了解 Classifiers 後,要來介紹如何將 Classifiers 與 Crawlers 結合進行資料爬取
Crawlers 的部分會以一個小範例進行說明,首先我們要到 Kaggle 取得範例資料,資料內容為零售業的歷史訂單資料
這次我們先以處理 orders.csv 這個資料為目標,並且可以對他進行查詢
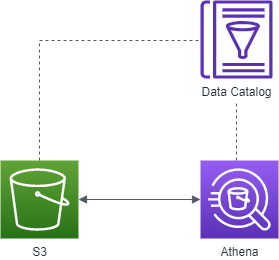
架構如下,資料儲存在 S3 再透過 Data Catalog 對 S3 上的資料進行爬取與解析,解析完成後再透過 Athena 使用 SQL 的查詢語法對資料進行分析
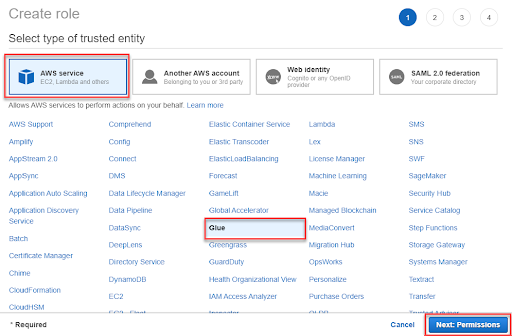
1-2. 選擇要使用 Role 的服務 Glue
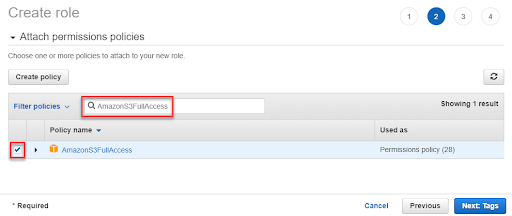
1-3. 給予 Role 所需的 Policy,AmazonS3FullAccess、AWSGlueServiceRole,除了 Glue 本身的權限之外,因為資料是儲存在 S3 當中所以還要給予 S3 的權限,讓 Glue 可以存取所需的資料
1-4. Tag 的部分可以先跳過
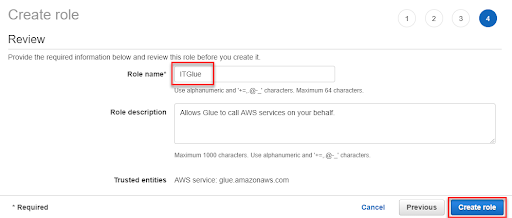
1-5. 最後幫 Role 取一個好名子就完成了
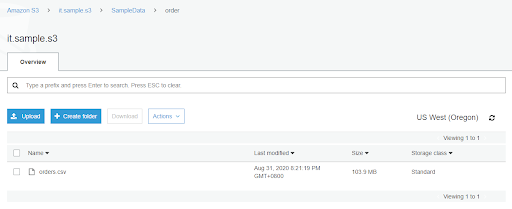
2-2. 請依照以下階層創建資料夾並放入剛剛從 Kaggle 下載的 orders.csv
SampleData
└─ order
└─ order.csv
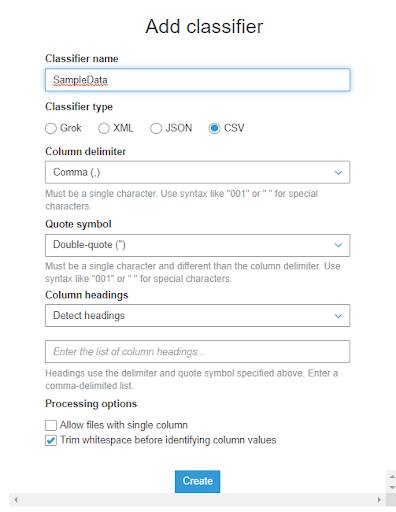
order.csv 是 CSV 檔,而他的主要分隔符號是使用逗號,次要分而符號沒有使用到但我們還是先選則雙引號做為次要分隔符號,欄位名稱的部分因為資料中已有,所以 Column headings 可以選擇 Detect headings 或是 Has headings,其他部分則是使用默認設定即可



 iThome鐵人賽
iThome鐵人賽