今天要來講的是Elasticsearch計分,在ES搜尋時,ES會計算每個文檔的得分,簡單講就是得分代表的是查詢語句和文檔匹配程度的變量,一般來說搜尋出來的文檔會根據得分排序,那下面就先來看ES是如何幫文檔打分的吧
ES在計算得分時,是基於Lucene採用布爾模型(Boolean model)、詞頻/逆向文檔頻率(TF/IDF)、以及向量空間模型(Vector Space Model)結合而成的
在ES5.0以後將tf–idf改為基於BM25(tf–idf的延伸)來計算分數的
在索引時給文檔設定的權重
在查詢的给某個域設置的權重
文檔中包含查詢關鍵字個數計算出來的協調因子。一般來說,如果一個文檔中相比其它 的文檔出現了更多的查詢關鍵字,那麼其值越大
基於term的因子,如果文檔內出現term給定的關鍵字越多次,其值越高。
在BM25裡抑制了tf對整體評分的影響度,BM25中,tf越大,帶來的影響趨近於(k + 1),這裡k值通常取[1.2, 2], 而傳統的TF/IDF則會無限增長
以下是計算公式
5.0之前
tf(t in d) = √frequency
5.0之後
tf * (k + 1) / (tf + k)
基於term的因子,關鍵詞出現的頻率越少,詞越稀有(這裡單純是指頻率,就是多少個文檔出現該詞),打分公式利用這個因子提升包含稀有詞文檔的權重,以下是權重計算公式
idf(t) = 1 + log ( numDocs / (docFreq + 1))
字段越短,權重越高,如果一個term給定的關鍵詞出現在一個短字段(例如title),會比它出現在一個很長的字段(例如文章內容)更有關聯。
在5.0之後基本上跟原本一樣,但多了一個參數b來調整影響度,當值調整為0時就等於忽略文檔長度的影響,通常的話都會調整為b=0.75
以下是計算公式:
norm(d) = 1 / √numTerms
嘗試把查詢正規化,這樣就能比較兩個不同的查詢結果,但通常比較兩個查詢語句的得分不沒有什麼太大意義,其值為查詢語句中每個查詢詞的權重的平方和
計算公式:
score(q,d) = #文檔d與查詢q的相關度分數
queryNorm(q)
· coord(q,d)
· ∑ (
tf(t in d) #是術語t在文檔d中的詞頻
· idf(t)² #術語t的逆文檔頻率
· t.getBoost()
· norm(t,d)
) (t in q)
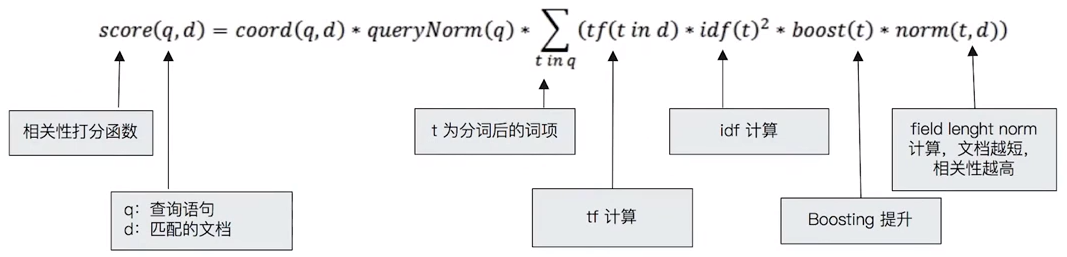
圖片出處:https://godleon.github.io/blog/Elasticsearch/Elasticsearch-advanced-search/
BM25: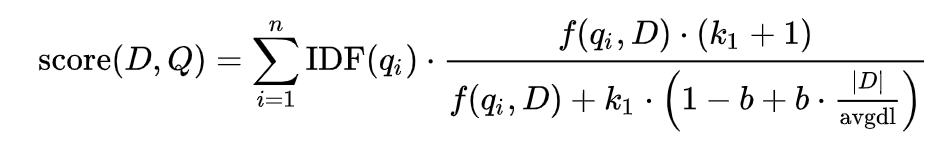
|D|:文檔長度
f(q, Q):tf(q in d)
avgdl:平均文檔長度

