註:本文同步刊載在Medium,若習慣Medium的話亦可去那邊看呦!
接下來讓我們來聊聊Python在深度學習的部分。
事實上很多iT邦幫忙的神人們在AI & Data組應該都有介紹到深度學習,
可能是使用Tensorflow, PyTorch或Keras。
本篇的重點不是要一篇打各路大神們的三十篇,
而是要簡單介紹一下AI及深度學習的概念,
給大家做一個入門,後續要再深入的話,就可以再去參考更多其它的學習資源。
那麼,我們先聊聊什麼是AI。
人工智慧(Artificial Intelligence),
過往是源自於一些根本的假設以及傳說所揉合而成。
人類對於機器人有一些想像,想像我們可以做出人造人,
這樣的機器人具備自我思考的能力,因而可以透過不斷的思考和選擇達到進化;
同時加上了中古時期對於鍊金術的想像:將意識賦予至無生命的物質當中。
綜合以上,因而我們對於一個AI的想法,
大體上不外乎是以「它會思考」這個角度來出發。
那麼,怎麼樣才算是會思考呢?
有一位電腦科學家圖靈(Alan Mathison Turing),
提出了一個著名的測試方式:圖靈測試。
圖靈測試簡單來說,就是讓一個人(A),
分別去跟兩個不同的對象(B、C)交談,
過程中只透過文字,
A不會看到B、C的模樣或聽到聲音;
最終交談完畢以後,
由A來判斷B、C是否有實質的不同,或者說誰更像是人。
如果有一個機器比另一個人讓A更覺得它像人的話,
即通過圖靈測試。
這樣子的測試後來衍生出很多很有趣的例子,
例如有個名為Eliza的聊天機器人,
會將對方講出來的句子分析其主詞及關連性,
針對當中的關鍵字詞來回答;
或者它也會做一些重組,再拿你講過的話來回答你XD!
而這種模式和人互動下,反而很多人會以為Eliza懂他/她,
殊不知完全掉入了程式設計師的陷阱XD
扯遠了,讓我們拉回來談AI。
我們近幾十年在拿AI這個詞來描述事物時,
其概念和範圍其實也是不斷在變動的。
以比較之前的看法來說,AI通常會被當做是:
使用確定的規則判斷,使得機器得以按照這個規則去運作,
從而在某些方面表現出像是人類在做思考判斷一樣。
比如電腦遊戲中玩家操縱的角色跟NPC對話時,
NPC會依照它的「人設」(也就是遊戲開發者原先對其的設定),
以及當前的一些條件狀況,對玩家做出回應。
當然,我們可以很輕易地看出這是寫好的規則判斷,
原因就是這個NPC可能講沒幾句話就重複循環,
或者是一直要你去打10隻母雞回來交任務XD
再比方說過往的圍棋或象棋軟體,
甚至打敗過西洋棋棋王的電腦「深藍」,
也都脫離不開使用寫好的規則來計算下一步的範疇,
這樣子的AI,我們將其稱為rule-based AI。
按規則走的優點是,
當事情是確定的,且符合過往能歸納的範疇,
那麼機器處理的能力就會非常好。
缺點當然就是一旦遇上沒有被界定的情況,
那機器就會不知道該怎麼辦了XD!
AI在經歷過幾次興起以及幾次寒冬以後,
得益於GPU性能的提升,能加速大量的平行化運算的矩陣運算的原因,
深度學習(Deep Learning)在近年來興起了。
深度學習所建立的AI,和以往以規則為出發的AI不同,
它主要是透過所謂的人工神經網路(Artificial Neural Network, ANN),
在建立起一個結構以後,透過不斷地輸入資料,
輸出結果,檢查結果與正確答案的差距,再對神經網路各自的權重(weight)做修正,
最終讓每次的輸入所得到的輸出結果,能接近正確答案。
舉例來說:
假設讀者的面前有一棵樹,
rule-based的做法會是:
「這邊有樹枝,這邊有樹葉,中間有枝幹連接,
它們的顏色在XX~OO之間,所以這是一棵樹」
深度學習的做法則是:
「反正這就是一棵樹就對了!不知道?沒關係,
我多帶你看幾個:A這個是樹,B這個不是樹,
......好,那你這樣應該可以分辨樹了對吧?」
深度學習在神經網路的類型的這塊,
相對比較像人類的小孩子在學習一樣,
透過不斷的歸納,最終小孩子在心裡面產生一套分辨方式,
這個分辨方式可能說得出來,可能說不出來,
但最終他/她就是會講得出「這是一棵樹,這是車車」這樣子的分類。
上面提到的深度學習的方式,
在具體到人工神經網路上狀態又是怎麼樣的呢?
