即便是相同原料經過不同師傅的手藝也會呈現不同的味道
(昨天吃的游壽司)
當資料經過基本篩檢後,也會根據後續使用的需求將資料聚合(資料聚合就是將資料從細的顆粒度聚合成比較粗的顆粒)來減小資料的計算量以及儲存空間。以 App 收集的使用者行為來說,只要使用者觸發事件,就會即時地將資料傳回並儲存下來,等於說每秒、甚至每幾百毫秒就有資料產生,資料量累積下來也非常的龐大。如果一天能產生 100 GB 的資料,那個一個月下來就是 3TB,一年就將近 40 TB 的資料,這樣的資料量對於後續的資料分析或使用都會造成相當的麻煩。當後續使用不需要顆粒度那麼細的資料時,就能透過資料聚合能夠將資料整理成可以接受的大小。
我們就有以下這個範例資料來討論資料聚合的兩方面:聚合單位以及聚合方式。
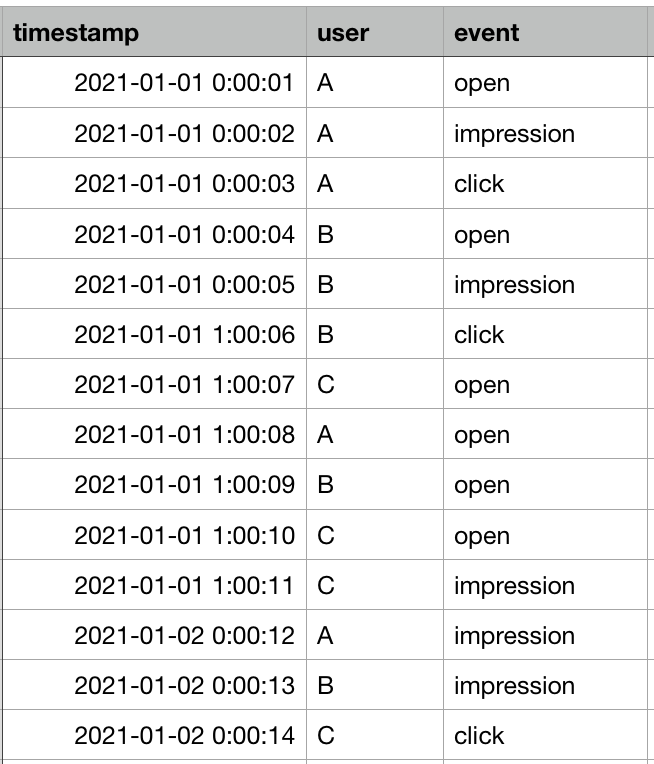
(圖1: 原始資料)
時間是最常被用來聚合的的單位,根據使用方式,通常可以將時間顆粒度分為幾個層面:
搜集使用者資料時常常會包含使用者發出訊號時的位置資訊:
只要是覺得細節可以省略的東西,都可以作為聚合單位,這邊就列出一些常用的給讀者參考。
由於我們是將細的顆粒度整成粗的顆粒度,只能保留部分資訊,因此聚合方式決定了可以保留哪些資訊下來。使用聚合公式的時候需要注意公式是否真的能呈現想表達的意思。
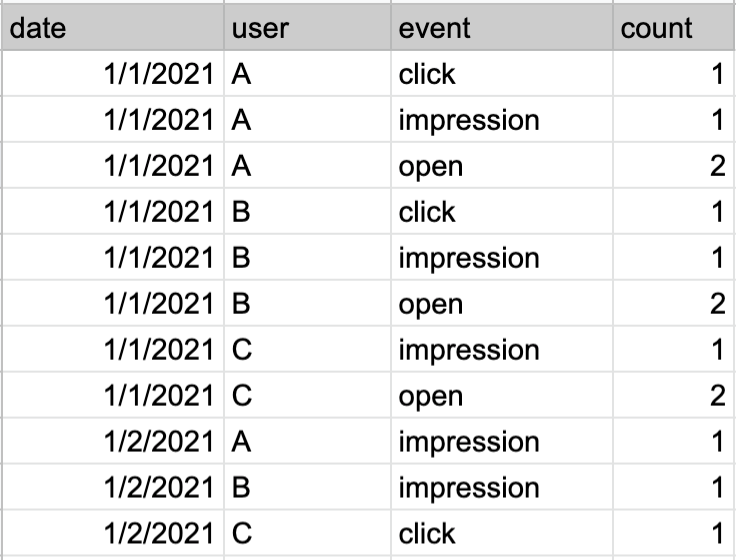
(圖2: 聚合後的資料)
算個數是最單純也不太有風險的聚合方式,例如像圖 2 的範例資料,就會使用 count 來計算像是 "Open"、"Impression" 等事件數。但是一但被 Count 後的聚合資料如果再次 Count 意義就會變得不同。使用上需要注意。
如圖 2 資料,已經使用 Count 計算每天的事件數了,如果想要計算每月的事件數,就沒辦法再次直接 Count,需要透過 Sum 的方式將每天已經 Count 後的數字加總。被加總後的數字如果要再做聚合(例如小時 -> 天,天 -> 月)通常可以直接透過加總得到結果。
不管是哪個顆粒度的資料需要計算這種 XX 率或是平均數,都需要在該顆粒的層次將除法公式還原成分子與分母,然後再進行除法。如果以點擊率(Click 數/ Impression 數)為例:
日點擊率的公式為:
每日 Click 加總 / 每日 Impression 加總
月點擊率的公式為:
每月 Click 數加總 / 每月 Impression 加總
https://www.ibm.com/docs/en/tnpm/1.4.2?topic=data-aggregation
https://www.import.io/post/what-is-data-aggregation-industry-examples/
https://improvado.io/blog/what-is-data-aggregation
https://www.jigsawacademy.com/blogs/data-science/data-aggregation/


 iThome鐵人賽
iThome鐵人賽