已經快要想不出有趣的標題了,從昨天的文章中應該就知道,最後的幾天的內容相對會比較繁瑣枯燥,而且會以觀念為主。在今天和明天的文章中,我們要來思考的問題是,到底應該如何建構一個嚴謹的資料庫。這裡強調的是「嚴謹」,也就是資料庫在設計之初就應該要考量到,未來不管是詢輸入資料、當資料有大量變動、或是其他的狀態下,資料庫的架構和綱要(Schema, Database Schema) 得保持穩定。這裡我們會陸續介紹兩個重要的觀念: 第一個觀念叫做功能支配關係 (functional dependencies) 第二個觀念叫做資料庫正規化 (normal form)。我們將要運用這兩個概念幫助我們決定哪些資料要放在哪個表格、哪幾筆欄位又該當作主鍵(Primary Key)或是外部鍵 (Foreign Key) 就讓我們開始吧!
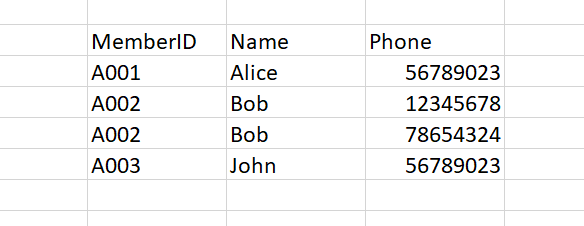
我看一下上面這一個關聯表,假設這是一個商店會員資料表。這個表有幾個問題: 首先,如果未來要修改 Bob 的姓名時,可能會不小心沒有改到兩筆中的一筆資料,使得資料不一致 (inconsistency) 。另外,如果我想要更新Bob 兩支手機中的一支手機的電話號碼,再用SQL選取的時候,可能會無法清楚分辨更新的是哪一支手機的數字。同樣的,從這個表中我們看到Alice跟John共用手機,所以如果想要把這支手機電話刪除,可能也會不知道咬把哪一筆資料刪掉,還是兩筆都要刪掉?
這個例子想要重申建構嚴謹的資料庫是非常重要的一件事情,雖然這個表格非常的簡單,但當我們處理真實世界中複雜的資料庫系統的時候,有時候沒有辦法設計出簡潔乾淨俐落而言盡的資料庫,就必須要仰賴理論來協助我們。這就是為什麼資料庫管理者會使用正規化的規定在資料庫設計之中。
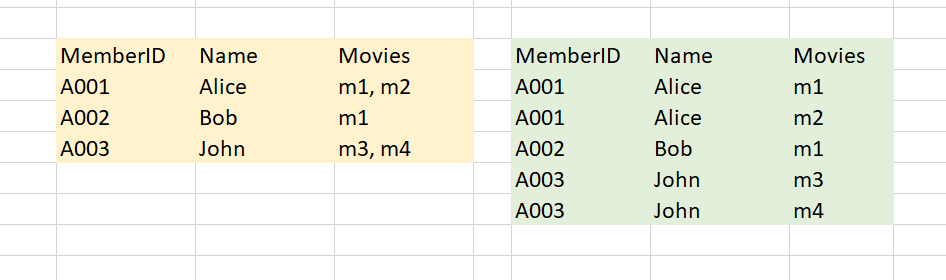
正規化其實就是給一個規則要求資料庫的表格要遵守。這些規則是大家都有共識,我們依照規則的嚴謹程度作區分。其中,最簡單也最直覺的正規化我們稱為: 第一正規化型式 (First Normal Form, 1NF)。這是所有正規化形式中,相對鬆散的設計。1NF 的要求是所有的欄位只能存在一筆資料,不可以是一個列表。讓我們看下面的例子。左邊的關係表存放的是每個會員喜歡看的電影,在1NF底下,我們就可以把電影的資料 "Unwind" 拆分開來。現在,拆開之後,在做SQL的查詢的時候就可以更輕易的做一些像是Group By 或是查找的動作。
雖然簡化了資料關聯表上黏在一起的數據,但是右邊的關聯表依然可能會造成混淆,而且依然有重複的數值,這樣之後維運的過程可能很難去做判讀。這時候我們就可以參考一下比較嚴格的另外一種正規化,叫做Boycee-Codd 正規化模型 (Boycee-Codd Normal Form, BCNF)。
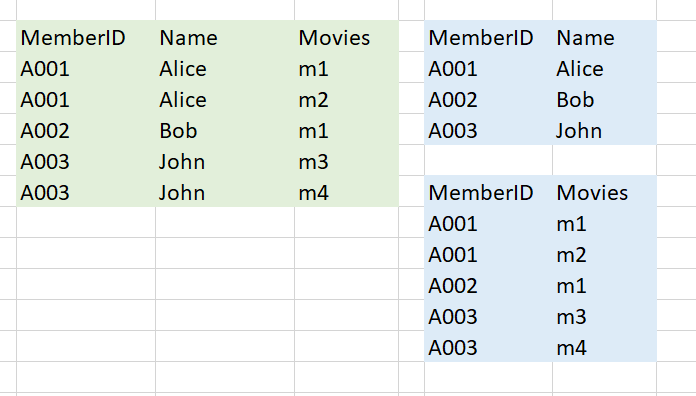
BCNF相較於 1NF 來說更嚴謹。這個規定中,資料除了外部鍵 (Foreign Key, FK) 以外都不可以出現重複的數值。重新回到剛剛的例子中,因為重複出現的部分是名字,所以這時候我就把這個表格拆成兩個表格: 一個表格只有會員編號和姓名、第二個表格是會員編號和他喜歡的電影。這時候你就會發現唯一重複的就只有會員編號也就是在這個兩個資料關聯表中的外部鍵。
