提出前人的問題(蠻困難的,不論是觀察出來跟說出來)
Obviously, the strategy in Ciresan et al. [1] has two drawbacks.
從別人的文章中看到兩個缺點。
First, it is quite slow because the network must be run separately for each patch, and there is a lot of redundancy due to overlapping patches.
Secondly, there is a trade-off between localization accuracy and the use of context.
window大小與精確度的權衡。
Larger patches require more max-pooling layers that reduce the localization accuracy, while small patches allow the network to see only little context.
More recent approaches [11,4] proposed a classifier output that takes into account the features from multiple layers.
最近的一種分類器,考慮了多層的輸出,未看先猜可能是densenet 或者是 resnet。
Good localization and the use of context are possible at the same time.
所以可能可以同時考慮周圍的pixel又能提升準確度。
[4] Hypercolumns for Object Segmentation and Fine-grained Localization
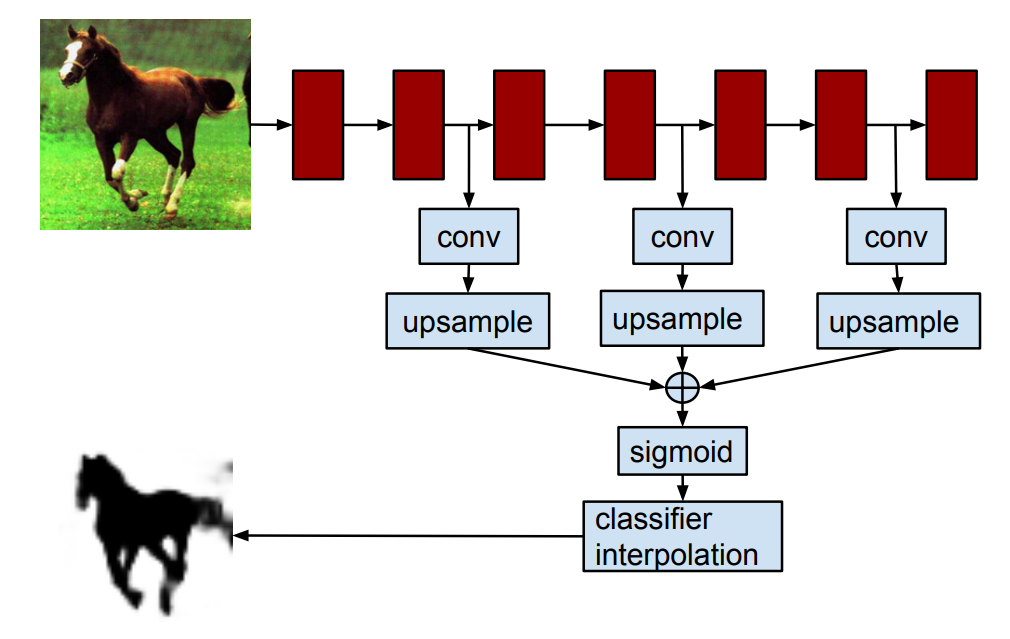
這篇文章提出了一個問題,一般的CNN最後一層就只有語意資訊,但是將每一層convolution 後的feature做 upsample(有點類似反卷積),可以萃取不同尺度的特徵。
[11] Image segmentation with cascaded hierarchical models and logistic disjunctive normal networks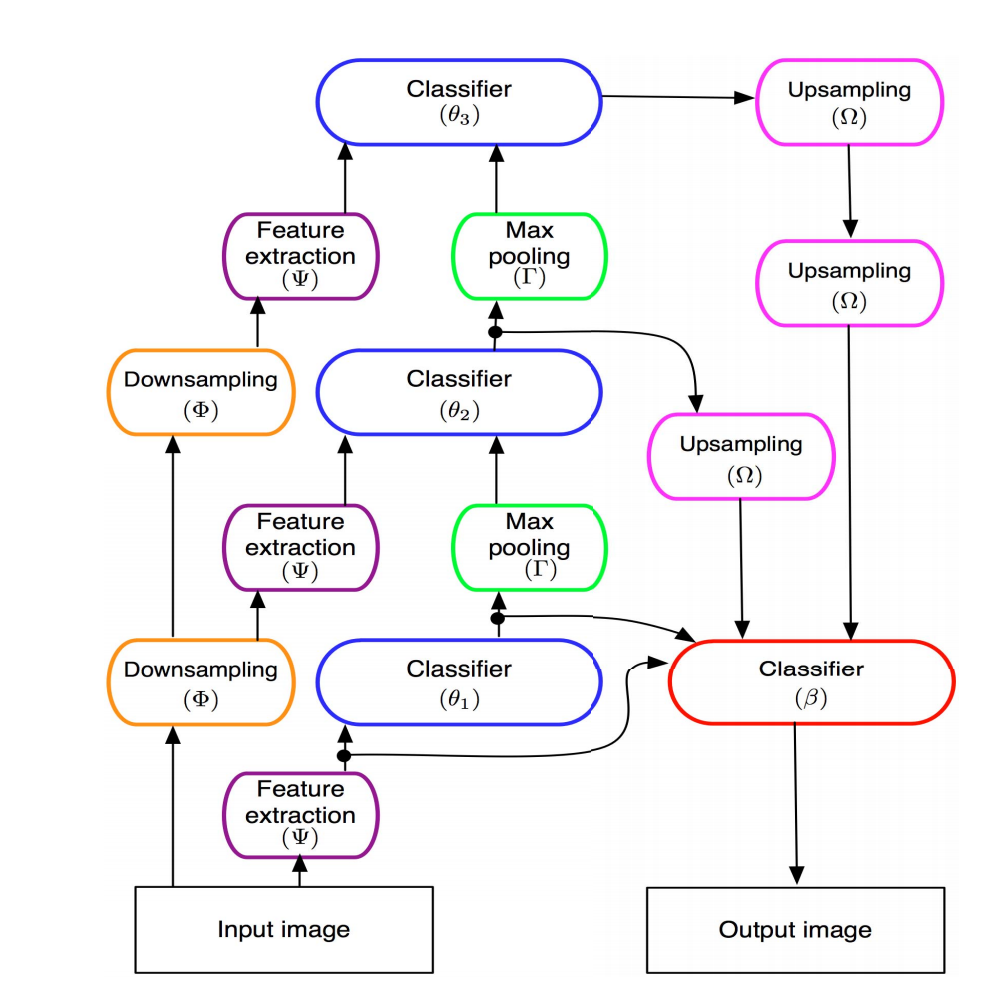
這一張不明所以的圖,簡單來說就是萃取不同尺度的特徵與upsample組成,沒一個階段都有分類的成果,分類的成果又能當作分類的特徵,中間又有Max pooling。
Densenet與Resnet應該受這兩篇啟發很大([4],[11]),[4]比較偏向將中間的特徵拿出來利用的概念;[11]比較偏向實際應用,但是並沒有將技術說明得很簡潔。果然簡單但是實用的東西才會傳播。
[4] Hypercolumns for Object Segmentation and Fine-grained Localization
[11] Image segmentation with cascaded hierarchical models and logistic disjunctive normal networks

