歡迎來到第 11 天,今天要接續昨天寫到一半的 UN Career 爬蟲繼續努力。昨天解決了較棘手的分頁問題,今天要在處理另外兩個問題「分類」、「職缺名稱與連結」。
在頁面中可以看到五大分類,同樣的需要使用 Selenium 模擬人為點按的方式進入到下一個分類。我們可以將昨天的程式碼做一些簡單的修改,由於分類總數是固定的,因此可以使用 range(5) 直接作為 for loop 的區間,並記得 click 並不會等到頁面完成讀取才進行下一行的程式碼執行,所以要特別注意在 click 後要加上 WebDriverWait,最後結合昨天的程式碼。
直接執行的時候會發現,又出現 IndexError: list index out of range 的錯誤,這是為什麼呢!?仔細觀察才發現,並不是每個分類都有多頁的職缺,因此要修改 while True 變成 while elements 確定真的有多個分頁的時候才進行這個迴圈。
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
def page_spyder(driver):
page = 1
indexer = 0
timeout = 5
elements = driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")
while elements: # 確認有多個分頁才跑
if elements[indexer].text == str(page+1) or (elements[indexer].text == "..." and indexer>3):
driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")[indexer].click()
element_p = EC.presence_of_element_located((By.CLASS_NAME, 'pager'))
WebDriverWait(driver, timeout).until(element_p)
elements = driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")
page +=1
indexer = 0
elif indexer+1 == len(elements):
break
else:
indexer += 1
driver = webdriver.Chrome(executable_path = 'Path to webdriver')
url = "https://careers.un.org/lbw/home.aspx?viewtype=SJ&exp=All&level=0&location=All&occup=0&department=All&bydate=0&occnet=0&lang=en-US"
driver.get(url)
for i in range(5):
driver.find_elements_by_xpath("//span[@class = 'rtsTxt']")[i].click()
element_p = EC.presence_of_element_located((By.CLASS_NAME, 'rtsTxt'))
WebDriverWait(driver, 5).until(element_p)
page_spyder(driver)
好的,這時候既完成了分類的切換也完成了分頁的切換,基本上已經走完了所有的職缺,最後一步就是完成擷取職缺名稱和連結,觀察職缺的 html 會發現,他的 <a> 並不是簡單的連接到該職缺的 URL,而是透過 onclick 驅動 Js code 進行頁面的跳轉,但在往細節觀察會發現 Js code 中包含著該職缺的 URL,因此我們還是可以透過一些簡單的拆解將目標網址給解析出來。
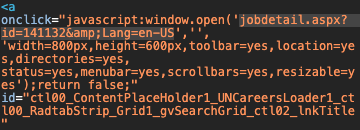
def title_url_extract(driver):
jobs = {}
tr_tags = driver.find_elements_by_xpath("//table[@class='sch-grid-standard']/tbody/tr[not(@class)][not(@align)]/td/a[1]") # 定位出每個職缺的標籤
for job in tr_tags:
jobs[job.text] = "https://careers.un.org/lbw/"+job.get_attribute("onclick").split("'")[1]
return jobs
這樣就完成全部的問題,接下來合併所有的程式碼,並測試看看吧!
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
def page_spyder(driver):
page = 1
indexer = 0
timeout = 5
jobs = {}
elements = driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")
jobs = {**jobs,**title_url_extract(driver)}
while elements: # 確認有多個分頁才跑
if elements[indexer].text == str(page+1) or (elements[indexer].text == "..." and indexer>3):
driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")[indexer].click()
element_p = EC.presence_of_element_located((By.CLASS_NAME, 'pager'))
WebDriverWait(driver, timeout).until(element_p)
jobs = {**jobs,**title_url_extract(driver)}
elements = driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")
page +=1
indexer = 0
elif indexer+1 == len(elements):
break
else:
indexer += 1
return jobs
def title_url_extract(driver):
jobs = {}
tr_tags = driver.find_elements_by_xpath("//table[@class='sch-grid-standard']/tbody/tr[not(@class)][not(@align)]/td/a[1]") # 定位出每個職缺的標籤
for job in tr_tags:
jobs[job.text] = "https://careers.un.org/lbw/"+job.get_attribute("onclick").split("'")[1]
return jobs
driver = webdriver.Chrome(executable_path = 'Path to webdriver')
url = "https://careers.un.org/lbw/home.aspx?viewtype=SJ&exp=All&level=0&location=All&occup=0&department=All&bydate=0&occnet=0&lang=en-US"
driver.get(url)
jobs = {}
for i in range(5):
driver.find_elements_by_xpath("//span[@class = 'rtsTxt']")[i].click()
element_p = EC.presence_of_element_located((By.CLASS_NAME, 'rtsTxt'))
WebDriverWait(driver, 5).until(element_p)
jobs = {**jobs,**page_spyder(driver)}
今天就到這邊,明天見。


 iThome鐵人賽
iThome鐵人賽