
DL x NLP 的核心和尖端的研究結果介紹差不多告一段落了。接下來兩篇分別介紹自己做的 project 和 NLP 發展。
這次要介紹的是我在 Stanford CS224n 修課時做的 project "An Exploration in L2 Word Embedding Alignment"。這個 project 其實成果很差,老實說還滿猶豫要不要改成介紹另一個更早在中研院做的 SeqGAN,成果比較好看一點。
但想一想,既然是以學生角度撰寫的文章,不能總是展示好的東西。在摸索階段肯定會失敗,從失敗中也有很多東西可以觀察跟分享,挺有趣的。
當時在決定主題上因為先前有過比較好的 NLP project 的經驗了,所以決定實現一個大膽一點的點子。雖然等等大家就知道這點子撞壁了,但我還是想說一件事:學生不要怕失敗,因為只有在還是學生的時候可以不斷失敗!
這次的 project 放在 pyliaorachel/bridge-with-l2,包括 report 和 poster。
對我在中研院用 SeqGAN 做 paraphrase generation(轉述句生成)有興趣的,code 和 report 都放在 pyliaorachel/SeqGAN-paraphrase-generation。
NLP 中有個任務叫做 cross-lingual word embedding alignment,是將兩種語言的 word embedding 各自訓練好後,找到方法讓這些 word vectors 在空間中對應。如此一來,就能以 unsupervised 的方式取得兩種語言之間的字詞翻譯:

—— Unsupervised word embedding alignment。[1]
而我當時的 hypothesis 是:假設我們想從中文對應到英文的 word embedding,兩個都是建立在母語人士的 corpus 上。那如果能把英文 word embedding 訓練在中文母語者講英文的 corpus 上,那麼因為文法上會摻雜更多中式思維,訓練出來的英文 embedding 就能跟中文 embedding 更接近,也更能自然對應了。

—— L2 word embedding alignment。
母語人士說自己語言的 corpus 稱為 L1 corpus,而非母語人士說另一種語言的 corpus 稱為 L2 corpus。這個 project 就是要來研究 L2 target word embedding 和 L1 source word embedding 更接近這個 hypotheses 到底能不能成立。
當初想到這個 idea 已經是 proposal 死線,也就沒管太多實行上的問題,先寫起來再看看 mentor 怎麼說。而我的 mentor 就是教授 Christopher Manning 本人。他的 feedback 是,想法感覺是成立的,並指引我可以去 arXiv 撈一些 L2 data 來訓練。這條不歸路就這麼開始了⋯⋯
主要針對 Chinese to English alignment 研究。這邊會需要三種 dataset:
L2 corpus 比較難找,mentor 建議我去 arXiv(paper 資料庫)用爬蟲爬一些中文人士寫的英文 paper 作為 L2 data,我也覺得是個不錯的點子。還有在網路上找很久收集到的 English learner essay corpus,收集了中文地區人士寫英文 essay 的資料。
Source 和 target L1 corpus 都滿多選擇的,最後 source L1 用 Wikipedia、微博、以及 Wikipedia 根據 arXiv 分類篩選的 corpus。
Target L1 也選用 arXiv,不過不篩中文母語作者。另外還有 Twitter 和 Common Crawl 這兩種。
這些 L1 corpus 都有選用和 arXiv 相關的 corpus,主要是怕資料的 domain 差太多影響結果,所以盡量讓他們接近。
跑實驗的方法有兩步驟:訓練 word embedding、align word embedding。
這兩個都有現成的程式可以跑,所以其實這方面不需要額外寫太多 code。訓練 word embedding 用之前介紹的 Gensim 即可。Word embedding alignment 則是用原本做 unsupervised word embedding alignment 這篇 paper [1] 中開源的程式碼和 script,相當方便。
簡單介紹一下他們的 model。目標是學習一個 mapping W 來將一個 embedding X 對應到另一個 embedding Y 上,也就是減少將 X 透過 W 轉換之後和 Y 的差距:
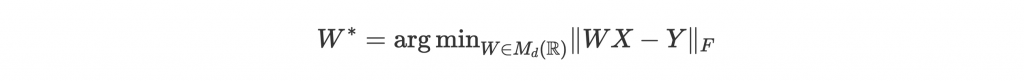
這個形式的問題稱為 orthogonal Procrustes problem,藉由 SVD (Singular Value Decomposition) 就能解。但有個條件是 X 和 Y 必須是 parallel data,也就是在已經知道 X 和 Y 之間的 mapping 的情況下才能找到轉換 matrix W。這是我們想學但沒有的,怎麼辦呢?
作者用了 GAN (Generative Adversarial Network) 的架構來訓練 W,這個架構我們之後會介紹到。簡單來說,我們訓練一個 generator 來預測正確的 W mapping,但同時訓練一個 discriminator 判斷一個字來自 source 或 target,如果能正確判斷,就代表 generator 做得不好,要繼續調整;反之不能判斷,就代表 discriminator 做得不好,要繼續調整。兩邊互相學習的情況下,最終就能訓練出一個不會被 discriminator 打槍的 generator 來預測正確的 W。
我們用 word translation 結果的準確度來進行 evaluation。這邊跟 paper [1] 用了一樣的兩種方法來取每個 embedding 在另一個語言中最靠近的 embedding:
用兩種方法對每個 source word 找出 k 個最近的 target word 後,我們用 translation precision@k 來檢驗結果。
我們用做了幾組實驗,也就是不同 source-target dataset pair 用 NN 或 CSLS 取 k 個 translation 後,計算 precision@k。除了 unsupervised 我們也試了 superivsed alignment 作為 topline result。
結果如下:

