即使客戶不懂程式,你也可以讓他學習一點工程師的知識
 我們要請客戶將爬蟲的網址列表填寫到什麼檔案呢?
我們要請客戶將爬蟲的網址列表填寫到什麼檔案呢?專案在需求規格中有一條是在自己的電腦執行,在分析完各種檔案格式的優缺點後我決定使用json格式:
格式難以律定,只要使用者多個空格、表點符號...都容易造成程式的誤判不是所有人電腦都有安裝 excel 編輯器(像我朋友就沒有)key-value 的格式易於理解、程式可直接讀取
 今日目標
今日目標1.1 json 格式與基本規則
1.2 在專案中建立 json 格式的粉專清單
2.1 在專案引入 json 檔案
2.2 批量爬蟲程式撰寫
今天說的這個部分應該是大部分小編最關心的,要每天手動瀏覽那麼多的粉專想想都很崩潰
所以要來跟大家介紹的一個很棒的文本格式:json (JavaScript Object Notation) ,他能幫助我們批量爬蟲,同時也是網頁 api 最常見的一種回傳格式
json 可以包含 object (物件) 與 array (陣列)
{...}包起來
{ "key" : "value" }
{ "姓名" : "寶寶不說" } //通常用於描寫一項屬性的數值
{ "key" : "value" , "key" : "value" }
{ "姓名" : "寶寶不說" , "性別" : "不明" } //多個物件可表達一個東西的多種屬性
[...]包起來
[ value, value ]
// 陣列與物件裡面value可以使用多種資料型態如下
[ 0 , { "傳奇寶寶" : null } , "string" , false , ['test'] ]
建構邏輯:
許多粉專需要去追蹤,所以最外層會用 陣列(array)
每個粉專都有自己的屬性(title為粉專名稱、url為粉專網址),所以陣列裡面的 value 採用 物件(object)
[
{
"title": "粉專A",
"url": "粉專A連結"
},
{
"title": "粉專B",
"url": "粉專B連結"
}
]
在專案建立的步驟:
建立 fanspages 的資料夾,專門存放粉專頁面爬蟲要使用的json檔案fanspages 資料夾中新增 ig.json、fb.json 這兩個檔案,並依照上述json結構填上你要爬蟲的資訊[
{
"title": "寶寶不說",
"url": "https://www.instagram.com/baobaonevertell/"
},
{
"title": "松尼",
"url": "https://www.instagram.com/sweethouse.sl/"
},
{
"title": "麻糬爸",
"url": "https://www.instagram.com/mochi_dad/"
},
{
"title": "好想兔",
"url": "https://www.instagram.com/chien_chien0608/"
},
{
"title": "ㄇㄚˊ幾兔",
"url": "https://www.instagram.com/machiko324/"
}
]
console.log 確認是否有正確引入
filter 來過濾
let fanpage_array = require('../fanspages/ig.json');
//過濾掉重複的粉專頁面,減少資源浪費
fanpage_array = fanpage_array.filter((fanpage, index, self) =>
index === self.findIndex(f => f.url === fanpage.url)
)
console.log(fanpage_array)
for/of迴圈 包起來(因迴圈內用到 async/await),讓他依序前往粉專頁面抓資料
for (fanpage of fanpage_array) {
// 撰寫你要對fanpage做的事
}
不要因為自己的爬蟲造成別人伺服器的負擔
這裡我們使用Math.random()取得區間亂數
await driver.sleep((Math.floor(Math.random()*4)+3)*1000)
let fanpage_array = require('../fanspages/ig.json');
//過濾掉重複的粉專頁面,減少資源浪費
fanpage_array = fanpage_array.filter((fanpage, index, self) =>
index === self.findIndex(f => f.url === fanpage.url)
)
const ig_username = process.env.IG_USERNAME
const ig_userpass = process.env.IG_PASSWORD
const { By, until } = require('selenium-webdriver')
exports.crawlerIG = crawlerIG;
async function crawlerIG (driver) {
const isLogin = await loginInstagram(driver, By, until)
if (isLogin) {
console.log(`IG開始爬蟲`)
for (fanpage of fanpage_array) { // 用迴圈爬蟲每個粉專
let trace = null
const isGoFansPage = await goFansPage(driver, fanpage.url)
if (isGoFansPage) {
//每個頁面爬蟲停留3~6秒,不要造成別人的伺服器負擔
await driver.sleep((Math.floor(Math.random() * 4) + 3) * 1000)
trace = await getTrace(driver, By, until)
}
if (trace === null) {
console.log(`${fanpage.title}無法抓取追蹤人數`)
} else {
console.log(`${fanpage.title}追蹤人數:${trace}`)
}
}
}
}
.//後面程式一樣
.
