大家好,昨天看過了「Pokemon-Weedle’s Cave」資料集,知道其中有哪些資料,今天要對這些資料進行分析。
首先匯入套件,讀取和觀察資料一樣是使用pandas函式庫的方法:import pandas as pd
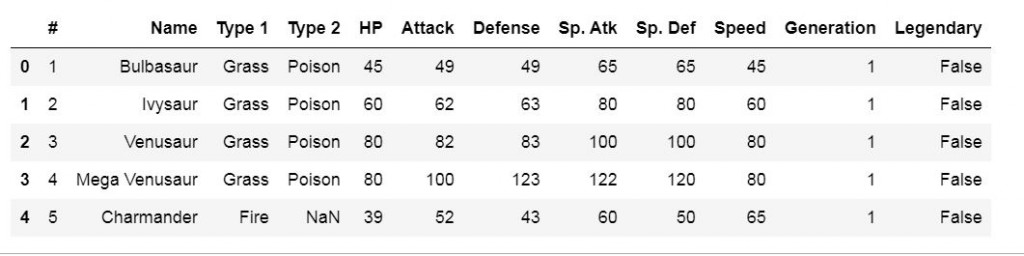
再來讀取pokemon.csv和combats.csv的資料:
pokemon_df = pd.read_csv('pokemon.csv')
pokemon_df.head()
combats_df = pd.read_csv('combats.csv')
combats_df.head()
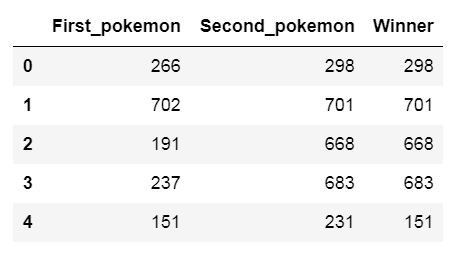
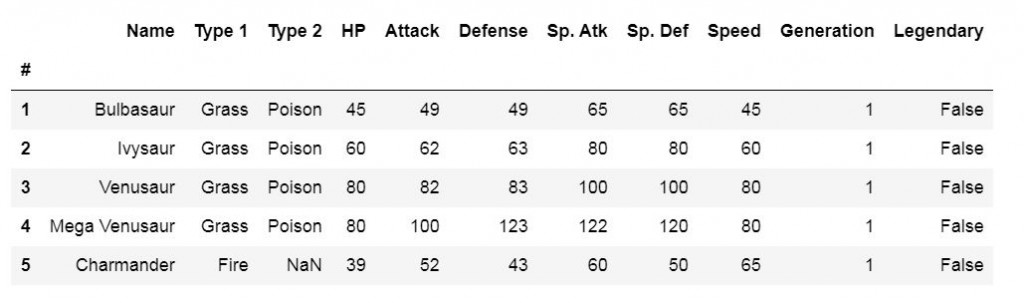
然後把pokemon.csv中的”#”資訊設為索引值:
pokemon_df= pokemon_df.set_index("#")
pokemon_df.head()
接著檢查資料是否有缺失:
pokemon_df.info()
combats_df.info()
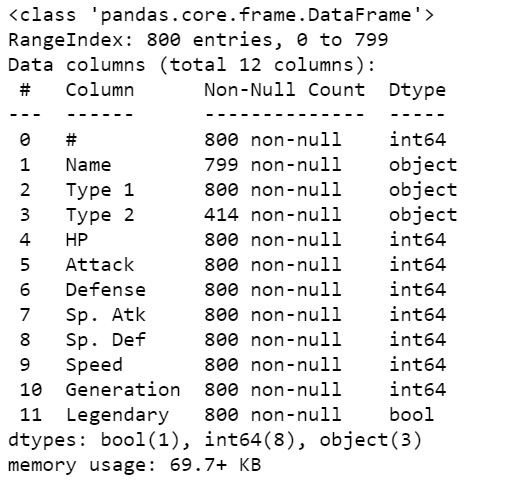
其中pokemon.csv的Name和Type 2有缺失資料,Name的資料在訓練時不會使用,不影響訓練結果,不過Type 2就會有影響,所以需要進行資料的填補。
先查看Type 2資料每個類別有多少,在value_counts方法中傳入dropna=False參數,可以把缺失的資料算入,以NaN表示。pokemon_df["Type 2"].value_counts(dropna =False)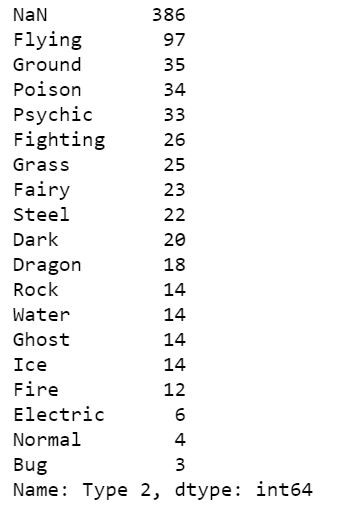
缺失的資料代表寶可夢沒有第二個屬性,所以就用'empty'填補缺失:
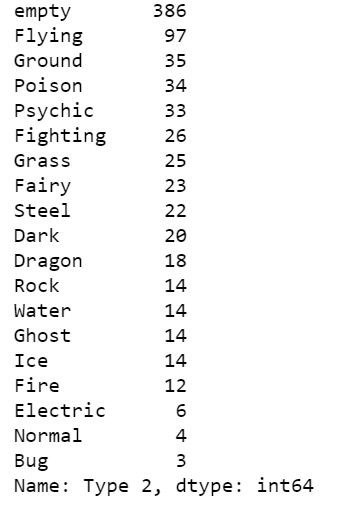
pokemon_df["Type 2"].fillna('empty',inplace=True)
pokemon_df["Type 2"].value_counts()


 iThome鐵人賽
iThome鐵人賽