查詢延遲較高。
Impala作為新一代開源大數據分析引擎,最初參照Dremel(由Google開發的互動式資料分析系統),支援即時計算,提供與Hive類似的功能,在性能上高出Hive3~30倍。Impala可能會超過Hive的使用率能成為Hadoop上最流行的即時計算平台。Impala採用與商用並行關聯式資料庫類似的分散式查詢引擎,可直接從HDFS、HBase中用SQL語句查詢資料,不需把SQL語句轉換成MR任務,降低延遲,可很好地滿足即時查詢需求。
Impala不能替換Hive,可提供一個統一的平台用於即時查詢。Impala的運行依賴於Hive的中繼資料(Metastore)。Impala和Hive採用相同的SQL語法、ODBC驅動程式和使用者介面,可統一部署Hive和Impala等分析工具,同時支持批次處理和即時查詢。
5.2 Impala系統架構
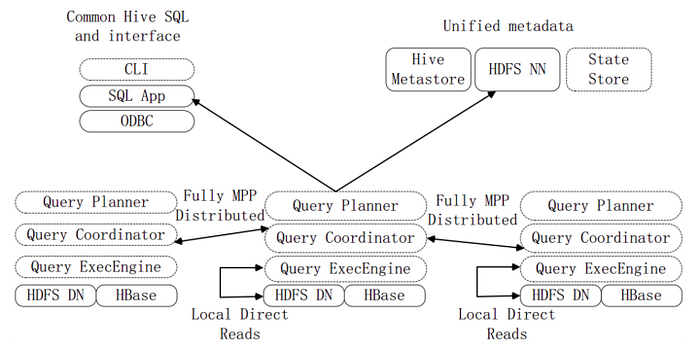
- 上圖是Impala系統結構圖,虛線模組資料Impala元件。Impala和Hive、HDFS、HBase統一部署在Hadoop平台上。Impala由Impalad、State Store和CLI三部分組成。
- Implalad:是Impala的一個進程,負責協調用戶端提供的查詢執行,給其他Impalad分配任務,以及收集其他Impalad的執行結果進行匯總。Impalad也會執行其他Impalad給其分配的任務,主要是對本地HDFS和HBase裡的部分資料進行操作。Impalad進程主要含Query Planner、Query Coordinator和Query Exec Engine三個模組,與HDFS的資料節點(HDFS DataNode)運行在同一節點上,且完全分佈運行在MPP(大規模並行處理系統)架構上。
- State Store:收集分佈在叢集上各個Impalad進程的資源資訊,用於查詢的調度,它會創建一個statestored進程,來跟蹤叢集中的Impalad的健康狀態及位置資訊。statestored進程透過創建多個執行緒來處理Impalad的註冊訂閱以及與多個Impalad保持心跳連結,此外,各Impalad都會緩存一份State Store中的資訊。當State Store離線後,Impalad一旦發現State Store處於離線狀態時,就會進入復原模式,並進行返回註冊。當State Store重新加入叢集後,自動恢復正常,更新緩存資料。
- CLI:CLI給用戶提供了執行查詢的命令列工具。Impala還提供了Hue、JDBC及ODBC使用介面。
5.3 Impala查詢執行過程
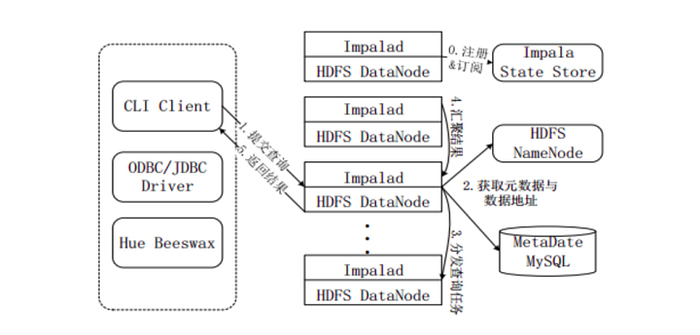
