為了驗證複合式模型縮放和它的 α, β, γ 參數值是否有效,作者將 MobileNets (MobileNetV1 及 MobileNetV2)和 ResNet 分別用一維度放大及「複合式模型縮放」來放大它們,並比較放大後的模型效能,結果看起來,複合式模型縮放這個方法是有效的。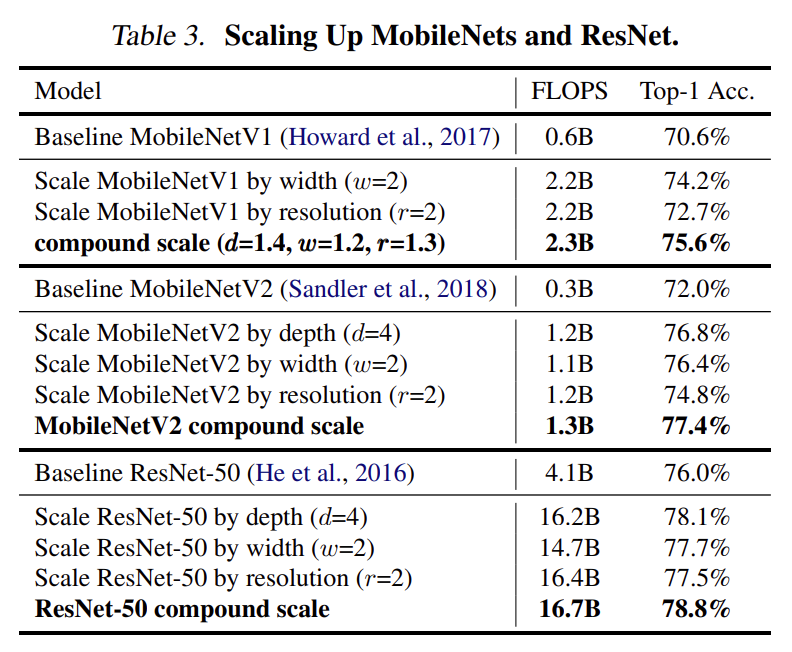
在上表中,作者並沒有標示 MobileNetV2 和 RestNet-50 兩者的複合縮放尺度 (compound scale) ,不過從 FLOPS 的增加比例上來看,它們應該是和 MobileNetV1 使用相同的參數 (d=1.4, w=1.2, r=1.3)。
作者將 EfficientNet 系列模型放在 ImageNet 上,利用下列的方式訓練各模型:
訓練時,作者由訓練資料集 (Training Set) 中保留了 25K images 作為 Early Stopping 的檢驗資料集 (Validation Set),並且在 Early Stop 時用 ImageNet 既有的檢驗資料集來計算檢驗精準度 (Validation Accuracy)。老頭並不了解作者為何要這樣做,需要深入的探討。
精確度測試的結果如下: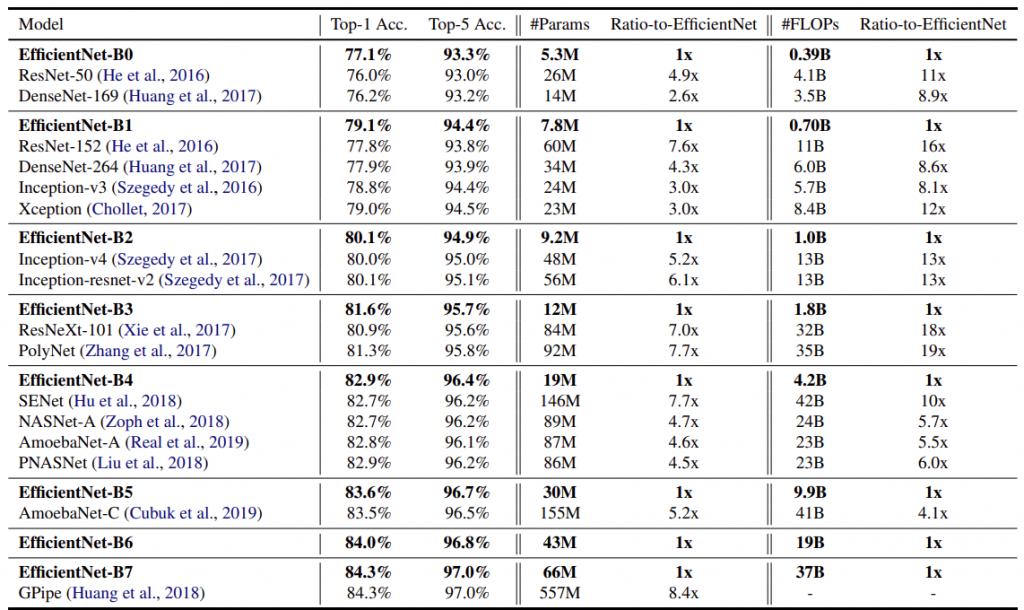
在上面的表格中,作者將 EfficientNet 和精確度類似的其他模型相比較,可以看出,在同一精確度水準之下,EfficientNet 有著更小的模型規模 (#Params) 也有著更少的運算需求 (#FLOPS)。
作者也做了模型推理 (Inference) 的效率分析,成果同樣令人驚豔,相較於精確度類似的模型 (ResNet-152 and GPipe),EfficientNet較之快了 5.7 和 6.1 倍!
