許多廠商、賣家都會想知道自己的商品上架到平台販售時,商品會排名在哪個位置?
大品牌廠商可能有經費每天派一名人力,定時去查找商品所在的排名;
要是小品牌或一般賣家不太會有經費或時間去做這樣的事。
這時就可以透過爬蟲程式,每天自動爬取想要查找的商品資訊,輕鬆、便宜又省事!
本篇會介紹當在蝦皮購物官網,搜尋關鍵字時,如何將所有資料一次蒐集完成。
程式碼相當簡單,共分為三段:import 套件、爬取資料(主要)、輸入關鍵字。
import 套件# 計算與轉換時間用
from datetime import datetime, timedelta
import time
from pytz import timezone,utc
# 爬蟲使用
import re
import requests
from bs4 import BeautifulSoup
import json
爬取資料(主要)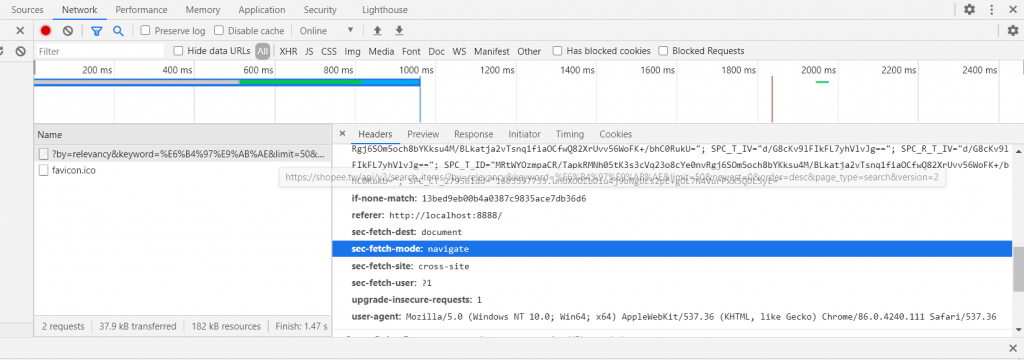
getShopeekey一路到parseItem)getShopeekey:會接到下一段程式使用者自行輸入的關鍵字parseAllList:先從一組網址中找到關鍵字搜尋後,總共被搜尋到的筆數,再根據筆數組成所有的商品列表網址。parseList:將每一項商品會在清單中顯示的資訊進行爬取(商品代號、名稱、促銷...)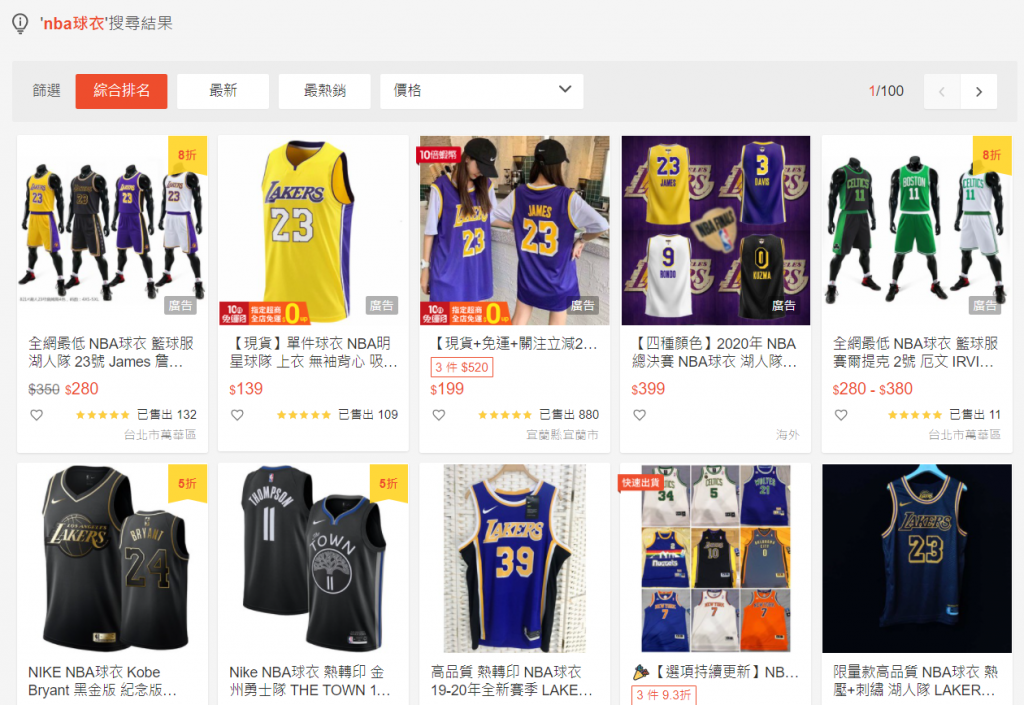
parseItem:最後會進到商品內頁,把更詳細的資訊爬取下來(價格、免運、庫存)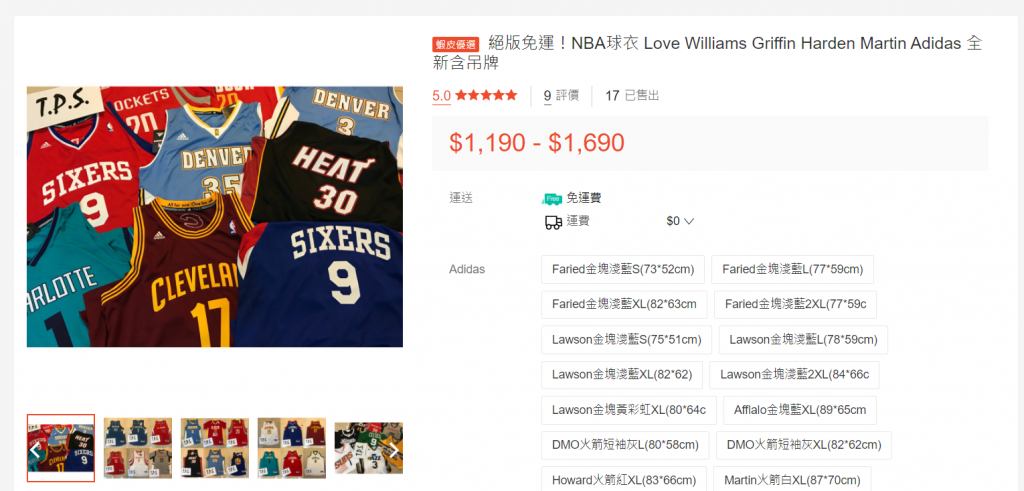
DOMAIN = 'https://shopee.tw/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36',
'referer': 'http://localhost:8888/'
}
def getShopeekey(keyword):
data={}
data['search_keyword'] = keyword
parseAllList(data, keyword)
def parseAllList(data, keyword):
ty_url = DOMAIN + 'api/v2/search_items/?by=relevancy&keyword={}&limit=50&newest=0&order=desc&page_type=search&version=2'.format(keyword)
resp = requests.get(ty_url, headers=headers).text
doc = json.loads(resp)
totalcount = doc['query_rewrite']['ori_totalCount']
total_pg = (totalcount // 50) + 1
doc['totalPage'] = total_pg
for num in range(0, total_pg):
pg_url = DOMAIN + 'api/v2/search_items/?by=relevancy&keyword={}&limit=50&newest={}&order=desc&page_type=search&version=2'.format(keyword, (num*50))
data['Page'] = num + 1