比較粗略的來說,
人工神經網路是由神經元(neurons)彼此以突觸連接而成的,
不同的突觸,傳遞相同的訊號時會產生不同的強弱變化,
通常我們稱之為權重(weights)。
如同剛剛所說的,
我們會透過檢查正確答案和目前機器輸出的答案的差距,
來修正權重,最常見的方式,
就是使用反向傳播(backpropagation, BP),
加上梯度下降法(gradient descent)或其他算法,
來盡力收斂和正確答案的差距。
這個改善神經網路的過程我們通常稱之為模型訓練(model training)
那麼,接下來談談Keras。
Keras原本是一個用於快速開發深度神經網路的框架,
立基於各項比較常見的框架之上,
例如TensorFlow(Google Brain團隊所開發), Theano, PlaidML等。
但近年來最主要的支援是放到了TensorFlow上面,
同時TensorFlow也主動將Keras的函式庫納入到其中,
我們接下來的範例會基於TensorFlow上的Keras來操作。
如果在自己的電腦上想安裝TensorFlow/Keras的話,
可以參考官網:
https://www.tensorflow.org/install/pip?hl=zh_tw
請留意,如果是要用到gpu的話,
你必須要安裝的是tensorflow-gpu。
由於不是每個人的家裡的GPU都很精良,
所以下面我們主要會介紹如何跟著TensorFlow上的官網提供的colab範例來做。
下面我們會一步步帶各位走過最基本的範例:Fashion MNIST的分類,
請從Basic classification: Classify images of clothing
找到Run in Google Colab並將其打開。
在Colab的網頁中,
當看到"[ ]"的格子時,
代表一組可以執行的程式碼,
滑鼠移動到上面,會顯現播放鍵,
只要按下去就會執行一次。
執行完後顯示的數字代表它已經被執行過了,
且是第幾個被執行的格子。
首先我們看到前導的部分:
我們要使用到的一般會有tensorflow本身以及keras,
所以要進行import,同時,前面我們提過的numpy以及matplolib也都會用到,
讓我們一起導進來。
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__) # 印出當前tensorflow的版本,目前是2.3.0
再來,我們要匯入一組資料集(dataset)。
資料集一般是指針對特定目標或種類收集整理而成的資料,
一些比較代表性的資料集如Cifar-10, MNIST, ImageNet等,
依照使用的狀況不同,有些會被拿來當成基本教學範例,
有些則是會被拿來當成評估訓練方法好不好的標準。
以Fashion MNIST來說,
就是一個在MNIST(手寫0~9的圖形資料集)被用到太無聊的狀況下,
可能打算換換口味才換過來的資料集XD。
Fashion MNIST當中有7萬張灰階圖,
內容是10種不同的服飾,如鞋子、包包、衣服、褲子等。
以這個範例來說,我們的目的,
就是訓練出一個能夠良好地辨認出一張圖片是哪個種類的服飾的模型。
我們要將Fashion MNIST下載後,分為用來訓練的資料,以及用來測試用的資料:
為什麼要分呢?因為如果全部都拿來訓練的話,
那麼在測試這個訓練結果時,我們怎麼知道說,
這個模型(model)回答的好,是因為它真的懂了,
還是是因為背熟考古題呢XD?
畢竟我們是希望它找出一個自己能夠辨別的標準,
而不是背答案。
這邊的label(標籤),指的是該張圖片,是屬於這個資料集的第幾類,
這樣到時候訓練時才能夠知道模型有沒有找錯。
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
在這個資料集中,我們標記為0的是T-shirt/top,
1的是Trouser, 以此類推,將每個類別的名稱記錄下來。
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
接著檢查一下剛剛拿到的資料:
train_images.shape # (60000, 28, 28) -> 60000張,每張像素是28x28
len(train_labels) # 60000 -> 對應的標籤當然就也是60000張
train_labels # array([9, 0, 0, ..., 3, 0, 5], dtype=uint8) -> 0~9的種類,共10種
test_images.shape # (10000, 28, 28) -> 10000張用來做為測試的圖像
len(test_labels) # 10000 -> 對應的標籤當然是10000
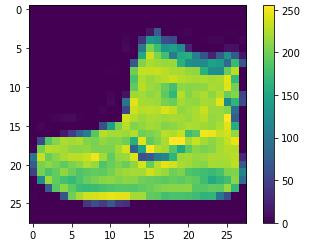
接著我們來預先處理一下資料,
使用plt.imshow()可以將進行圖像繪製,