當然,正規化的形式還有幾個,這邊我們就先點出兩個常見的 Normal Form。其他像是 3NF 第三正規化形式,又回有不同的規定。寫到這邊,最麻煩的部分就是,如果給你一個更複雜的資料庫,我怎麼知道哪些欄位可以當作外部鍵哪些欄位需要放到獨立的表格呢?這時候我們就要先來談功能支配關係 (functional dependencies)。
功能支配關係是一種限制。其功用是用來獨一無二的辨識另外一筆資料的關聯。讓我們看看下面這個例子:
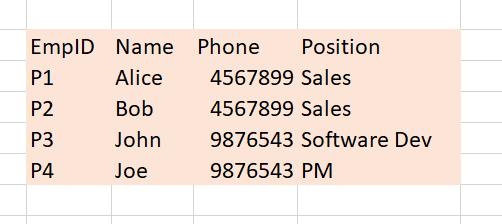
假設這是一張公司裡面的員工資料庫,由左至右的欄位分別是員工編號、姓名、員工的公司電話、還有他們的職稱。這時候,這張表我們可以說,當我擁有員工編號的時候,我就可以獨一無二的判斷員工姓名、電話、或是他的職稱,這時候我們就可以說員工編號支配了員工姓名、員工的工作電話、和員工的職稱 (EmpID functionally determines Name, Phone and Position),用數學式的方式表示就會用下面的這種。
EmpID --> {Name, Phone, Position}
當然在這張圖表之中不僅僅員工編號有有這樣的關係,就這張資料表來說我們也可以說員工的職稱支配了電話號碼。
Position --> {Phone}
所以其實你也可以想成是: 有哪些資料我拿到他就可以確定他只會一對一的指向另外的哪一個欄位中的資料。
在設計資料庫之初,資料庫的設計者應該要依照真實情況之中,他對這些資料的認識,去推出不同欄位之間的支配關係,了解這樣的關係之後我們就做出下面的定義:
在資料庫當中,可以完全支配所有欄位的資料,都可以作為鍵 (Key)
一個關係中,未必只有存在一個 Key,這就是我們會定義「主鍵」(Primary Key)。如果一個鍵與任何其他值綁在一起 (Superset) 當作鍵,我們就稱他為 Super Key (超級鍵)。
EmpID -- (Key)
(EmpID, Name) -- (Super Key)
但是剛剛上述的表格中就只有兩個支配關係嗎? 其實不是,我們也可以說
(Name, Phone, Position) --> EmpID
(Name, Phone) --> {EmpID, Position}
.
.
.
這麼多種排列組合的情況之下,我們就必須要有技巧的生成所有可能的排列組合,然後過濾掉不好的支配關係。幾個比較實用的規則如下:
當我們有 A1, A2, A3, ..., An -> B1, B2, B3, ..., Bm
我們可以把它拆解成
A1, A2, A3, ..., An -> B1
A1, A2, A3, ..., An -> B2
A1, A2, A3, ..., An -> B3
...
A1, A2, A3, ..., An -> Bm
左邊維持一樣拆右邊;左邊入世一樣可以加到右邊。
A1, A2, A3, ..., An -> A1
左邊的任意值必然被全體支配
如果 A1, A2, A3, ..., An -> B1, B2, B3, ..., Bm
而且 B1, B2, B3, ..., Bm -> C1, C2, C3, ..., Ck
就可以說 A1, A2, A3, ..., An -> C1, C2, C3, ..., Ck
今天不小心寫了很多,明天繼續解釋支配關係、正規化到建立資料關係表!

