在「簡介」時老頭曾經提到,有一個好的模型縮放公式還不夠,必須搭配一個好的 Baseline Model ,才能設計出好的擴充新模型。
作者參考了 MingXing Tan 等人的論文「MnasNet: Platform-Aware Neural Architecture Search for Mobile」(註一)利用「 multi-objective neural architecture search」方法來找出最佳的 Baseline Model。
作者使用了和 MingXing Tan 論文內相同的搜尋空間 (search sapce)。
最佳化的標的為「精確度 (ACC) 」及「運算量 (FLOPS)」,公式為:
其中 ACC(m) 代表模型 m 的精確度,FLOPS(m) 代表模型 m 所需之運算量,T是目標運算量(設為 400M),而 w = -0.07。
找出來的模型,即是 EfficientNet-B0,它的結構如下: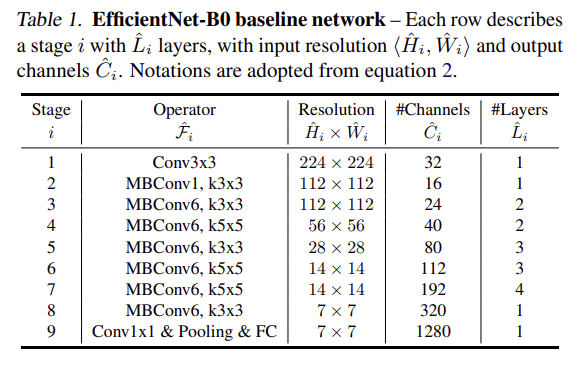
EfficientNet-B0 是由 MBConv (Mobile Inverted Bottleneck ConvNet, 註二) 並加上
squeeze-and-excitation optimization(註三)為基本模塊組合而成。
接著作者以 EfficientNet-B0 為 Baseline Model,並將縮放係數 φ 定為 1 (將 Baseline Model 擴充 1 倍),執行小規模的網格搜尋,去找適當的 α, β, γ 值。結果為 α = 1.2, β = 1.1, γ = 1.15。
然後,就以找出來的 α, β, γ 值,依序產生 EfficientNet-B1 到 EfficientNet-B7 (縮放係數 φ 設為 1 到 7)。作者在論文中特別提到,他們最後用的 α, β, γ 值,是 B0 到 B1 的擴充過程中找到的,理論上,也可以分別去找各個階段擴充時的最佳值 (例如由 B1 到 B2 是再搜尋一次),但是隨著模型逐漸變大,這種搜尋所需之時間及運算也將指數式的放大,而變得不可行。所幸沿用 B0 到 B1 的值,所得到的 EfficientNet 系列已能展現出良好的效能。
所產生的模型列表如下。要注意的是最右邊一欄 EfficientNet-L2,在論文中並沒有提到這一個巨大的 EfficientNet,它是後來產生的。前幾天在「EfficientNet 1:源起」中提到的 ImageNet 排名第一的 FixEfficientNet-L2 就是它的變形。
模型產生出來了,接下來就要看看他們的效能到底好到什麼程度了!
(註一:論文 arXiv 號碼 1807.11626 https://arxiv.org/abs/1807.11626 )
(註二:參考
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. CVPR, 2018
Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., and Le, Q. V. MnasNet: Platform-aware neural architecture search for mobile. CVPR, 2019 )
(註三:參考
Hu, J., Shen, L., and Sun, G. Squeeze-and-excitation networks. CVPR, 2018 )