我們就拿train_images[0]這張來看看:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar() # 用來顯示灰階影像(0-255)
plt.grid(False)
plt.show()
通常我們要處理資料時,
我們要將其標準化到0~1的範圍,
這樣子才不會因為不同的資料的尺度(scale)不同,
影響到模型的訓練或它們對於結果影響的比例。
由於灰階影像的值是0~255,所以我們可以選擇全數除以255.0來等比例縮小,
接著再取前25張圖來檢查處理過的資料是否正常仍可顯示:
train_images = train_images / 255.0
test_images = test_images / 255.0
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1) # 5*5的排列方式
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary) # 範圍0~1時要選binary
plt.xlabel(class_names[train_labels[i]]) # 在x軸的位置顯現分類名
plt.show()
接下來是模型的部分。
要訓練模型之前,首先我們要先將模型的神經網路建構起來,
通常狀態下神經網路是以層(layer)為單位,
層與層彼此之間進行連接,多個層最終構成一個神經網路。
Sequential: 代表前面的往後面的承接
Flatten: 代表將輸入的東西攤平成一維(28*28=784)
Dense: Dense layer又稱全連接層,也就是像握手一樣,
上一層的每個神經元和這層的神經元的每一個組合都有連接到
activation: 激勵函式(activation function),簡單來說,
就是一個讓整個神經連接呈現不是線性的狀態。
因為若是一個模型可以用很簡單的公式或者線性可表達的函數算出來,
這樣子的狀態不是深度學習所要的,因為如果一般的方式可以算的話,
深度學習並沒有比較具備優勢。
(其它目的還有避免過擬合或節省部分計算的考量,我們暫且不深入探討)
# 最後一層是10個神經元,目的就是剛好分成10類
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10)
])
完成一個模型後,我們要進行compile的動作,
將其它附帶的條件給加上。
Loss function(損失函數):用來評估說模型現在給出的答案和正確答案的差距的函式,
這個可以有很多種類,這裡用的是用來衡量分類的SparseCategoricalentropy。
Optimizer(優化器):我們在修正時,不會直接將Loss給出來的差直接處理掉,
而是會有一個評估要往哪個方向修正多少的方法做為基準。
(因為這個點完全相等並不能代表另一個會表現好)
除了adam以外,sgd, adagrad等都是常見的優化器。
Metrics(指標):在訓練的過程中我們會想看的中途狀況,
accuracy是計算每次有正確被分類的圖片的比例。
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
接下來就要開始訓練啦!
Keras中是使用model.fit指令,意思是這個模型要盡力去符合實際的正確標準。
epochs是代表以前面60000張圖片做為一整組的話,
我們想要讓同一個組讓機器訓練過幾次。
指令下了以後就會在下方看到進度條跑動,
以這次訓練來說,
目前訓練的準確度在最後一次是0.9100,也就是91%。
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.5019 - accuracy: 0.8236
Epoch 2/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3788 - accuracy: 0.8633
Epoch 3/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3425 - accuracy: 0.8743
Epoch 4/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.3169 - accuracy: 0.8840
Epoch 5/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2985 - accuracy: 0.8910
Epoch 6/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2821 - accuracy: 0.8957
Epoch 7/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2713 - accuracy: 0.8996