—— Word translation precision@k results。wiki_t 是主題篩選過的 Wikipedia corpus。arxiv_lx 是 arXiv 的 L1 或 L2 corpus。Precision 結果 U/S 代表 unsupervised / supervised alignment。
wiki-wiki (full) 是 paper [1] 的結果。淡金色區域是不考慮 L2 corpus,用大型 L1 corpus 來檢驗 corpus 大小和 domain 對 alignment 結果的影響。白色灰色區域則是 align L1 和 L2 的結果,但用了不同的 embedding method (f = fastText,w = Word2Vec)。
結果非常慘,alignment 可以說是完全沒訓練起來。但有很多東西值得一一分析:
從灰白區域不同 corpus 大小(# Sent (tgt))的實驗中可以看出,880K 大都表現得比 480K 好。但從 wiki-wiki (full) 和 wiki-wiki 的結果可以看到 wiki-wiki 遠遠比不上 wiki-wiki (full),但是這兩者只差在 vocabulary 的大小。也就是說,大一點的 corpus 確實有幫助,但主要原因是因為 vocabulary 也會因此變大。
wiki-wiki 和 wiki-crawl 差在 corpus domain 是否一樣。而從結果來看,wiki-crawl 也是遠遠不及 wiki-wiki。也就是儘管 Wikipedia 和 Common Crawl 都很大,domain 之間差越大,結果越差。
從 wiki_t-arxiv_l1 和 wiki_t-arxiv_l2 比較可以看出,不管是 unsupervised 或 supervised,差距都不大。但因為結果都太慘了,所以 hypothesis 也不太有辦法印證。
不過我覺得結果差的主要原因不是 hypothesis 錯了,而是 corpus domain 的差距太大。這點從 wiki-crawl 跟其他實驗的結果一樣慘就能說明。雖然我們為了平衡差距對 Wikipedia 做了主題篩選,也沒辦法提升結果。
另外兩邊 corpus 都用 Wikipedia 其實已經很犯規了,因為不同語言的 Wikipedia 有很自然的對應關係,基本上跟其他 dataset pair 比起來是穩操勝券啊!
其實回頭看這個 project 還是覺得這個點子很有趣,但實行起來才會發現很多盲點,例如找到品質再好的 L2 corpus 其實都比不上 Wikipedia 的自然對應。
再來整個 project 有很多時間都投入在爬 data 上,這也是當時做得很崩潰的原因,因為爬到後來一直被 arXiv 鎖。我還以為我在做 NLP project 呢,原來是爬蟲 project!更崩潰的是教完報告 mentor 才跟我道歉說忘了 arXiv 有禁爬蟲的政策,應該早點跟我說的。沒事,我沒事⋯⋯
最後 hypothesis 也因為 domain 差距這個問題沒辦法證實。不過心得就是這篇 paper 原來很作弊,使用 Wikipedia 才得到這麼好的結果,否則用其他 corpus 那個 GAN 根本訓練不起來啊。
後記
雖然這個 project 成果並不好,但在隔年申請 CS224n 助教的時候,還是雀屏中選。還好這次的失敗沒有讓我喪失這個寶貴的機會(在 Stanford 當助教,學費全免還有優渥薪水拿),或許是教授有看出我有想法,或許是有之前的成果作靠山,也或許是教授對之前沒有指引我正確方向心有愧疚?!
總之儘管這個 project 讓我當時做到痛不欲生,甚至做到一半想直接換主題,但還算是帶給我很多實質上的收穫!

 iThome鐵人賽
iThome鐵人賽