稍微的說明了一下U-net 想法是從哪裡來的。
In this paper, we build upon a more elegant architecture, the so-called “fully convolutional network” [9].
全卷積架構,就是全部都是卷積層,卷積可以細分為"卷積"與"反卷積"。
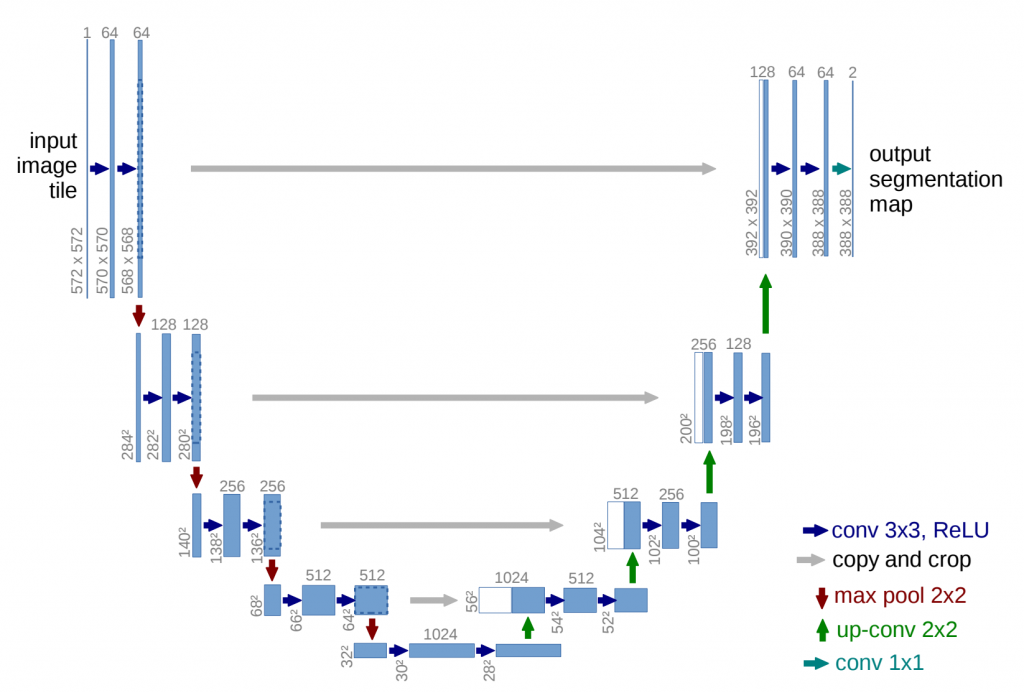
We modify and extend this architecture such that it works with very few training images and yields more precise segmentations; see Figure 1.
可以用很少的去做精確的分割,因為萃取了很多不同的特徵。
The main idea in [9] is to supplement a usual contracting network by successive layers, where pooling operators are replaced by upsampling operators.
利用upsample取pooling,所以解析度會變大。
Hence, these layers increase the resolution of the output.
輸出的解析度也會變大(目的是為了還原解析度)。
In order to localize, high resolution features from the contracting path are combined with the upsampled output.
並且將同解析度影像合併。
A successive convolution layer can then learn to assemble a more precise utput based on this information.
使得連續的卷積可以學習更精確的特徵。
[9] Fully Convolutional Networks for Semantic Segmentation
這篇是Fully convolution network的始祖吧?直接改自Alexnet,將隱藏層改為upsample層。
我認為U-net就是不斷的萃取特徵與利用特徵來達到利用比較少的樣本訓練的成效,但是其實也是有特徵重複利用的問題,但是只少這樣可以找到相對較好的特徵。
[9] Fully Convolutional Networks for Semantic Segmentation
[0] U-net

