今天要來測試並比較我們實作出的 Learned Index 與單一 Model(SLR、NN) 的分布情況,我們隨機產生 100k 筆 Lognormal (mean=0, sigma=2)分布的資料,產生出來的值乘以1000000。
Learned Index可分為 9 種:第一層 Model 為 SLR、8x8 NN、16x16 NN,第二層的 Model 都為 SLR,只是數量配置不同,可分為 3、10、100,總共 9 種 Learned Index。單一 Model 則分為 SLR、8x8 NN、16x16 NN、32x32 NN 共 4 種。
NN Model的參數配置如下(大家可再自行測試調整):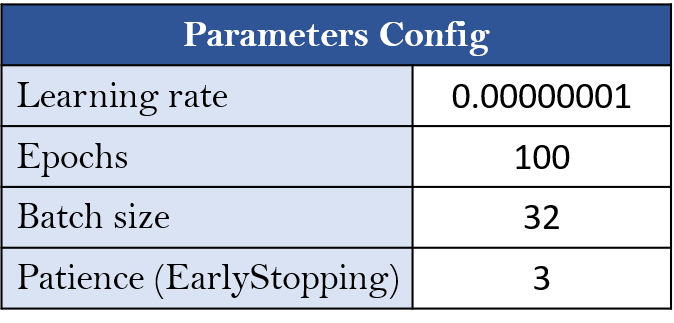
Learned Index不同配置下測試結果的比較圖,圖表標題表示的意思為Learned Index(第一層的模型為何, 第二層模型的數量) :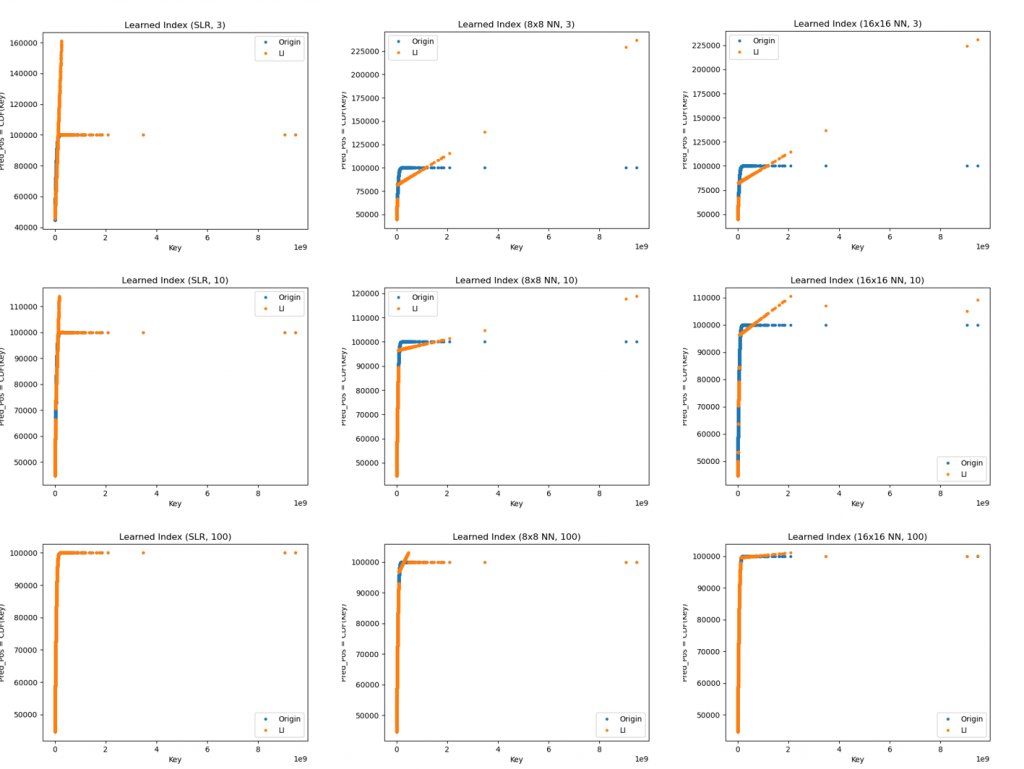
不同Single Model測試下的比較圖 :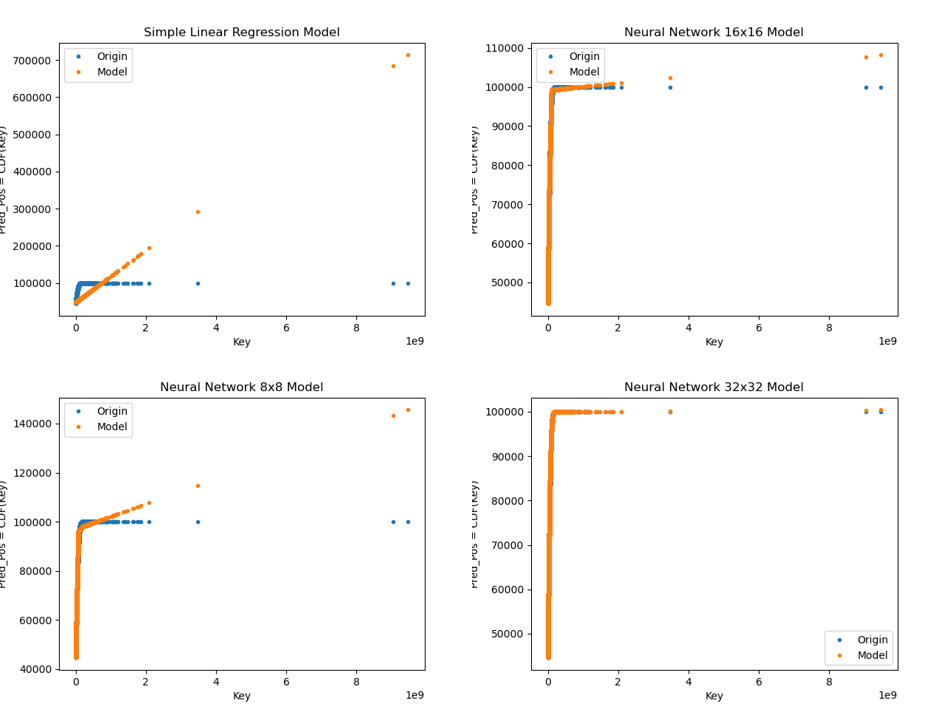
測試完可以看到,對於 Learned Index 來說,第二層 Models 數量配置越多,越擬合 CDF分布,依據我們測試結果發現,對於 Learned Index 來說,架構配置為(SLR, 100) 最擬合 CDF分布! 跟我原本預想的不一樣,我以為(8x8, 100)、(16x16, 100)的配置會最好的說><,對於單一模型來看,NN 32x32模型擬合效果最佳!
其實測試完後,感覺不用配置到相較複雜的Learned Index,使用單一模型 NN 32x32,就足以擬合分布嘞。但我們也只是進行簡單的測試,資料數量很少只有100k,當資料來到 100M,Learned Index 是否會真的比較適合,是很值得去探討的地方! 另外 Model 調參的部分,我是手動去調 XD,也許還其他更佳的參數配置,對於 Model 訓練更好!