在遷移學習上,EfficientNet 的表現也非常好,細節就請大家直接去查詢論文。
為什麼「複合式模型縮放」的方法相較於單一維度縮放,會有更好的效能?作者利用了 Class Activation Map (CAM,註一) 來比較它們的差異: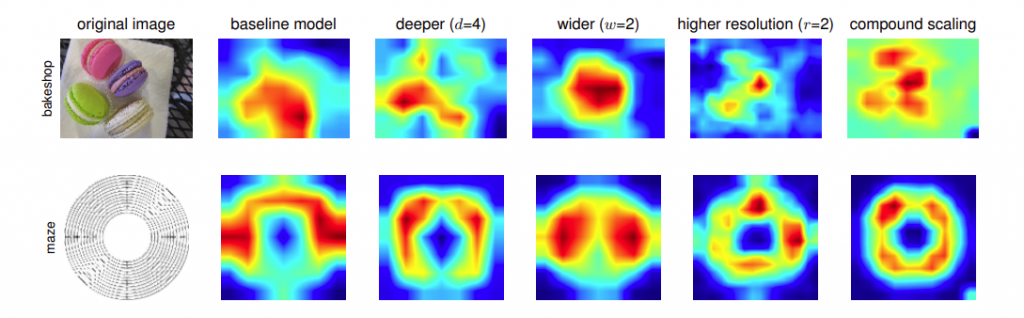
最右邊那一列是複合式縮放的 CAM 圖,很明顯的可以看到,複合式縮放的模型比較能將焦點集中在真正能夠判斷影像類別的區域上,並且能夠分辨出影像上各別的物體。
EfficientNet 的介紹就在此告一段落,經過幾天的介紹,希望大家對它能有更清楚的認識。
(註一:參考
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., and Torralba, A. Learning deep features for discriminative localization. CVPR, pp. 2921–2929, 2016. )
不好意思,我想請問一下,EfficientNet-B0演算法是以CNN進行嗎
是的,它是屬於CNN,結構可以參考 https://ithelp.ithome.com.tw/articles/10244325
謝謝老頭,那我想在請問efficientnet-bO的open source code 有嗎
從應用的角度來看, tensorflow 和 pytorch 都已經提供 API.
1.tensorflow/keras:
https://keras.io/api/applications/efficientnet/#efficientnetb0-function
2.pytorch:
https://www.kaggle.com/ateplyuk/pytorch-efficientnet
需要實作的 sorce codes 就得自己去撈出來.
謝謝老頭,那請問b0他是用哪個分類演算法進行分類?
不太清楚你的問題,如果你是問上面提到的 B0 API 是用那一個 dataset 訓練出來的? 那麼答案是它們都是未經訓練的. 老頭用自己的 dataset 來訓練它們的.
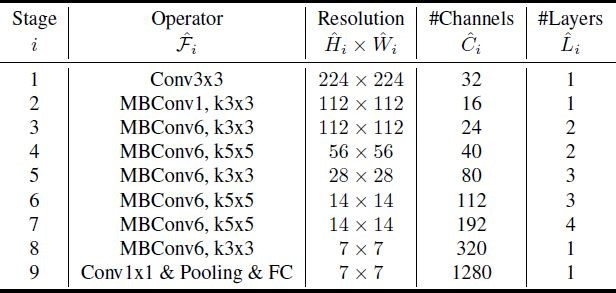
謝謝老頭,我想請問老頭一下,EfficientNet-B0架構有resolution(Hi*Wi),上面Hi和Wi會有大於倒著的符號。如圖