以下會使用 "aggregations" 或 "aggs" 詞彙來表示而非 "聚合"
這篇更加詳細的介紹 "聚合" 和另一種aggs的應用
前置作業
後續範例皆使用 Elastic Stack第七重 匯入的範例資料,所以還未匯入可以先照那一重做批次匯入
補充介紹aggs四大家族
aggregations can be nested!
每一個bucket定義了每一個document set,可以再透過 aggregations 把 bucket 的內容物做進一步的分析或分類
根據 aggregations 的結果,再做 aggregations,這種稱為 nested aggregations,且沒有強硬的限制層數,而在 "parent"(higher-level) aggregation 下的 aggregation 又稱為 sub-aggregations
"aggregations" : { (1)
"<aggregation_name>" : { (2)
"<aggregation_type>" : { (3)
<aggregation_body>
}
[,"meta" : { [<meta_data_body>] } ]?
[,"aggregations" : { [<sub_aggregation>]+ } ]? (4)
}
[,"<aggregation_name_2>" : { ... } ]*
}
(1): 此處的 aggregations 也可以使用 aggs
(2): <aggregation_name>: 由使用者自行定義,在response內的 aggregations 也會用此處定義的名稱
(3): <aggregation_type>: 每一種 aggregation 都有指定的 type,會根據選擇的 aggregation_type 產生出特定的body,例如:上一重介紹過的 Terms Aggregation 就是一種 aggregation_type
(4) 即是上面提到的 aggs 強大的地方,是可以根據 (3) 產生的結果,再做進一步的 aggregation,也就是 nested aggregations
上一重有提到如何執行上述的aggs,其實就是使用搜尋的endpoint _search ,
可用上述JSON結構與上一重或用下面範例做對照
根據指定field對documents的field value做指標(metrics)運算
Nested Aggregation (Bucket and Avg Aggregation)
情境:根據 state 來分類documents,再計算出那一 state 的帳戶的 平均餘額,最後以平均餘額 做 降冪排序
Request (Nested Aggregation)
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": { (4)
"average_balance": "desc"
}
},
"aggs": { (1)
"average_balance": { (2)
"avg": { (3)
"field": "balance"
}
}
}
}
}
}
Request 說明
(1): 使用 Nested Aggregation
(2): <aggregation_name> 自行定義為 "average_balance"
(3): <aggregation_type> 使用 avg
(4): terms aggs 回傳的buckets 使用 Nested Aggregation 中的 "average_balance" (平均餘額) 做排序
Response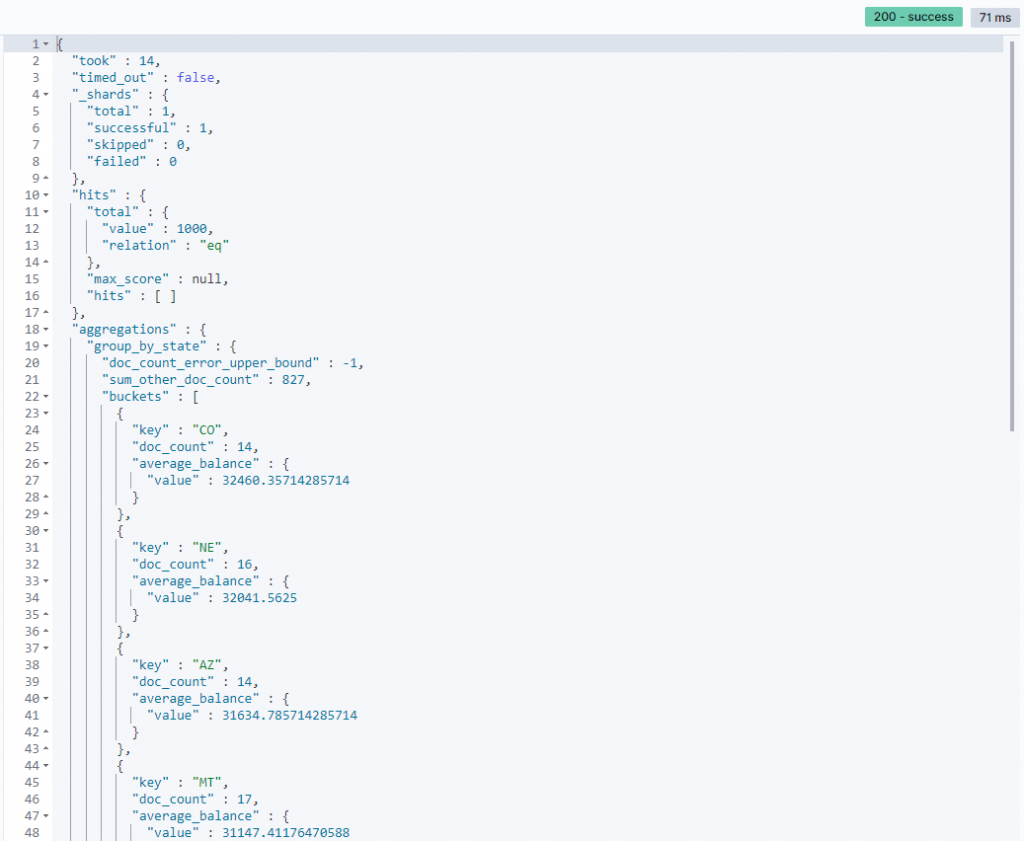
Response 說明group_by_state.buckets.average_balance.value: 每一bucket內再計算出的 平均餘額
可以發現,目前第一個bucket的 平均餘額 是最高的
小小新手,如有理解錯誤或寫錯再請不吝提醒或糾正
Aggregations
Metrics Aggregations
Avg Aggregation

