大家好,昨天讀取了資料集,對資料進行觀察,並且填補有缺失的資料,今天要對這些資料進行處理。
首先要處理的是資料型態的問題,讀取的這些檔案中有資料是無法直接輸入模型的型態,所以要進行轉換,先顯示資料型態做觀察。
print(pokemon_df.dtypes)
print(combats_df.dtypes)
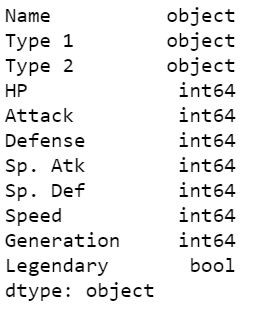

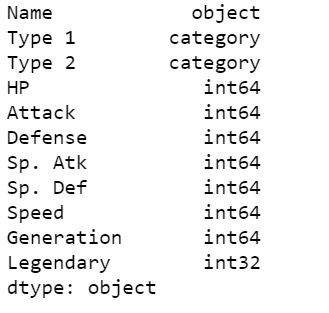
可以發現pokemon_df裡,Name、Type 1、Type 2、Legendary的資料型態是object和bool,這些是無法直接輸入模型,其中Name是不會用到的資料,之後會從資料集中去除,其他的則是要進行轉換,要將Type 1、Type 2的資料型態從object轉為category,之後會再透過這個型態下的cat.codes方法轉為數值表示;將Legendary的資料型態從bool轉為int,False和True會用0和1來表示。
pokemon_df['Type 1'] = pokemon_df['Type 1'].astype('category')
pokemon_df['Type 2'] = pokemon_df['Type 2'].astype('category')
pokemon_df['Legendary'] = pokemon_df['Legendary'].astype('int')
pokemon_df.dtypes
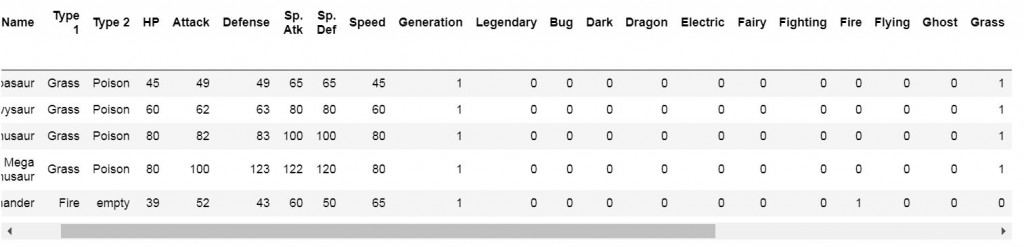
接下來會使用one-hot encoding和數值來表示寶可夢的屬性,用作之後訓練資料的比較。
先分別取得Type 1和Type 2的one-hot encoding,方法是pd.get_dummies:
df_type1_one_hot = pd.get_dummies(pokemon_df['Type 1'])
df_type2_one_hot = pd.get_dummies(pokemon_df['Type 2'])
再將兩組one-hot encoding合併,然後併回資料集:
combine_df_one_hot=df_type1_one_hot.add(df_type2_one_hot,fill_value=0).astype('int64')
pokemon_df = pokemon_df.join(combine_df_one_hot)
pokemon_df.head()
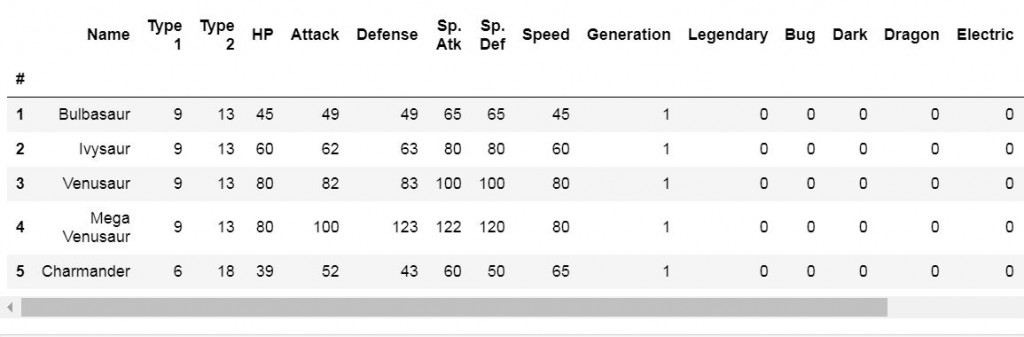
數值表示的部分會轉換Type 1、Type 2型態為int,並且取代原本Type 1、Type2的資料:
pokemon_df['Type 2'].cat.codes.head(10)
pokemon_df['Type 1'] = pokemon_df['Type 1'].cat.codes
pokemon_df['Type 2'] = pokemon_df['Type 2'].cat.codes
pokemon_df.head()
接著去除不會用到的資料name:pokemon_df.drop('Name', axis='columns', inplace=True)
最後將combats_df裡獲勝的表示改成0和1,第一支贏表示成0,第二支贏則是1:
combats_df['Winner'] = combats_df.apply(lambda x: 0 if x.Winner == x.First_pokemon else 1, axis='columns')
combats_df.head()
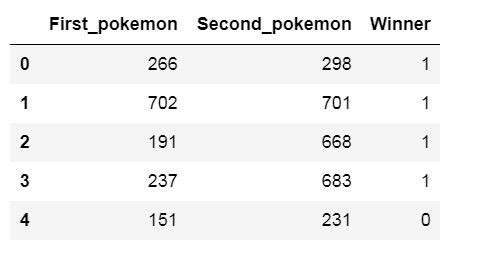


 iThome鐵人賽
iThome鐵人賽