延續昨天的使用的套件管理平台Anaconda,今天我們要來下載會使用到的套件至我們的虛擬環境嚕 !
我們使用Anaconda提供的介面話設定下載 :
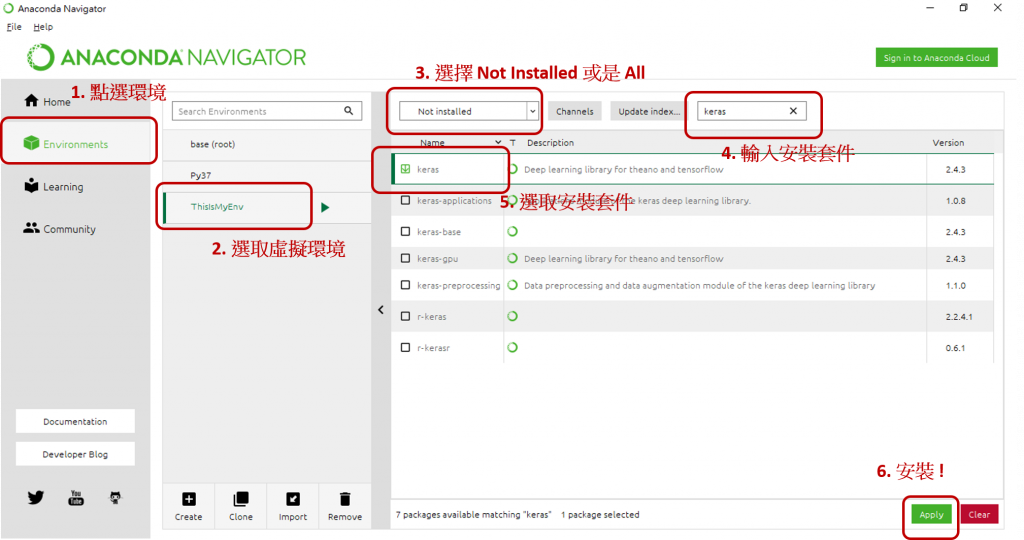
有時安裝時會遇到一些問題 :
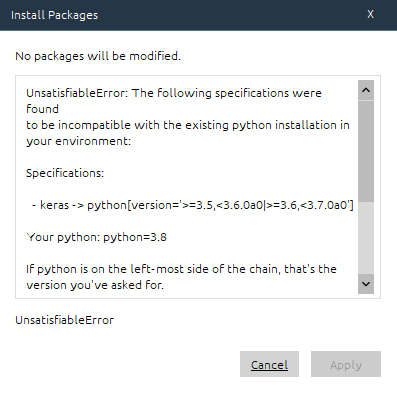
上圖為版本問題,由於我建置的環境為python 3.8,keras目前此版本的套件~
解決方法 => 重建一個小於 python 3.8 版本的虛擬環境 !
這些都是所需要的軟體套件(搞不好也不會全部用到,反正先載再說 XD)
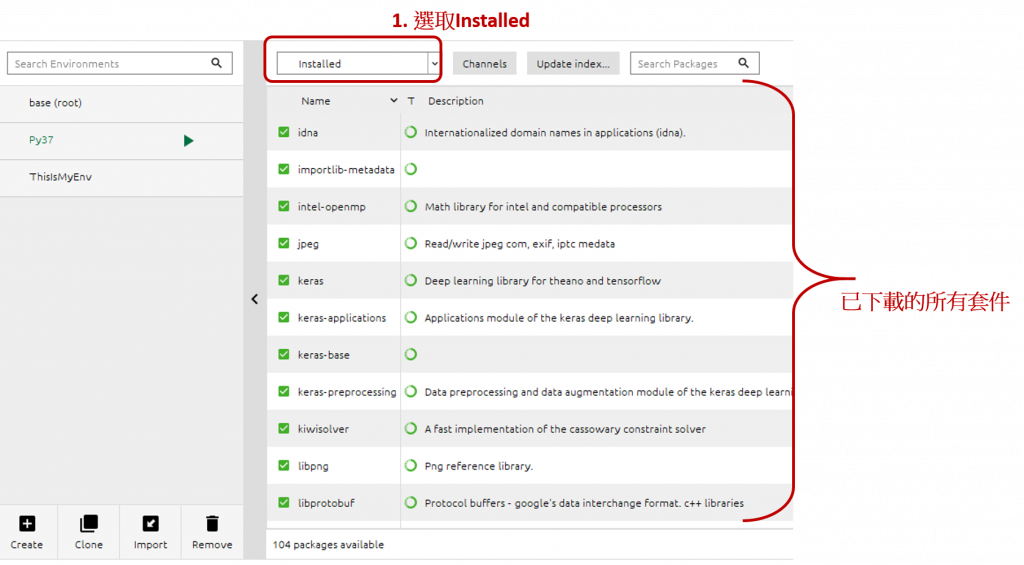
下載完後,可以選取 Installed ,查看下載的軟件包有甚麼 :
回顧一下,Learned Index 的精隨就在於 : 已排序好的 Key 值,經由 CDF產生的值乘上所有的Key值數量,會近似於 Key所在的位置 (Array中的位置)
N為Key總數量,Pos為預測的位置。
那我們該如何產生 CDF 呢 ?
感謝 Python 各種強大的軟件,我們可以使用 Scipy 內建的 CDF 函式。
x為輸入的Key值,loc 表示平均值,scale 表示標準差。
from scipy.stats import norm
cdf = norm.cdf(x, loc, scale)
我們可以把它包裝成一個 Function,只要給定一個 Key Array, 就可以產生出另一個 CDF Array。
from scipy.stats import norm
import numpy as np
def crtCDF(x):
if(type(x) == np.ndarray):
loc = x.mean()
scale = x.std()
N = x.size
pos = norm.cdf(x, loc, scale)*N
return pos
else:
print("Wrong Type! x must be np.ndarray ~")
return
今天先到這邊,明天再繼續 ~~ 掰噗 !


