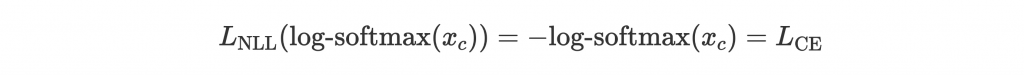MNIST 是早在 1998 年就釋出的手寫數字辨識 dataset。因為他資料量小、架構簡單就能訓練,因此被視為 deep learning 界的 hello world 專案。各大 framework 也都以他作為實作入門的教學。
讓我們也從這個簡單的專案入門吧!Code 參考自 PyTorch MNIST example。
首先定義 network。記得三步驟是:繼承 Module class、overwrite __init__()、 和 overwrite forward():
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Conv2d(1, 32, 3)
self.dropout = nn.Dropout2d(0.25)
self.fc = nn.Linear(5408, 10)
def forward(self, x):
x = self.conv(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = torch.flatten(x, 1)
x = self.fc(x)
output = F.log_softmax(x, dim=1)
return output
我們用了一層 convolution layer 和 pooling layer 來擷取 image 的 feature,之後要把這些 feature map 成 10 個 node 的 output(因為有 10 個 class 要 predict),所以用 flatten 把 feature 集中成 vector 後,再用 fully-connected layer map 到 output layer。b 是 batch size,一次 train 幾張 image。
架構圖大概長這樣:

大概了解各層怎麼對應到 code 就好,convolution 和 pooling layer 是什麼、以及 layer 的參數為什麼設成那些數字,之後介紹 Computer Vision 的時候會細講。
這邊注意到 return 之前我們對 output layer 取 log-softmax,而下面寫到取 loss 的時候是取 negative log-likelihood loss。記得我們前面介紹做 multiclass classification 的時候,說了會對 output 做 softmax 取得 probability,然後對 label 取 cross entropy loss 嗎?那這邊的做法怎麼不一樣?
請先回想我們在 Day 3 的時候解釋過 cross entropy loss
,而
是 softmax 出來的結果。因此
。
而 PyTorch 的 NLLLoss 在這邊會等於
,也就是說以
為 NLLLoss 的 input 的話,
所以數學上 log-softmax + negative log-likelihood 會等於 softmax + cross-entropy。不過在 PyTorch 裡 cross-entropy 因為 input 是 output layer 的值而不是 softmax 後的 probability,所以其實內部也在做 log-softmax + nll,也不用先 softmax。
那取 log-softmax 的好處是什麼?一是 numerical stability,因為 log 會把原本 softmax 出來在 [0, 1] 範圍的值對應到 [0,
),也就是範圍大大增加了,而因為 Python 處理小數點在精準度方面有極限,所以能夠把值映射到大一點的範圍可以避免超越精準度的極限。二是直接取 log-softmax 在運算上能夠優化,增快速度。
再來是 training function:
def train(model, train_loader, optimizer, epochs, log_interval):
model.train()
for epoch in range(1, epochs + 1):
for batch_idx, (data, target) in enumerate(train_loader):
# Clear gradient
optimizer.zero_grad()
# Forward propagation
output = model(data)
# Negative log likelihood loss
loss = F.nll_loss(output, target)
# Back propagation
loss.backward()
# Parameter update
optimizer.step()
# Log training info
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
首先注意到因為 training 和 testing 時 model 會有不同行為,所以用 model.train() 把 model 調成 training 模式。
接著 iterate 過 epoch,每個 epoch 會 train 過整個 training set。每個 dataset 會做 batch training。
接下來就是重點了。基本的步驟:clear gradient、feed data forward、取 loss、back propagation 算 gradient、最後 update parameter。前面都介紹過了,還不熟的可以往前翻。
最後每隔幾個 batch 就會 log 一次現在的 loss 和進度,方便查看和分析。
Testing function 也大同小異,不同的是會用 model.eval() 設成 testing / evaluation mode、會 disable gradient 的計算以增快速度、以及計算 prediction accuracy:
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad(): # disable gradient calculation for efficiency
for data, target in test_loader:
# Prediction
output = model(data)
# Compute loss & accuracy
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item() # how many predictions in this batch are correct
test_loss /= len(test_loader.dataset)
# Log testing info
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
with torch.no_grad()包起來的部分,PyTorch 負責 gradient 的 engine 就會進行優化,加快速度!
最後把 data loading、training、testing 合在一起:
def main():
# Training settings
BATCH_SIZE = 64
EPOCHS = 2
LOG_INTERVAL = 10
# Define image transform
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)) # mean and std for the MNIST training set
])
# Load dataset
train_dataset = datasets.MNIST('./data', train=True, download=True,
transform=transform)
test_dataset = datasets.MNIST('./data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=BATCH_SIZE)
# Create network & optimizer
model = Net()
optimizer = optim.Adam(model.parameters())
# Train
train(model, train_loader, optimizer, EPOCHS, LOG_INTERVAL)
# Save and load model
torch.save(model.state_dict(), "mnist_cnn.pt")
model = Net()
model.load_state_dict(torch.load("mnist_cnn.pt"))
# Test
test(model, test_loader)
Data loader 的部分,會先用 torchvision.transforms 這個 package 提供的工具,把 dataset 的 data 做 pre-processing。能做的事包括包成 tensor、resize、crop、normalization 等等。這邊我們做包成 tensor 和 normalization。
再來 PyTorch 有提供寫好的 MNIST Dataset class,我們就不用自己下載 dataset、load file、建立 Dataset class 了。如果要用自己的 dataset 就要自己處理了。
最後把 transform 和 dataset 整頓進 data loader。之後就開始 train 跟 test 了。
中間還有示範怎麼 save 和 load model,其實這邊 train 跟 test 同個 file 的情況下不需要,但如果是分開來就會在 train file 做 saving、test file 做 loading。
差不多這樣就能訓練出一個手寫辨識 model 了。
來看看這個簡易的 model 成果如何:

—— Accuracy。
訓練兩個 epoch 後,在 test set 上的準確率就能有 98% 了。
再來看看訓練時的 loss:

—— Training loss。
很快在前幾輪就訓練得滿好的,之後 loss 也持續下降。
有興趣的還能看看 test set 是哪些 input 辨識錯誤,或想辦法讓準確率更高!不過記得要 tune hyper-parameter 的話,要從 training set 分出 validation set 來改進 model,不要直接用 test set 來 evaluate,否則會 overfit test set。
原始碼都放在 GitHub:pyliaorachel/knock-knock-deep-learning。
with torch.no_grad() 功能和用意為何?