歡迎來到第 13 天,今天將嘗試的將前兩所撰寫的 UN Career 爬蟲結合 Line API,並部署於 Linux server 中。
開始前,在此申明此篇文章參考原文為 How to setup Selenium on a Linux VM,若此篇文章有幫助到讀者,請至原文給予作者支持與鼓勵。由於原文的三個步驟簡單明瞭,筆者在此篇文章將著重在設定過程所遇到的挑戰。
在此筆者所使用的 Linux VM 是 GCP 所提供的,請利用 Google 帳號登入並完成基礎的信用卡綁定,並開啟新專案。完成後,請至 Compute Engine -> VM instances 處創建一個新的虛擬主機。
完成創建後就是安裝環境的環節了,依照 How to setup Selenium on a Linux VM 的說明,需要經過三個步驟方能完成環境的設定,但由於本身我們所新創建的 server 中並沒有自帶 python3,因此需要額外安裝 python3,可以簡單的透過下列指令安裝
$ sudo apt-get update
$ sudo apt-get install python3
$ sudo apt-get install python3-pip
這時候若你是和我一樣使用 ssh 從本機終端機連線,會發現怎麼樣也無法取得 sudo 權限,這是因為 Google 限制了透過 remote ssh 連線的 sudo 權限,因此要進行這類的安裝,必須要到 GCP 的 VM instance 進行 ssh 連線並在此處取得權限並進行安裝。
安裝完 python3 後,開始依照 How to setup Selenium on a Linux VM 的三步驟,此處就不多做說明,只貼上先關的終端指令。(原文的 Chromedriver 為 79.0.3945.36,單由於版本支援的問題,筆者在此處改為 85.0.4183.87)
$ sudo apt-get install -y unzip openjdk-8-jre-headless xvfb libxi6 libgconf-2-4
$ # Install Chrome.
$ sudo curl -sS -o - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add
$ sudo echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list
$ sudo apt-get -y update
$ sudo apt-get -y install google-chrome-stable
$ # Install ChromeDriver.
$ wget -N https://chromedriver.storage.googleapis.com/85.0.4183.87/chromedriver_linux64.zip -P ~/
$ unzip ~/chromedriver_linux64.zip -d ~/
$ rm ~/chromedriver_linux64.zip
$ sudo mv -f ~/chromedriver /usr/local/bin/chromedriver
$ sudo chown root:root /usr/local/bin/chromedriver
$ sudo chmod 0755 /usr/local/bin/chromedriver
$ # Install Selenium
$ pip3 install selenium
完成環境安裝後,接下來就是結合 Line API
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from linebot import (
LineBotApi, WebhookHandler
)
from linebot.models import TextSendMessage
def page_spyder(driver):
page = 1
indexer = 0
timeout = 5
jobs = {}
