註:本文同步刊載在Medium,若習慣Medium的話亦可去那邊看呦!
我們先來看看昨天的練習吧!
一般來說,我們可以先打開來觀察,
將其複製到JSON Online Editor上看看右邊的tree長什麼樣子,
這樣會有助於後面思考操作方式。
import json
with open('bookstore.json', 'r', encoding="utf-8") as f:
bs = json.load(f)
# 記得list comprehension嗎?
taipei = [i for i in bs if '臺北市' in i['cityName']]
# 我們要的是名字,所以要取'name',判斷標準則是用hitRate。
>>> [i['name'] for i in taipei if i['hitRate'] > 2000]
['茉莉二手書店(臺大店)', '信誼小太陽親子書房(臺北重慶店)', '田園城市生活風格書店', '亞典藝術書店', '古原軒書店']
請留意到,這個練習是相對比較輕鬆的,
因為當中所用到的元素都沒有缺漏的部分,
所以不會產生任何錯誤;
但實務狀況上,常常會有一些資料是短少的,
這時候就要先做過資料的前處理(preprocessing)以後,
將缺漏的部分去除,或者補上適當的值,才能讓資料得以正常使用。
在資料清理(data cleaning)這部分,Python常用的有pandas跟numpy,
以後我們有機會再來介紹。
我們今天要來講的是系統模組(os)。
OS是Operating System(作業系統)的縮寫,
主要作用是提供你所使用的作業系統的一些功能,
例如檔案的路徑檢查、列出檔案列表、
檔案複製/移動/改名/刪除等。
下面的示範,我們是基於使用者在以下的資料夾環境操作的:
C:\Users\Desolve\utils>tree /f
列出資料夾 PATH
磁碟區序號為 D6BD-47D7
C:.
│ bookstore.json
│ check.py
│ fromzero.py
│ poem.txt
│ schedule.py
│ __init__.py
│
├─csv
│ student.csv
│ student_dic.csv
│
├─json
│ classA.json
│
└─__pycache__
check.cpython-38.pyc
schedule.cpython-38.pyc
__init__.cpython-38.pyc
要使用os,最重要的就是先import啦!
請留意一件事情,
在Unix系列的系統裡面,路徑分隔資料夾或檔案是使用"/"來處理的,
Windows系列的系統中,則是使用"\",兩者剛好相反。
如果我們想看某個檔案或目錄是否存在於特定位置,
我們可以使用os.path.exists(),可以是相對路徑或絕對路徑。
相對路徑是從現在的資料夾為基準出發,來看到到目標位置要怎麼移動;
絕對路徑則是從Unix的根目錄或Windows的C槽D槽之類的起始點出發;
所以以相對路徑來起頭的,前面會有一個"./"或"."開頭,
用來表示從現在所在位置起算(一個點代表現在所在位置,兩個點代表上一層)
>>> import os
>>> os.path.exists('check.py')
True
>>> os.path.exists('poem.txt')
True
>>> os.path.exists('.\json\classA.json')
True
>>> os.path.exists('./json/classA.json') # 實際上用linux的寫法給Python去認也行得通,Python會明白含義
True
>>> os.path.exists('./json/classB.json') # 不存在就回傳False
False
>>> os.path.exists('C:\Users\Desolve\utils\json\classA.json') # 用絕對路徑時避免不必要的麻煩,請多加一個"\"將可能造成的轉義去除
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
>>> os.path.exists('C:\\Users\\Desolve\\utils\\json\\classA.json')
True
再來是分開來的檢查這個路徑是否是檔案/資料夾的方法:
os.path.isfile()及os.path.isdir()。
>>> os.path.isfile('./json/classA.json') # 存在,且是檔案
True
>>> os.path.isfile('./json/classB.json') # 不存在則回傳False
False
>>> os.path.isdir('./json/classA.json') # 是檔案,不是資料夾
False
>>> os.path.isdir('./json') # 是資料夾
True
那麼如果想要複製或移動檔案呢?這就要用到另一個模組shutil了:
>>> import shutil
>>> shutil.copy('poem.txt', 'poem2.txt') # 前面是來源,後面是目的地
'poem2.txt'
>>> shutil.move('poem2.txt', 'poem3.txt') # 移動檔案並更名
'poem3.txt'
要修改名字的話,則可以使用os.rename():
>>> os.rename('./json/poem3.txt', 'poem3.txt') # 也可以做為移動檔案用
要新增/刪除資料夾的話,可以使用os.mkdir()/os.rmdir(),
刪除檔案則使用os.remove():
(有沒有覺得跟Unix系統的shell script很像呢XD?)
>>> os.mkdir('poems') # 開一個新的資料夾
>>> os.rename('poem3.txt', './poems/poem3.txt') # 將poem3.txt移入
>>> os.rmdir('poems') # 將poems資料夾刪除...咦?
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
OSError: [WinError 145] 目錄不是空的。: 'poems'
>>> os.remove('poems/poem3.txt') # 只能先將檔案移除
>>> os.rmdir('poems') # 再移除資料夾
讀者可能會問:
「我怎麼會知道要先刪除哪些檔案?」
問的好!我們可以使用os.listdir()先列出資料夾的所有檔案及資料夾:
(注意,只會列出第一層的,再往下的子資料夾就不會展開囉!)
