舉例來說,今天你拿到一筆資料,老闆要你去預測員工明年有誰會離職?這時候你就可以先想,什麼因素是平常導致離職的關鍵,例如加班時間過長、薪水太低等。在開始做之前先有一個目標,到後面就不至於會手忙腳亂。
資料分成結構化跟非結構化。若拿到結構化的資料,要去暸解每個特徵所帶來的含義,而若拿到非結構化的資料,要將資料作轉換後才能拿來做分析,結構化與非結構化資料的差異舉例如下:
一般來說,會遇到的問題不外乎就是分類(Classificaction)、回歸(Regression)兩大類問題,而什麼是分類及回歸問題呢?舉例來說:我們要預測員工是否離職,這種有標籤的預測就屬於分類問題。而預測當地房價,預測出來的是連續的數值,就是回歸問題。
通常比賽資料會給你每個特徵欄位所代表的意義,有可能是直接寫在網站上,有可能另外給你一個檔案,在拿到資料後記得要先了解資料特徵所代表的含義,會需要了解是因為做資料分析的時候,不一定所有的資料集都與你的領域有相關,最大化的去了解有助於下一步的分析。
通常我們拿到的資料不一定是一份完整的資料,這時候要去觀察資料中的空值有多少,去決定後續做資料前處理時該用什麼方法去補值。
df_train.isnull().sum() #檢查df_train這筆資料缺值數量
舉例來說有一筆資料叫台灣天氣溫度,而資料中有一筆資料顯示1000度,但正常來說台灣根本不會有1000度的天氣,這筆資料就是所謂的離群值,通常我們會搭配視覺化來找出離群值,而離群值若沒處理好,會大大的影響後面分析的結果,所以在前面一定要好好的觀察資料。
通常離群值要搭配統計圖比較容易觀測的出來,這部分留到之後再一併說明。
通常我們比較常遇到的是資料不平衡的問題,這部分沒處理好有可能會讓模型訓練出問題,後面在做資料前處理的時候會再提到解決的方法。
df_train["feature_name"].value_counts() #計算feature_name這個特徵數量有多少
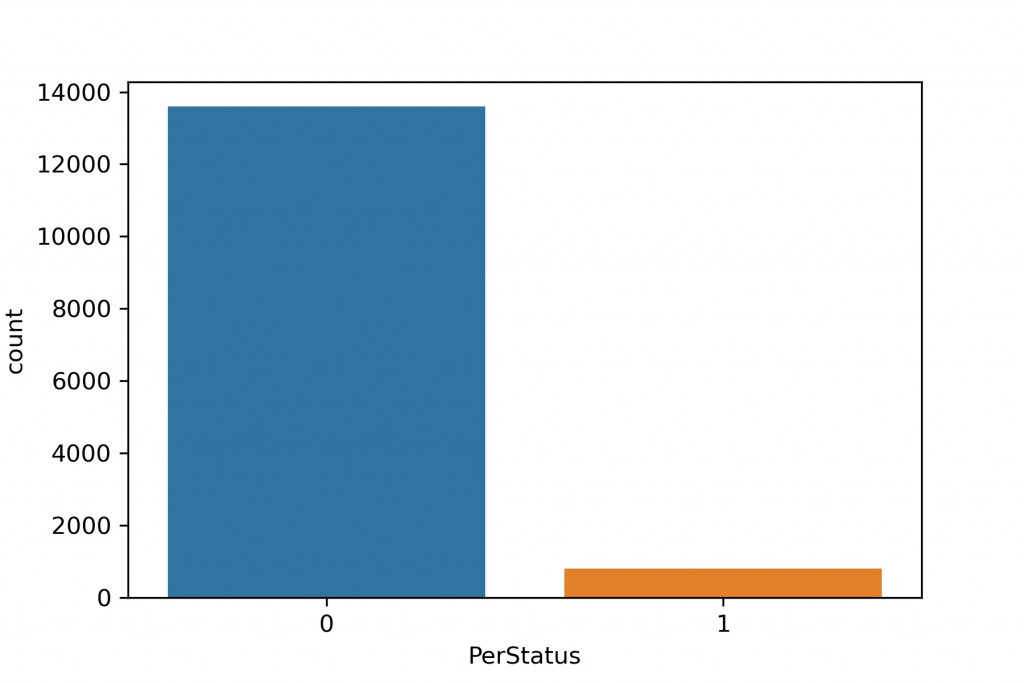
離散型資料:舉例來說,班上男生有幾個,女生有幾個就是離散型資料
連續型資料:而男女生身高資料分佈即為連續型資料
而下一章會以圖來詳細說明。
透過敘述性統計,呈現出各個特徵的統計資訊,讓你對資料有初步的掌握
注意這個並不是每種資料都適用,像一些離散型的資料,用這個方法觀察是沒有意義的,因為資料間是彼此獨立,把它平均是沒有任何意義的。
資料集來源:https://www.kaggle.com/djhavera/beijing-pm25-data-data-set
df_train.describe()
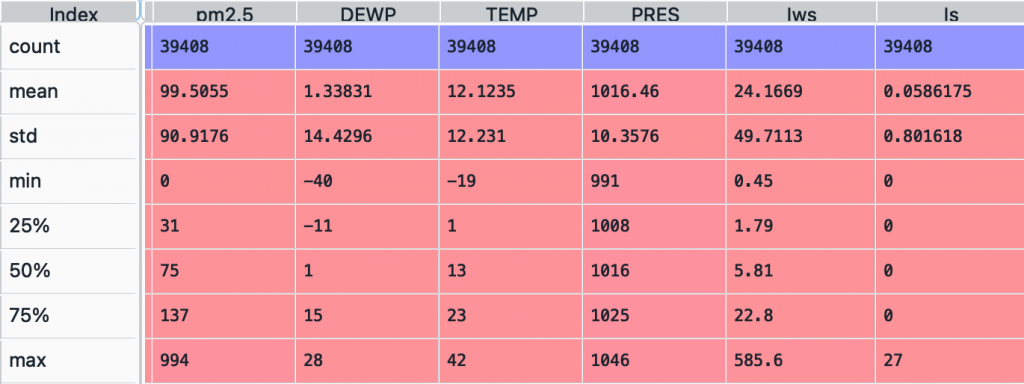
透過以上步驟是不是對資料的掌握度變得更高了呢?大家快去網路上找資料來實際做看看。記住!對資料的掌握度越高,後面的步驟做起來就會越加順手。