parseList(pg_url, data, num)
def parseList(pg_url, data, num):
print(pg_url)
resp = requests.get(pg_url, headers=headers).text
doc = json.loads(resp)
position = 0
count = 0
for i in doc['items']:
productid = i['itemid']
name = i['name']
shopid = i['shopid']
data['Brand'] =i['brand']
data['PrdCode'] = productid
article_url = DOMAIN + name + '-i.{}.{}'.format(shopid, productid)
data['url'] = article_url
promotion = []
if not i['ads_keyword'] == None:
promotion.append('廣告')
if not i['add_on_deal_info'] == None:
promotion.append(i['add_on_deal_info']['add_on_deal_label'])
if int(i['show_discount']) > 0:
promotion.append('折扣')
if i['service_by_shopee_flag'] > 0:
promotion.append('24h快速到貨')
if num == 0: position = position + 1
else:
count = count + 1
position = (num * 50) + count
data['position_section'] = position
data['position_total'] = data['position_section']
parseItem(shopid, productid, promotion, data)
def parseItem(shopid, productid, promotion, data):
pg_url = DOMAIN + 'api/v2/item/get?itemid={}&shopid={}'.format(productid, shopid)
time.sleep(1)
resp = requests.get(pg_url, headers=headers).text
doc = json.loads(resp)
flavor = 0
if not len(doc['item']['models']) == 0:
for i in doc['item']['models']: flavor = flavor + 1
data['Description'] = doc['item']['name']
data['like'] = doc['item']['liked_count']
data['rating'] = doc['item']['item_rating']['rating_star']
data['review_count'] = doc['item']['cmt_count']
data['sold_unit'] = doc['item']['historical_sold']
