技術文章
技術問答
My Project
iT 徵才
聊天室
2026 鐵人賽
登入/註冊
文章
問答
Tag
邦友
鐵人賽
搜尋
第 12 屆 iThome 鐵人賽
DAY
16
0
AI & Data
AWS 數據處理與分析實戰
系列 第
16
篇
Day 16 Glue ETL Job 教學 - Part 3
12th鐵人賽
eric88348
2020-09-30 08:53:33
1877 瀏覽
分享至
Job 的基礎設定完成後,接下來要設定資料源與輸出目標
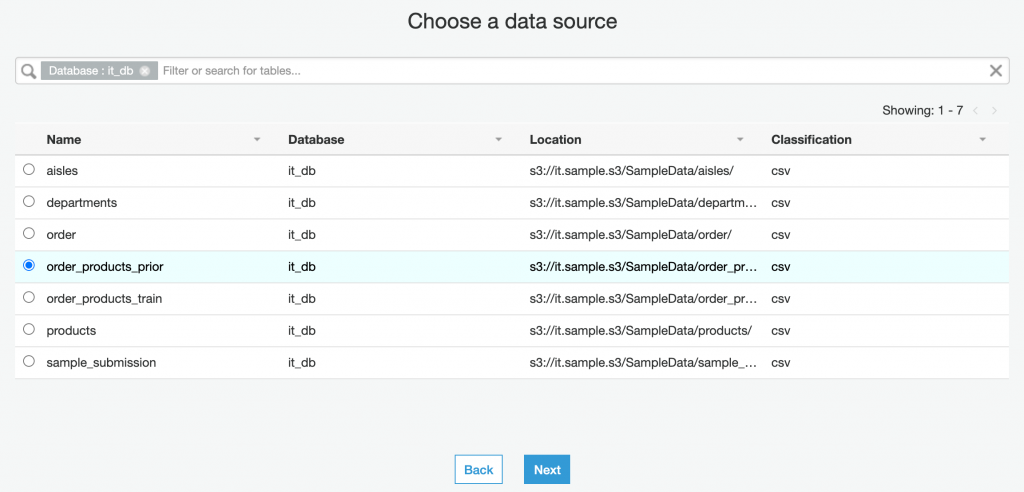
這一步驟可以選擇要處理的資料源,選擇 Glue Data Catalog 中的 Table,這邊我們選擇 order_products_prior,就可以繼續往下
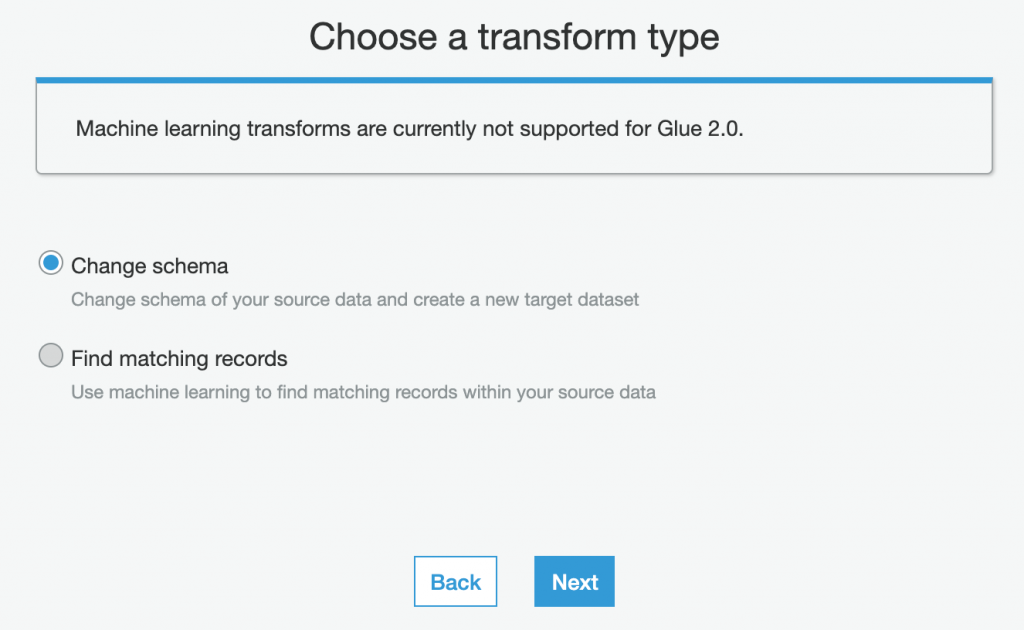
這個步驟我們選預設的 Change schema
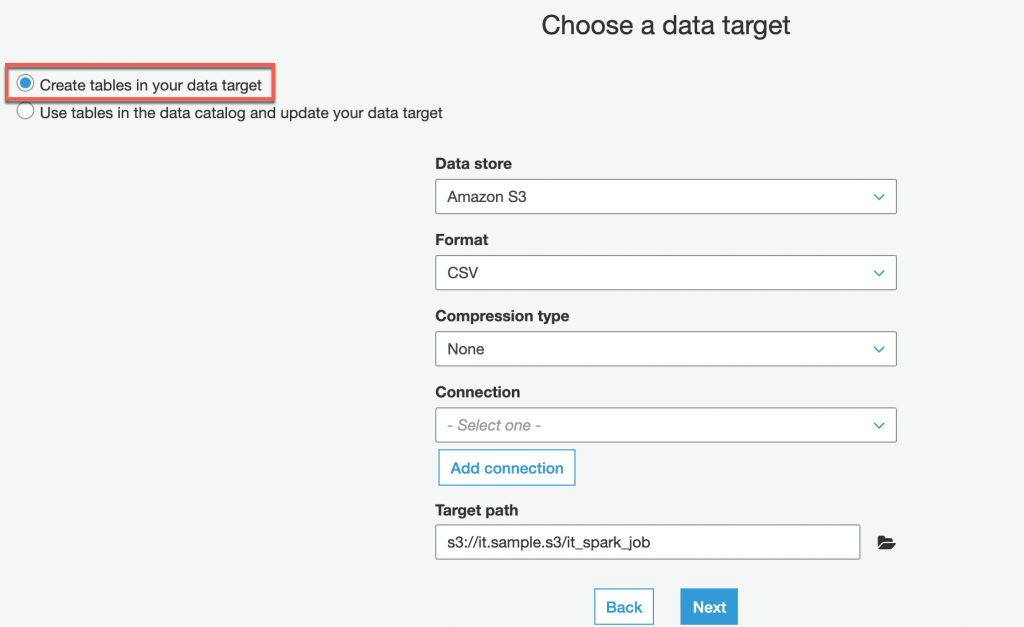
這個步驟就要選擇要寫入的目標,這邊請先選擇 Create tables in your data target,之後可以看到另一個設定頁面
Data store:這邊可以選擇 S3 與 JDBC,JDBC 可以連結 Redshift、RDS、DynamoDB、etc 的資料庫,但這次我們先選擇 S3
Format:資料儲存的格式選擇 CSV
Compression type:檔案壓縮的部分先不進行壓縮
Target path:這部分可以填入要寫入的 S3 路徑,記得要與資料源的資料夾分開
