以下會使用 "aggregations" 或 "aggs" 詞彙來表示而非 "聚合"
這篇主要介紹 "聚合" 的概念和其中一種aggs的應用
前置作業
後續範例皆使用 Elastic Stack第七重 匯入的範例資料,所以還未匯入可以先照那一重做批次匯入
根據搜尋結果(search results)再做處理,像是 分類 (此處也是我們平常說的 後分類) 或 計算指標(metrics),
以情境來理解 aggs 能做到什麼,
Q: "有多少帳戶擁有者是住在Texas的?"
或
Q: "在Tennessee(田納西州)的帳戶的平均餘額是多少?"
至於,到底怎麼使用 "aggs" 呢?
他其實就是使用搜尋的endpoint _search ,搭配他提供的參數 aggs 就可做到,
言下之意就是,"透過一個request可做到搜尋documents並用aggs做到後分類"
aggregations 有許多種不同類型,官方把他們細分成四種家族:
情境:根據 state 來分類documents
Request (Terms Aggregation)
GET /bank/_search
{
"size": 0, (3)
"aggs": {
"group_by_state": { (4)
"terms": { (1)
"field": "state.keyword" (2)
}
}
}
}
Request 說明
(1) terms aggregation:屬 bucket aggregations ,下面會在做更詳細的介紹
(2) state.keyword 代表想用什麼欄位來分類,至於這邊為什麼要用 keyword 和前一重提到的 term query 一樣,是只能用在 精確值(exact term)
(3) size:會使用 size 為0,只是讓response不顯示documents (即 hits.hits 為空),只包含 aggs results
(4) group_by_state 是 agg_name,可以自己定義名稱,不要和其他 agg_name 一樣即可
Response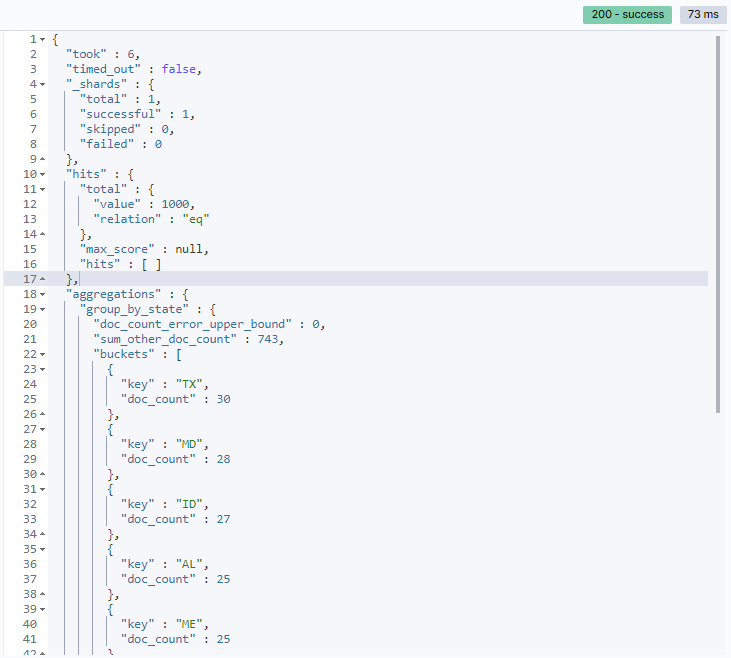
Response說明aggregations.<agg_name>.buckets :是以 state 分類的結果,每一組的 key 為 state 的值,而 doc_count 為 分類到此值的數量,
例如:圖中的第一組,所有的帳戶擁有者中,住在 TX 的有 30 個,
<agg_name>為自己定義的名稱,以此為例即為 group_by_state,
Terms Aggregation
針對提供的field的 unique value 做分類
預設:回傳的 buckets 只包含10個,且以 doc_count 多至少 降冪排序,也就是 只回傳最多分類的前10組
參數:
doc_count 排序,也可使用 _key 排序,此 _key 代表的是 field中的value (term),state 的值排序的意思情境:根據 state 來分類documents,最多回傳100個分類,且以 state 值做升冪排序
Request (Terms Aggregation)
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"size": 100,
"order": {
"_key": "asc"
}
}
}
}
}
Response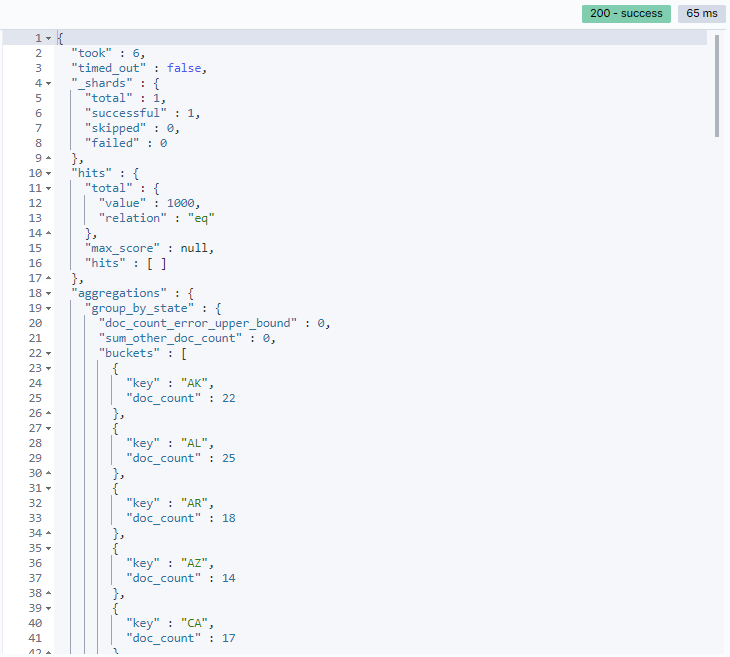
小小新手,如有理解錯誤或寫錯再請不吝提醒或糾正
Aggregations
Bucket Aggregations
terms aggregation

