目前主要的深度學習架構裡,人類要擔心的重點只有一個:「Gradient Descent」(梯度下降)。我們可以把深度學習想像成有一百萬個學生同時在寫答案,他們每個人都有不同的思考方式,最後每個人都交出一個不同的答案(一個數字)。將所有的答案跟標準答案相減之後(技術上稱為 loss),畫成一條折線圖(或是複雜一點的 3D 圖),離標準答案最接近的那個答案,就會在這張圖的最低點,深度學習的目標就是要找到這個最低點。
梯度下降
梯度下降指的是,神經網路為了找到適合的權重和偏差值使損失函數的偏差值越來越小,而尋找參數的過程稱為(學習),梯度下降是最常用的優化演算法,透過計算梯度,沿著梯度的反方向移動,就像網路參數透過梯度下降得到優化,逐步的降低loss,找到區域的最小的loss,使預測的結果接近預期的輸出。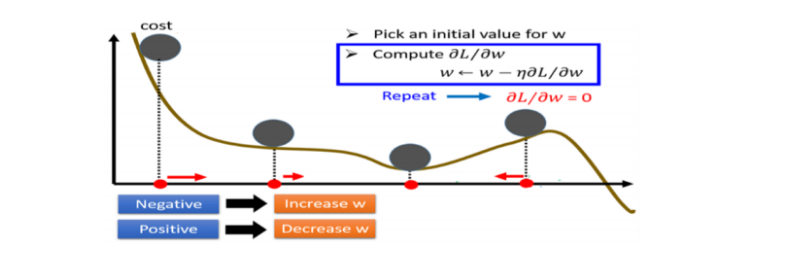
損失函數
損失函數(Loss fuction) 是用來計算模型預測值與預期輸出之間的相似程度,並在訓練過程中需要將預測值與輸出的相似程度最小化。
為什麼是最小化
在回歸的問題中,我們通常希望模型能預測出來的東西可以跟實際的值一樣。但現實是不可能預測出的值跟實際值是一樣的,預測出來的東西基本上跟實際值都會有落差,這個落差在統計上稱為「殘差」。
換個角度解釋,如果我是做股票預測模型,我們預測指數應該到10000點,結果實際是11000點,中間差了1000點,如果我們照著模型去投資,我們是不是損失了1000點的差異,所以應該不會有人用「我們模型跟實際值有1000點的殘差」來解釋吧。
所以損失函數中的損失就是實際值和預測值的差值。
今天只做最初度的介紹,明天會著重在說損失函數MSE、MAE
參考:
https://medium.com/@chih.sheng.huang821/%E6%A9%9F%E5%99%A8-%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92-%E5%9F%BA%E7%A4%8E%E4%BB%8B%E7%B4%B9-%E6%90%8D%E5%A4%B1%E5%87%BD%E6%95%B8-loss-function-2dcac5ebb6cb