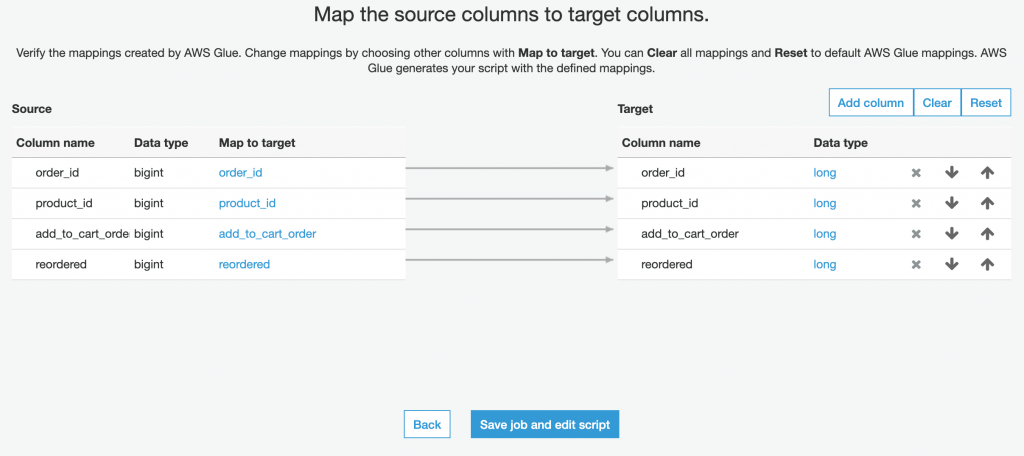
欄位設定,這部分可以使用圖形化介面的方式設定儲存的欄位資訊,可以調整欄位順序、欄位的資料類型、增減欄位
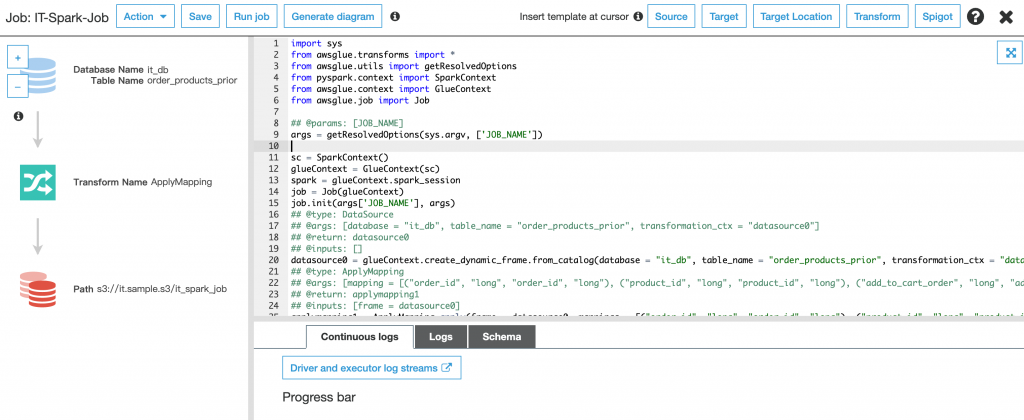
設定完成後 Glue 會產生出基本的 PySpark 程式碼,這個程式碼可以直接將資料從資料源按照所設定的內容搬遷到 S3 或是以 JDBC 連線的資料庫中
留言
追蹤
檢舉
上一篇
Day 15 Glue ETL Job 教學 - Part 2
下一篇
Day 17 Glue ETL Job 教學 - Part 4
系列文
AWS 數據處理與分析實戰
共
30
篇
目錄
RSS系列文
訂閱系列文
14
人訂閱
26
Day 26 持續同步 S3 資料到 Redshift - Part 1
27
Day 27 持續同步 S3 資料到 Redshift - Part 2
28
Day 28 QuickSight 連接 Redshift - Part 1
29
Day 29 QuickSight 連接 Redshift - Part 2
30
Day 30 QuickSight 功能介紹
完整目錄
熱門推薦
{{ item.subject }}
{{ item.channelVendor }}
|
{{ item.webinarstarted }}
|
{{ formatDate(item.duration) }}
直播中
立即報名
尚未有邦友留言
立即登入留言
iThome鐵人賽
參賽組數
50
組
團體組數
2
組
累計文章數
33
篇