>>> os.listdir()
['bookstore.json', 'check.py', 'csv', 'fromzero.py', 'json', 'poem.txt', 'schedule.py', '__init__.py', '__pycache__']
>>> os.listdir('csv')
['student.csv', 'student_dic.csv']
最後,是我們的終極必殺武器:os.walk()。
os.walk()就像一個偏執的用路人一樣,
它就是要將整個資料夾,連同子資料夾都走過一遍才會罷休。
走完之後,所有的內容會以(dirpath, dirnames, filenames)的形式回傳,
我們可以使用for ... in ...的方式取得,
請看範例:
for root, dirs, files in os.walk('.'): # os.walk必須要給一個起始點
print(root)
for f in files:
print(os.path.join(root, f)) # os.path.join()可用來處理路徑和檔案的結合
# 結果如下
.
.\bookstore.json
.\check.py
.\fromzero.py
.\poem.txt
.\schedule.py
.\__init__.py
.\csv
.\csv\student.csv
.\csv\student_dic.csv
.\json
.\json\classA.json
.\__pycache__
.\__pycache__\check.cpython-38.pyc
.\__pycache__\schedule.cpython-38.pyc
.\__pycache__\__init__.cpython-38.pyc
如果想要刪除掉某個目錄以下的所有檔案及資料夾,
可以參考Python的Document提供的範例:
請特別留意慎用以下操作,底下的動作可是真的會將目標資料夾全刪光的!!!
尤其是Unix系列的系統,如果給的top起始點是"/"(根目錄)而非"./"(當前目錄),
則會將整個檔案系統都砍光光呦!!!
for root, dirs, files in os.walk(top, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
今天我們介紹了os中跟檔案系統相關操作有關的方法,
其他當然也有很多不錯的相關模組,
例如剛剛有提到的shutil,或是pathlib,
有興趣的讀者可再行挖掘。
那麼,我們就明天見囉!
Desolve前輩你好:
最近用os寫了一個程式,要將檔名有jan和feb的檔案分別移到jan和feb的資料夾遇到了問題,程式碼如下: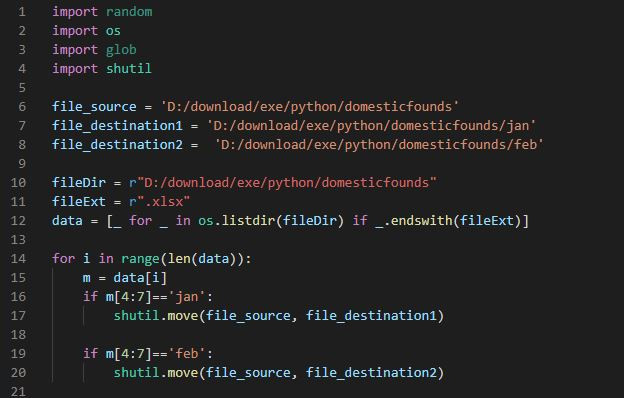

結果出現了如上圖的錯誤我也上網google了好幾天,都找不到答案。請問前輩我是哪裡出錯了,謝謝前輩。
Hi,
看起來你沒有將檔案名放上去耶,
file_source你只有指定到路徑的部分,
建議你試著把m(檔名)的部分接續到file_source再試試看。
還是不行,請問我是放錯地方還是哪裡寫錯了。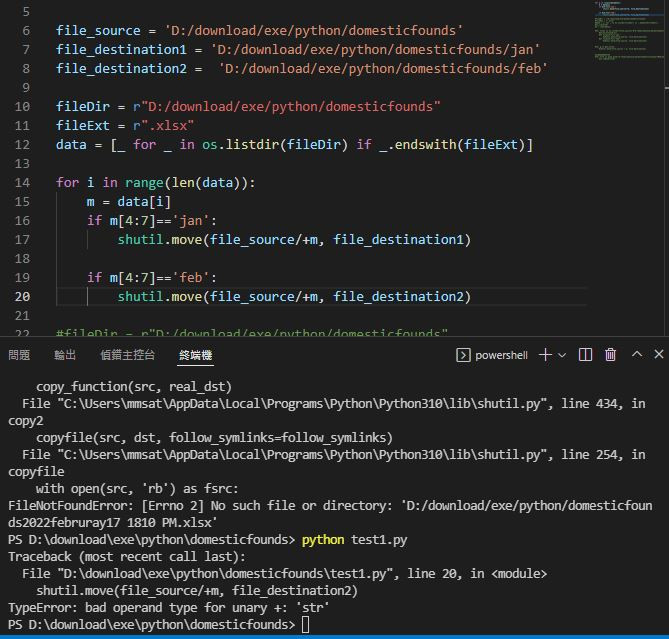
Desolve前輩可以了。不好意思讓你看笑話了,這麼簡單的問題搞這麼久。對於程式出錯時的解決方法,以這次的例子來說python給的方向是錯誤的,那前輩對於程式設計新手而言,往後在寫程式時,如果遇到問題時你會建議如何尋找解決辦法或方向。
Desolve前輩你好:
我用python程式抓取資料儲存成excel後,資料裏會有標點符號,要刪除,上google搜索都找不到解決的辦法。可以麻煩你幫我看一下是哪裡出錯嗎?麻煩你了謝謝。
以下是有標點符號的excel圖片和程式: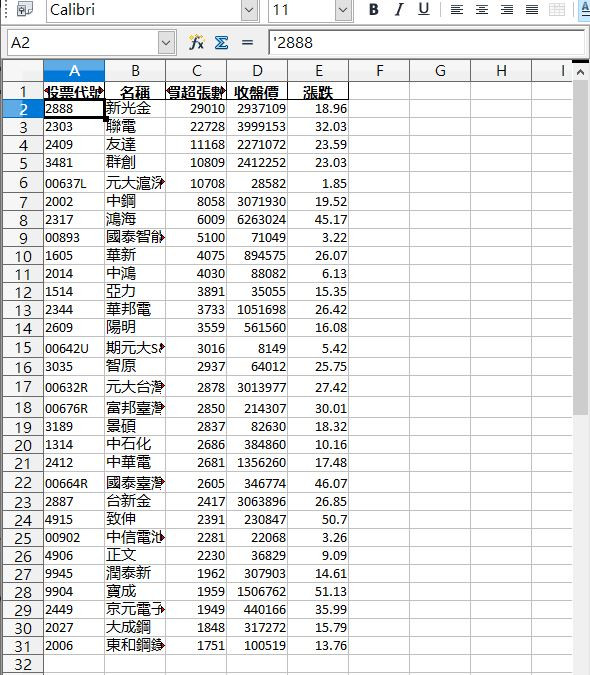
if url == "https://www.tpex.org.tw/web/stock/3insti/qfii_trading/forgtr.php?l=zh-tw":