.
 執行程式
執行程式yarn start
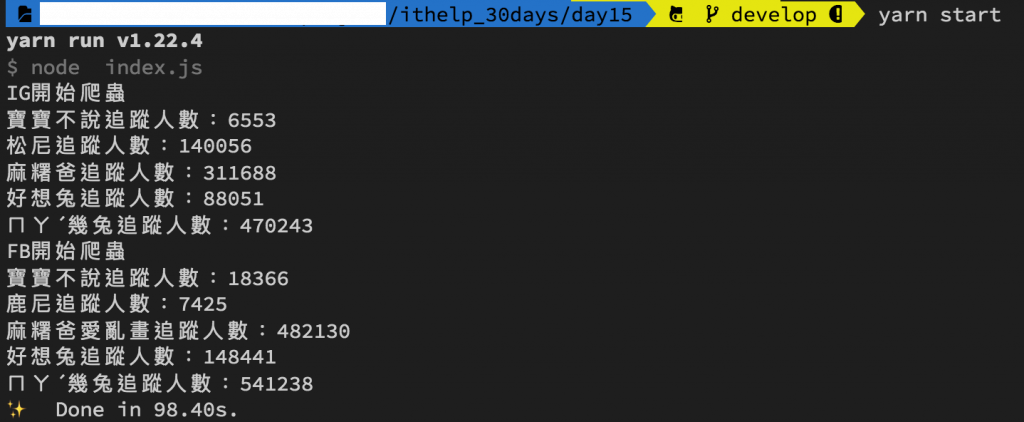
搭配上json後有沒有覺得自己功力大增XD,上面的是IG的範例,大家可以自己嘗試看看FB部分的如何改寫喔~
 參考資源
參考資源免責聲明:文章技術僅抓取公開數據作爲研究,任何組織和個人不得以此技術盜取他人智慧財產、造成網站損害,否則一切后果由該組織或個人承擔。作者不承擔任何法律及連帶責任!
我在 Medium 平台 也分享了許多技術文章
❝ 主題涵蓋「MIS & DEVOPS、資料庫、前端、後端、MICROSFT 365、GOOGLE 雲端應用、個人研究」希望可以幫助遇到相同問題、想自我成長的人。❞
在許多人的幫助下,本系列文章已出版成書,並添加了新的篇章與細節補充:
- 加入更多實務經驗,用完整的開發流程讓讀者了解專案每個階段要注意的事項
- 將爬蟲的步驟與技巧做更詳細的說明,讓讀者可以輕鬆入門
- 調整專案架構
- 優化爬蟲程式,以更廣的視角來擷取網頁資訊
- 增加資料驗證、錯誤通知等功能,讓爬蟲執行遇到問題時可以第一時間通知使用者
- 排程部分改用 node-schedule & pm2 的組合,讓讀者可以輕鬆管理專案程序並獲得更精確的 log 資訊
有興趣的朋友可以到天瓏書局選購,感謝大家的支持。
購書連結:https://www.tenlong.com.tw/products/9789864348008
你好用心寫文章,排版跟內容,好看又很豐富



 iThome鐵人賽
iThome鐵人賽