本篇繼續介紹 Query DSL 的 term-lvel queries
range query找出terms在指定的range的documents
[情境] 找出 field age 的field value 介於 10(包含) 和 20(包含) 之間的documents
Example Request
GET /_search
{
"query": {
"range": { (1)
"age": { (2)
"gte": 10, (3)
"lte": 20 (4)
}
}
}
}
(1): range query
(2): <field>,必填,欲搜尋的 field
(3): gte,大於等於
(4): lte,小於等於
當然,有大於等於,也有 "大於",使用 gt,同理,"小於" 使用 lt
range query with text and keyword fields
實際上,range query是可以用在 field type為 text 和 keyword 的fields,
不過是屬於 expensive queries (成本比較高),所以一般而言執行會比較慢。
而有參數可以限制 expensive queries, search.allow_expensive_queries 預設為 true,
當設定為 false 時,就無法執行 expensive queries,也就會包含無法使用 range query 來搜尋 field data type 為 text 和 keyword 的fields。
range query with date fields
如果 <field> 的 field data type為 date,則可以使用 date math(https://www.elastic.co/guide/en/elasticsearch/reference/current/common-options.html#date-math) 搭配 gt, gte, lt, lte
[情境] 找出 field timestamp 的field value 介於 今天 和 昨天 之間的documents
Example Request
GET /_search
{
"query": {
"range": {
"timestamp": {
"gte": "now-1d/d", (1)
"lt": "now/d" (2)
}
}
}
}
(1): 現在 減 1天,並無條件捨去至最近的天
(2): 現在,並無條件捨去至最近的天
這邊稍微說明一下 date math,
可使用日期來當錨點(anchor),如 now 或者是 formatted date,而如果使用 formatted date,其後面須加上 ||,然後在 anchor date 後面可選擇性加上 數學式,
例如:
+1h: 加上1小時-1d: 減1天/d: 無條件捨去至最近的天regex query透過 regular expression 找出有匹配的terms,然後回傳其documents
而 regex query 支援的operators可參閱 Regular expression syntax ,是使用 Apache Lucene's 的 regular expression 引擎
[情境] 找出field user.id 是 k 開頭,y 結尾的documents
Example Request
GET /_search
{
"query": {
"regexp": { (1)
"user.id": { (2)
"value": "k.*y", (3)
"flags": "ALL" (4)
}
}
}
}
(1): 即 regex query
(2): <field>,必填,欲搜尋的 field
(3): value,必填,填入 regular expression
(4): flags,選填,預設為 ALL,此參數用來設定 regular expression引擎 可使用的operators
上述request的 regex為 "k.*y",其中 .* operators 代表的是可以匹配任何字元,包括沒有字元也算,所以可以匹配的terms可以是 ky, kay, kelly 等等
[Note]regex query也是屬於 expensive queries
term query搜尋出指定field含 exact term 的documents
在蠻多篇章應該都有提到此 query,這邊再完整介紹一次
[Note]
避免使用 term query 在 text field 上,因為 text field在建立索引時,會經過 analyzer分析而改變原本的值,所以會讓精確匹配是很困難的
此範例使用 Elastic Stack第七重 匯入的範例資料,所以想用一樣的測資可先照那一重做批次匯入
[情境] 找出 field firstname 為 "Nanette" 的 帳戶擁有者資訊(document)
Request
GET /bank/_search
{
"query": {
"term": { (1)
"firstname.keyword": { (2)
"value": "Nanette" (3)
}
}
}
}
(1): 即 term query
(2): <field>,必填,欲搜尋的field,記得使用非 text field,此處使用 "firstname.keyword" 的 field date type為 keyword,而 "firstname" 是 text field data type,所以不能使用 "firstname" ,否則會不如預期(以此為例,用 "firstname" 會匹配不到任何documents)
(3): value,必填,欲搜尋的值
Response
上述Request也可以簡寫成
GET /bank/_search
{
"query": {
"term": {
"firstname.keyword": "Nanette"
}
}
}
[Note]
如欲搜尋 text fields,可以透過 match query,在儲存至此field前會經過analyzer分析後轉換成tokens才會被建立索引,而用 match query 提供的 query string(search term)也一樣會經過analyzer分析,此兩個analyzer是可以指定成不一樣的analyzer,在未設定時,皆使用預設的 standard analyzer ,透過分析後的 tokens 來做匹配搜尋,而不是用 exact term(精確的值)
而 term query "不會"分析 search term, term query 直接拿提供的term找出完整符合的term,這也意味著用 term query 搜尋 text fields 可能回傳 poor(較少) 或 沒有匹配的documents
terms query搜尋出指定field含 一個或多個 exact term 的documents,
其實和 term query一樣,只是差在可以搜尋多個值
[情境] 找出 field firstname 為 "Nanette" 或 "Mcgee" 的 帳戶擁有者資訊(document)
Request
GET /bank/_search
{
"query": {
"terms": { (1)
"firstname.keyword": ["Nanette", "Mcgee"] (2)
}
}
}
(1): 即 terms query
(2): 放置多個 search term至array value
Response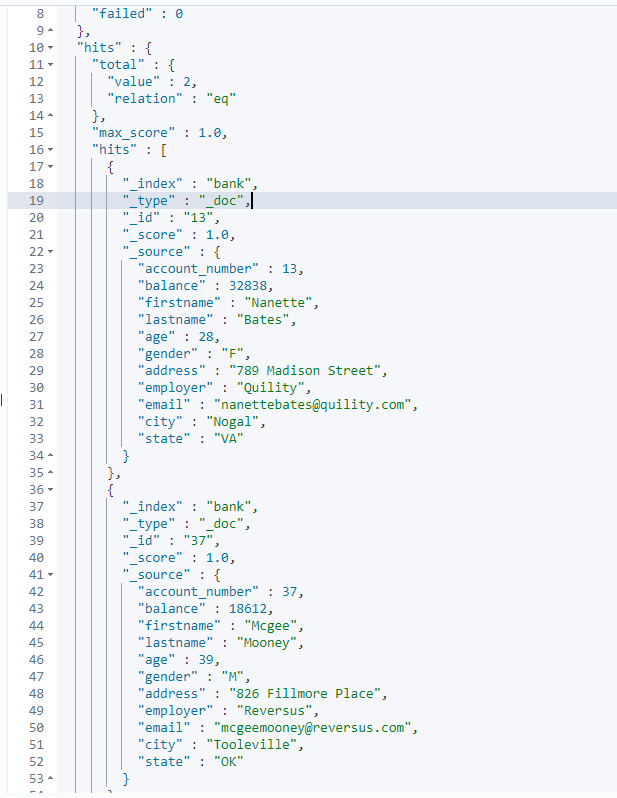
小小新手,如有理解錯誤或寫錯再請不吝提醒或糾正
Term-level queries
regular expression


 iThome鐵人賽
iThome鐵人賽