options1 = browser.find_elements(By.XPATH, '//*[@id="forgtr_result"]/tbody/tr[1]/td[1]')
#使用bs4的BeautifulSoup
soup = BeautifulSoup(browser.page_source, 'html.parser')
#找到table
data = soup.select('table')[0]
#使用read_html建立DataFrame
df = pd.read_html(data.prettify(),header=1)
dfs = df[0]
newdfs = dfs.drop(['排行', '買進', '賣出', '買賣超(仟股)', '買進.1', '賣出.1', '買賣超(仟股).1', '買進.2', '賣出.2'], axis=1)
newdfs.columns=[u"股票代號",u"名稱",u"買超張數"]
#取得投信買超張數大於50張的個股
data = newdfs[newdfs["買超張數"]>=100]
#匯出成excel
data.to_excel('D:/download/exe/python/foreginfounds/OTC/day/'+str(timeString)+'forOTC'+'.xlsx',index = False)
browser.quit()
if url == "https://www.tpex.org.tw/web/stock/3insti/qfii_trading/forgtr.php?l=zh-tw":
options1 = browser.find_elements(By.XPATH, '//*[@id="forgtr_result"]/tbody/tr[1]/td[1]')
#使用bs4的BeautifulSoup
soup = BeautifulSoup(browser.page_source, 'html.parser')
#找到table
data = soup.select('table')[0]
#使用read_html建立DataFrame
df = pd.read_html(data.prettify(),header=1)
dfs = df[0]
newdfs = dfs.drop(['排行', '買進', '賣出', '買賣超(仟股)', '買進.1', '賣出.1', '買賣超(仟股).1', '買進.2', '賣出.2'], axis=1)
newdfs.columns=[u"股票代號",u"名稱",u"買超張數"]
#取得投信買超張數大於50張的個股
data = newdfs[newdfs["買超張數"]>=100]
#匯出成excel
data.to_excel('D:/download/exe/python/foreginfounds/OTC/day/'+str(timeString)+'forOTC'+'.xlsx',index = False)
browser.quit()
我是沒辦法正常運行你的程式啦XD
用字串處理方法應該可以處理才對(如果你是指逗號的話)。
千分位的分隔在金融相關的表格裡應該蠻常見的,
如果真的不會的話可以以它為關鍵字搜尋應該有答案。
順便回應上次沒看到的問題,
Python在程式出錯的時候會給出traceback,
以前面你提供過的錯誤訊息來說,
我認為應該不會太難指出問題,
因為一般都會能看到最後出錯的起始點行數。
其實不論是新手還是老手而言,
遇到問題的關鍵還是在於想辦法拼湊出問題的核心點,
除錯的時候一時間看不出來很正常,
但還是不要直接認定Python給的資訊是錯的比較好。
只要是人就會犯錯,程式方面如果都是自己寫的,
先假定自己有地方寫錯會比較好。
總之:
遇到問題->讀錯誤資訊->
找trace的最開始發生點,看那行告訴你的資訊有什麼->
根據錯誤資訊去搜尋尋找正確的用法->
找不到的話,嘗試換關鍵字或者用更小單位的描述來搜尋->
找到合適的用法,放上去嘗試,
多print出來東西觀察自己的理解是否正確->
解決問題
大概是這樣,提供給你參考。


 iThome鐵人賽
iThome鐵人賽