Data Catalog 由 Classifiers、Crawlers、Tables 組成
首先介紹 Classifiers,Classifiers 負責定義所要爬取的資料類型與內容格式,如下圖所示有 XML、JSON、CSV,而 Grok 是指自定義的資料內容格式
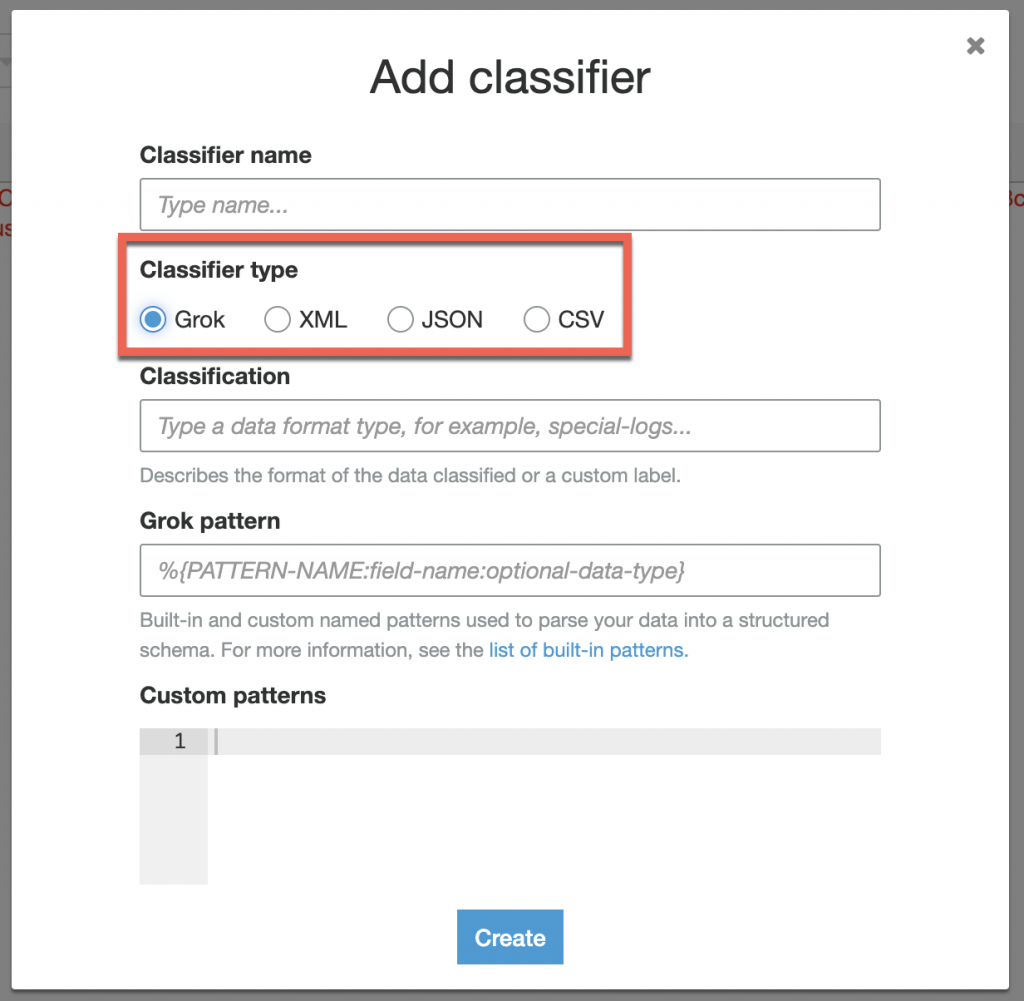
a. Grok 設定
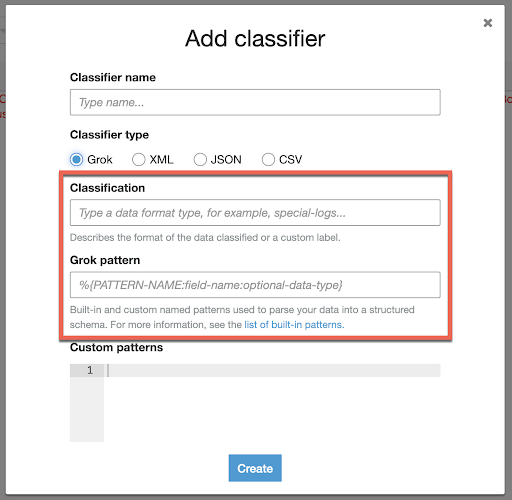
Classifcation:資料內容的說明,例如 Apache-Log
Grok pattern:用於描述一行的資料內容
假設資料內容如下192.168.131.39:2817 "app/test/a.jpg" 2020-07-02T22:23:00.186641Z
Grok pattern 的內容可以如下%{DATA:client}\s+\"%{DATA:request}\"\s+%{TIMESTAMP_ISO8601:timestamp_response}