elements = driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")
jobs = {**jobs,**title_url_extract(driver)}
while elements: # 確認有多個分頁才跑
if elements[indexer].text == str(page+1) or (elements[indexer].text == "..." and indexer>3):
driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")[indexer].click()
element_p = EC.presence_of_element_located((By.CLASS_NAME, 'pager'))
WebDriverWait(driver, timeout).until(element_p)
jobs = {**jobs,**title_url_extract(driver)}
elements = driver.find_elements_by_xpath("//tr[@class='pager']//table//td/a")
page +=1
indexer = 0
elif indexer+1 == len(elements):
break
else:
indexer += 1
return jobs
def title_url_extract(driver):
jobs = {}
tr_tags = driver.find_elements_by_xpath("//table[@class='sch-grid-standard']/tbody/tr[not(@class)][not(@align)]/td/a[1]") # 定位出每個職缺的標籤
for job in tr_tags:
jobs[job.text] = "https://careers.un.org/lbw/"+job.get_attribute("onclick").split("'")[1]
return jobs
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(executable_path = 'Path to Webdriver',
options=chrome_options)
url = "https://careers.un.org/lbw/home.aspx?viewtype=SJ&exp=All&level=0&location=All&occup=0&department=All&bydate=0&occnet=0&lang=en-US"
driver.get(url)
jobs = {}
for i in range(5):
driver.find_elements_by_xpath("//span[@class = 'rtsTxt']")[i].click()
element_p = EC.presence_of_element_located((By.CLASS_NAME, 'rtsTxt'))
WebDriverWait(driver, 5).until(element_p)
jobs = {**jobs,**page_spyder(driver)}
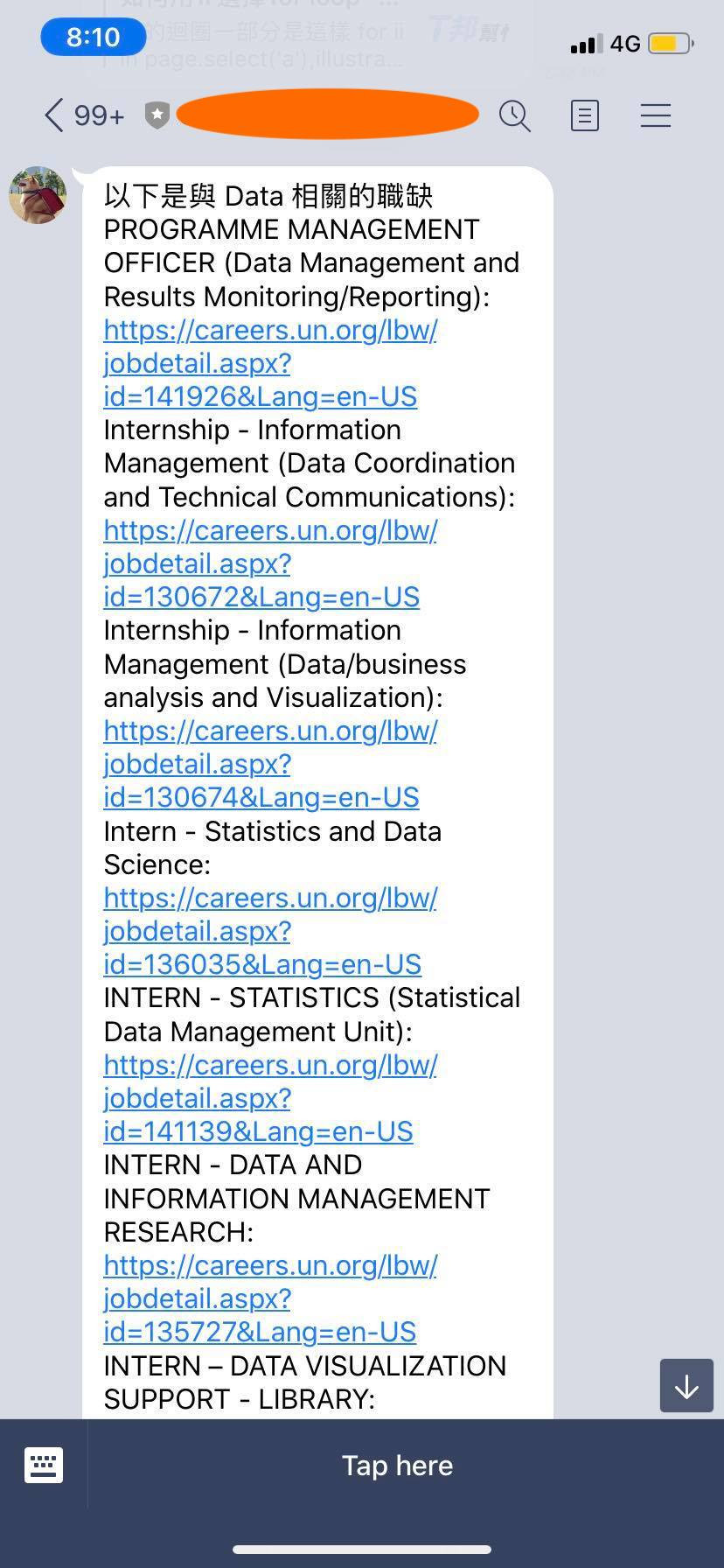
message = "以下是與 Data 相關的職缺\n"
for job in jobs.keys():
if "data" in job.lower():
message += f"{job}:\n{jobs[job]}\n"
line_bot_api = LineBotApi('YOUR_CHANNEL_ACCESS_TOKEN')
line_bot_api.push_message("Your Line ID", TextSendMessage(text=message))
並順利的將此程式部署到剛剛創建好的 Linux server 並設下排程,就會每天收到下列訊息
準備好了嗎?年後轉職等著你!?我們明天見!


 iThome鐵人賽
iThome鐵人賽