- 註冊和訂閱。當用戶提交查詢前,Impala先創建一個Impalad進程來負責協調用戶端提交的查詢,該進程會向State Store提交註冊訂閱資訊,State Store會創建一個statestored進程,statestored進程透過創建多個執行緒來處理Impalad的註冊訂閱資訊。
- 提交查詢。透過CLI提交一個查詢到Impalad進程,Impalad的Query Planner對SQL語句解析,生成解析樹;Planner將解析樹變成若干PlanFragment,發送到Query Coordinator。其中PlanFragment由PlanNode組成,能被分發到單獨的節點上執行,每個PlanNode表示一個關係操作和對其執行優化需要的資訊。
- 獲取中繼資料與資料位址。Query Coordinator從MySQL中繼資料庫中獲取中繼資料(即查詢需要用到哪些資料),從HDFS的名稱節點中獲取資料位址(即資料被保存到哪個資料節點上),從而得到存儲這個查詢相關資料的所有資料節點。
- 分發查詢任務。Query Coordinator初始化相應的Impalad上的任務,即把查詢任務分配給所有存儲這個查詢相關資料的資料節點。
- 彙聚結果。Query Executor透過流式交換中間輸出,並由Query Coordinator彙聚來自各個Impalad的結果。
- 返回結果。Query Coordinator把匯總後的結果返回給CLI用戶端。
5.4 Impala與Hive
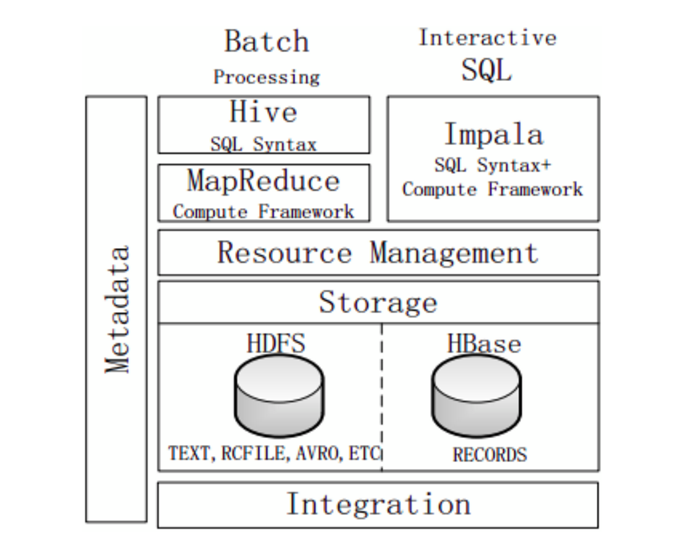
不同點:
Hive適合長時間批次處理查詢分析;而Impala適合進行互動式SQL查詢。
Hive依賴於MR計算框架,執行計畫組合成管道型MR任務模型進行執行;而Impala則把執行計畫表現為一棵完整的執行計畫樹,可更自然地分發執行計畫到各個Impalad執行查詢。
Hive在執行過程中,若記憶體放不下所有資料,則會使用外部存儲,以保證查詢能夠順利執行完成;而Impala在遇到記憶體放不下資料時,不會利用外部存儲,所以Impala處理查詢時會受到一定的限制。
相同點:
使用相同的存儲資料集區,都支援把資料存儲在HDFS和HBase中,其中HDFS支援存儲TEXT、RCFILE、PARQUET、AVRO、ETC等格式的資料,HBase存儲表中記錄。
使用相同的中繼資料。
對SQL的解析處理比較類似,都是透過詞法分析生成執行計畫。
原文連結:https://allaboutdataanalysis.medium.com/%E5%9F%BA%E6%96%BChadoop%E7%9A%84%E6%95%B8%E5%80%89hive%E5%9F%BA%E7%A4%8E%E7%9F%A5%E8%AD%98-ab063a310fd2
 groots
groots