Epoch 8/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2594 - accuracy: 0.9035
Epoch 9/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2499 - accuracy: 0.9067
Epoch 10/10
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2429 - accuracy: 0.9100
<tensorflow.python.keras.callbacks.History at 0x7f88189846a0>
但只會做考古題不算真本事,我們還得看看,
這個模型測試沒看過的圖片時,準確度會是怎麼樣:
我們將最終使用test的圖片來檢驗的動作稱之為evaluate(評定)。
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
# 結果是88.3%左右
313/313 - 0s - loss: 0.3400 - accuracy: 0.8827
Test accuracy: 0.8827000260353088
訓練好的模型,當然不應該只拿來檢查準確度,
也要可以用來檢視新的圖片:
一般狀況下,我們會使用一個softmax層來處理。
softmax層能將一群輸入的值,按照一個分配方式壓縮,
最終所有值都在0~1之間,且加總起來會剛好等於1,
我們就拿這個輸出來做為判斷某個輸入的圖是什麼種類的機率有多少。
# 連接softmax層
probability_model = tf.keras.Sequential([model, tf.keras.layers.Softmax()])
# 用predict方法來進行推論(inference)
predictions = probability_model.predict(test_images)
# 每一個predictions的元素當中包含了預測這個圖分別是種類0~9的機率值
predictions[0]
array([2.3251364e-07, 1.5796850e-08, 5.2541566e-07, 9.3214476e-09,
7.9444156e-08, 1.8098523e-03, 5.7661474e-08, 8.4252998e-02,
1.4421660e-07, 9.1393608e-01], dtype=float32)
# 我們要取機率最高的當做是我們判斷它是哪一種類型
# 使用np.argmax,其結果看起來跟實際上的答案一致,代表有答對XD
np.argmax(predictions[0])
9
test_labels[0]
9
下面colab的範例也提供了兩個函式來提供視覺化的判斷,
在此就不一一解釋:
我們可以看到模型也是有答錯的時候XD: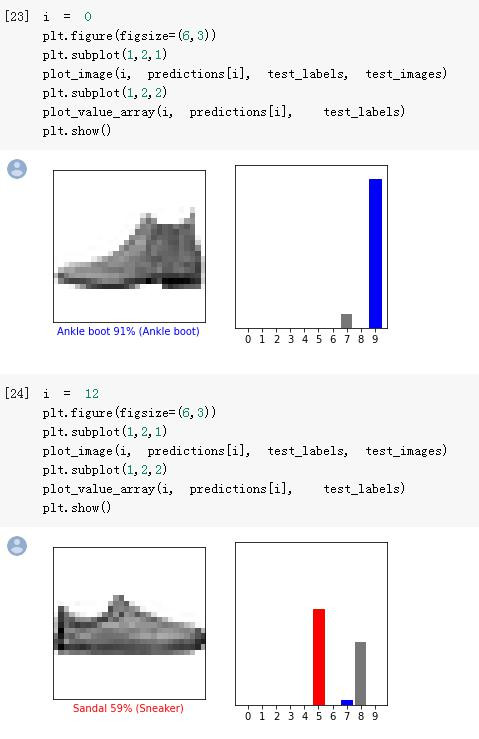
後面還有畫一整群圖片檢驗的對照圖,就請讀者自行參閱。
最後,範例有提到說,因為前面的示範是一次放入10000張下去做predict,
如果今天有一張單張的28x28灰階圖片,
其實同樣可以拿來做predict呦!
唯一的不同,就只是你要將這"一張"圖片,擴展成"一組"圖片,
而這一組裡面就只有一張圖片的格式。
img = test_images[1] # 拿第二張
print(img.shape) # (28, 28)
img = (np.expand_dims(img,0)) # 擴展一個維度,讓它變成"一組"
print(img.shape) # (1, 28, 28)
predictions_single = probability_model.predict(img) # 現在可以predict了
print(predictions_single)
[[5.1490115e-05 9.7672521e-14 9.9936408e-01 2.5379993e-12 1.0796214e-04
6.6310263e-10 4.7655238e-04 2.3014628e-11 2.8894394e-08 5.6684479e-12]]
最終結果順利預測出該圖片是Pullover(套頭衫)。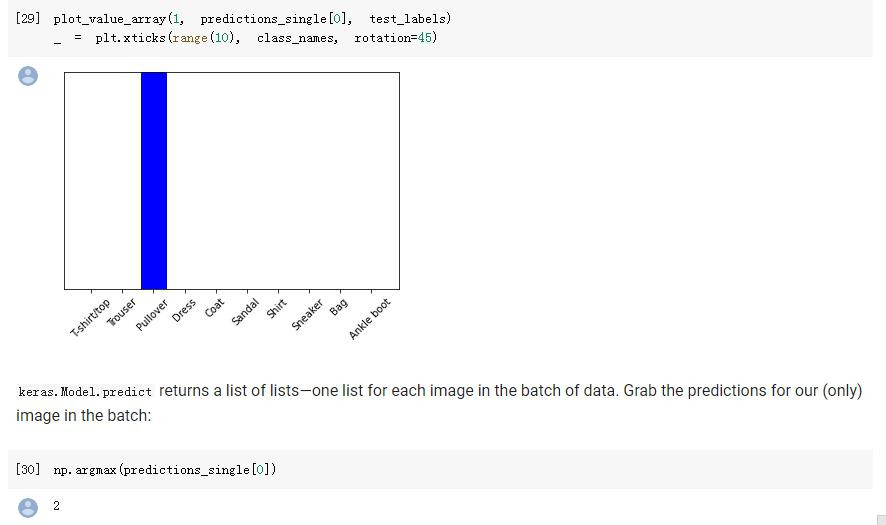
雖然從上到下講得相當長,
但其實只是很粗淺的示範了一下最基礎的範例而已,
深度學習除了圖像分類以外,
從圖片到文字,再到聲音,各種應用可以說是包山包海;
更不用說還有不同的模型建立方式與架構,
今天的介紹連冰山一角都稱不上XD
若讀者有更深入的興趣的話,可能就要從更基本的機器學習部分出發了!
除此以外,若要自己進行深度學習的訓練的話,
架構一個環境還是很有必要的,
就再請讀者閱讀一下其他大大們的教學呦!
那麼,我們就明天見囉!