pattern 中的 %{DATA:client} 代表著第一個欄位,DATA 代表這個欄位的正則表達式.*? ,client 代表欄位名稱,%{TIMESTAMP_ISO8601:timestamp_response} 代表第二個欄位,TIMESTAMP_ISO8601 代表這個欄位的時間格式,正則表達式的寫法為 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}? TZ (?:[PMCE][SD]T|UTC),timestamp_response則是此欄位名稱,而兩個欄位中間的 \s+ 則代表著一個空白或多個空白
Classifiers 有提供常見的正則表達式的規則,下圖為可以直接使用的 pattern,還有更多AWS已經定義好的 pattern 可以參考此連結

b. XML 設定
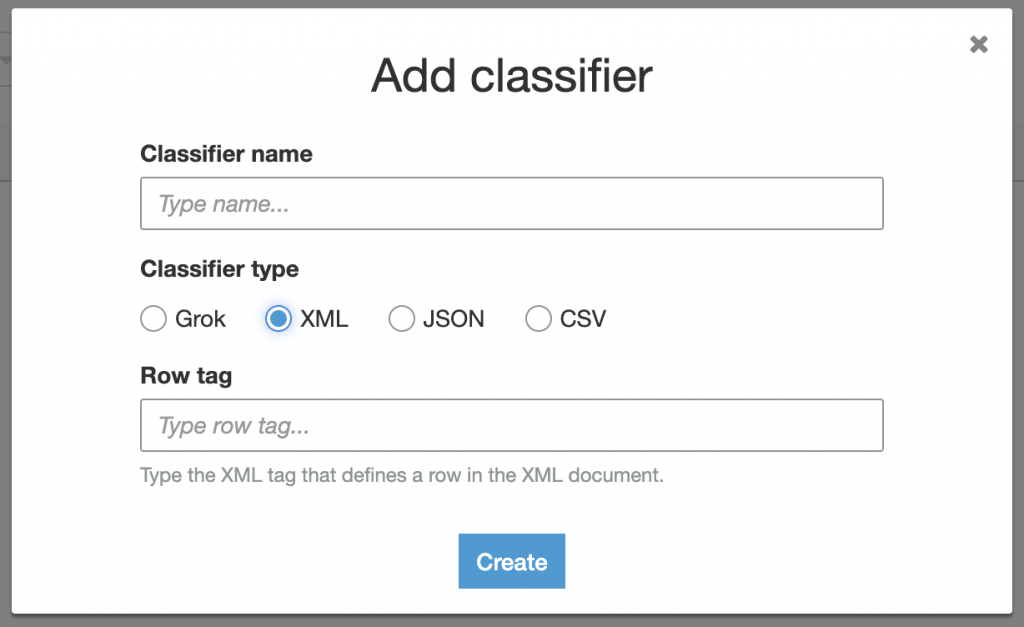
Row tag:設定要爬取的 XML Tag
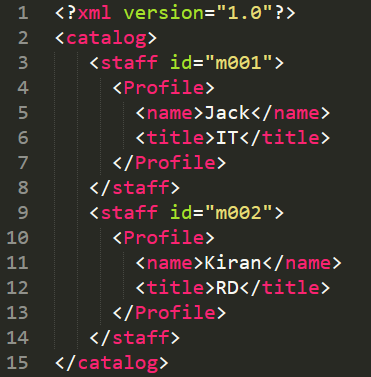
假設 XML 資料如下圖所示,我們可以指定 Profile 中的資料進行爬取,name 會代表第一個欄位名稱,Jack 會是此欄位的第一筆資料,Kiran 則會是此欄位第二筆資料。


 iThome鐵人賽
iThome鐵人賽