if not doc['item']['bundle_deal_info'] == None: promotion.append(doc['item']['bundle_deal_info']['bundle_deal_label'])
if doc['item']['shopee_verified'] == True: promotion.append('蝦皮優選')
if doc['item']['show_official_shop_label'] == True: promotion.append('商城')
data['promotion_tag'] = promotion
if doc['item']['is_official_shop'] == True:
data['subchannel'] = '購物商城'
if doc['item']['show_free_shipping'] == True:
data['delivery'] = '免運費'
else:
data['delivery'] = '需運費'
data['Selling_price'] = str(doc['item']['price_max'])[:-5]
data['List_price'] = str(doc['item']['price_min_before_discount'])[:-5]
if data['List_price'] == 0: data['List_price'] = str(doc['item']['price_max'])[:-5]
crawler_tm = datetime.now(tz=timezone('Asia/Taipei'))
data['rtime'] = datetime.strftime(crawler_tm, '%Y-%m-%d %H:%M:%S')
if not flavor == 0:
for i in range(0, flavor):
data['option_flavor'] = doc['item']['models'][(i)]['name']
data['List_price'] = str(doc['item']['models'][(i)]['price'])[:-5]
print(data)
else:
data['option_flavor'] = ""
print(data)
輸入關鍵字最後只要在這邊輸入想要搜尋的關鍵字,就可以開始爬取資料啦!
keyword = input("請輸入關鍵字:")
getShopeekey(keyword)

爬取到的資料會呈現這項商品不同的型號、價格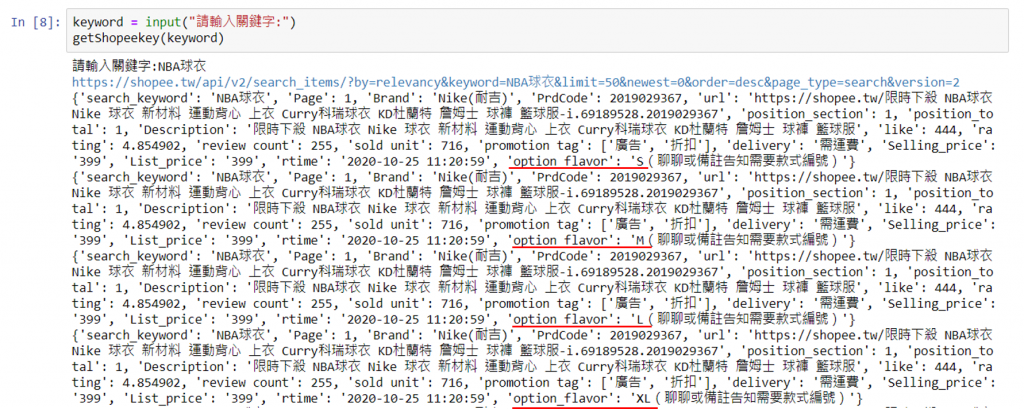
貼心提醒: 在 print(data) 部分可以改成匯入 DB 或 CSV 檔案中!
我放在colab執行,出現
resp = requests.get(ty_url, headers=headers).text
27 doc = json.loads(resp)
---> 28 totalcount = doc['query_rewrite']['ori_totalCount']
29 total_pg = (totalcount // 50) + 1
30 doc['totalPage'] = total_pg
KeyError: 'query_rewrite'
 wesley41616
wesley41616
