除了 Learned Index 與 B+-Tree 的比較外,Kraska et al. 也與其他學者所設計的索引結構進行比較。
比較所使用的資料為 Lognormal data,在這裡不介紹其他的結構,如果需要我有放一些參考文獻,而這裡使用的 Learned Index 稱為 Multivariate Learned Index,可以把它想像成是一個變種的Learned Index。Multivariate Learned Index 所選取的資料特徵為: key, log(key), key^2,第一層的Model 使用 multivariate linear regression,第二層都為簡單線性回歸。

測試結果與其他的結構相比,Learned Index 的讀取時間與空間成本都比較好 !
使用Google真實產品中超過10M的資料,key為字串,比較對象為 B-Tree(其實是B+-Tree)和 一些不一樣的Learned Index,可以分成 Learned Index, Hybrid Index, Learned QS。
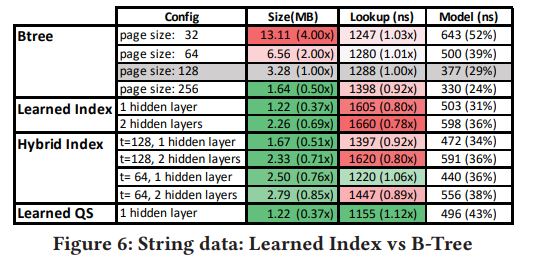
其實從結果我們可以看到,對於 String Data,Learned Index 的查詢效能較沒有明顯的突出結果,但是從空間成本來看,依舊遠優於 B-Tree。
測試結果大致講完拉~~
其實本篇論文後面還有針對 Hash Table、Bloom filter 所設計出的 Learned Index 進行比較,但在這裡不多做講解,光是 B-Tree 的比較就夠多了..Q
明天會做個簡單的總結心得~~~掰噗 !
References
FAST: C. Kim, J. Chhugani, N. Satish, E. Sedlar, A. D. Nguyen, T. Kaldewey, V. W. Lee, S. A. Brandt, and P. Dubey. Fast: Fast architecture sensitive tree search on modern cpus and gpus. In SIGMOD, pages 339–350, 2010.
Fixed-size B-Tree & interpolation search: Database architects blog: The case for b-tree index structures. http://databasearchitects.blogspot.de/2017/12/ the-case-for-b-tree-index-structures.html.