最後報名日
9/15
看影片追技術
看更多
{{ item.subject }}
{{ item.channelVendor }}
|
{{ formatDate(item.duration) }}
直播中
熱門tag
15th鐵人賽
16th鐵人賽
13th鐵人賽
14th鐵人賽
17th鐵人賽
12th鐵人賽
11th鐵人賽
鐵人賽
2019鐵人賽
javascript
2018鐵人賽
python
2017鐵人賽
windows
php
c#
linux
windows server
css
react
熱門問題
ChatGPT Business & Codex 如何從零開始?
關於LSTM 做IDS分類資料集處裡
CODEX 桌面版本app重啟後分頁老是消失 (為什麼)
熱門回答
ChatGPT Business & Codex 如何從零開始?
熱門文章
[Tedium Is Stability-03] 與 AI 一起開發,轉念:別再「調 prompt」,你要設計的是一個「循環」
Day 01 - Claude Code 其實就只是一個 while 迴圈
2026 年網站設計新工具,CrocoBuilder 原生 AI 的 WordPress 網頁編輯器
【AI Agent 架構】Agent 不是越複雜越好:哪些機制該留,哪些可以拿掉?
Agent 產生的 UI 能顯示,不代表它已經可以上線
IT邦幫忙
×
標記使用者
輸入對方的帳號或暱稱
Loading
找不到結果。
標記
{{ result.label }}
{{ result.account }}


 iThome鐵人賽
iThome鐵人賽