通常資料集特徵下的資料數值多分布在不同的範圍,這對依賴距離(distance)來進行機器學習的演算法而言是一大問題,因此依慣例,我們會將特徵下的資料值設定在相同的範圍。
特徵縮放(Feature Scaling)就是正規化獨立變數數值的範圍,也就是將特徵下的資料值設定在相同的範圍。
特徵縮放(Feature Scaling)的重要性:
變數數值的範圍會直接影響迴歸係數(regression coefficient)
擁有較顯著較大範圍的變數會支配較小範圍的變數
當特徵都在相似的範圍,Gradient decent收斂的速度較快
特徵縮放有助降低發現SMVs的支撐向量(support vectors)的時間
Euclidean distances會隨特徵大小波動
不需要特徵縮放的機器學習演算法是依靠規則(rule)的演算法,他們不會被任何變數的單調轉換影響,(縮放(Scaling)是單調轉換),這類演算法是樹狀基礎的(tree-based)演算法,例如 Classification and regression trees (CART), Random Forests, Gradient Boosted Decision Trees。
正規化的方法:
6.1 Standardisation(標準化)
6.2 Min-Max Scaling
6.3 Maximum Absolute Scaling
6.4 Robust Scaling
6.5 Mean normalisation
6.6 Scaling to unit length
這個方法是將資料值減掉平均值再除以標準差,標準化後,變數下的資料平均值等於0,標準差等於1(變異數等於1)。這個方法保存了原始資料的分布型態,如果有異常值,異常值也會被保留。適合用在常態分布的資料,對於不是常態分布資料,這不適最好的工具。
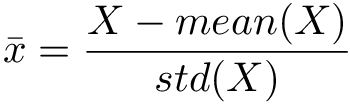
以kaggle的Titanic資料集為例,使用scikit-learn:
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler,MinMaxScaler
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
%matplotlib inline
# load the numerical variables of the Titanic Dataset
data = pd.read_csv('../input/titanic/train.csv', usecols = ['Pclass', 'Age',
'Fare',
'Survived'])
data.describe()
data.isnull().sum()
X_train, X_test, y_train, y_test = train_test_split(data[['Pclass', 'Age',
'Fare']],
data.Survived,
test_size=0.3,
random_state=0)
X_train.shape, X_test.shape
X_train.Age.fillna(X_train.Age.median(), inplace=True)
X_test.Age.fillna(X_train.Age.median(), inplace=True)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
也稱為Min-Max normalisation,它是將資料值減掉最小值再除以資料間距,資料間距是資料最大值減掉最小值,所以變數值收放至0到1,這個方法可能不會維持原始資料的分布型態,且會受異常值影響。適用在標準差較小和不是常態分布資料。

minmaxscaler = MinMaxScaler() # create an object
X_train_scaled = minmaxscaler.fit_transform(X_train)
X_test_scaled = minmaxscaler.transform(X_test)
這個方法將變數資料值除以變數的最大值,所以變數值會收放至-1到1之間,縮放後的平均值不會是位於數據的中間,變異數也不會被縮放,這個方法會受異常值影響。

maxscaler = MaxAbsScaler() # create an object
X_train_scaled = maxscaler.fit_transform(X_train)
X_test_scaled = maxscaler.transform(X_test)


 iThome鐵人賽
iThome鐵人賽