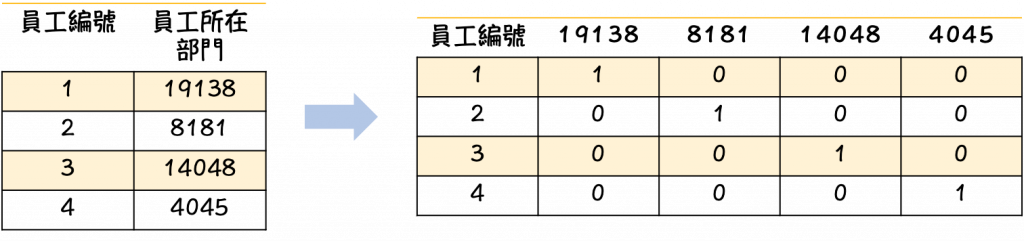
當拿到類別型資料特徵的時候,我們必須將文字轉換成數字供電腦去做計算。舉例來說:員工年齡分布(如上圖),員工所在部門(如下圖)。有發現轉換方式不太相同嗎?我們在下面來做講解。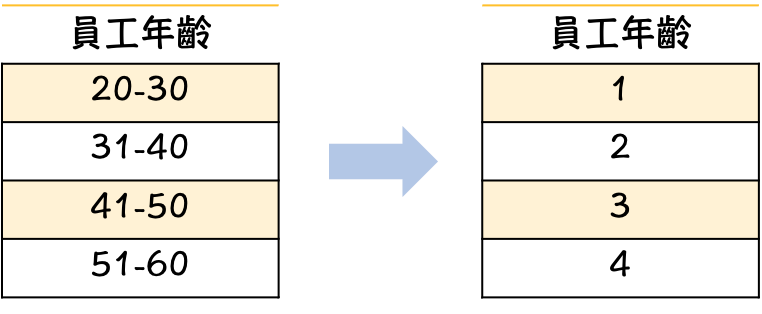
資料編碼一般分為Label Encoding 及 One-Hot Encoding兩種方法。
為何要分有順序跟無順序呢?因為如果把無順序的資料標示成1、2、3電腦會認為3>2>1,但實際上並非如此。所以最後會導致後面在跑模型的時候會不太準確。
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
le.fit(df['你要轉換的特徵名稱'])
le.transform(df['你要轉換的特徵名稱'])
利用pandas的套件可以快速做出
資料集來源:https://aidea-web.tw/topic/2f3ee780-855b-4ea7-8fc8-61f26447af1d
#先生成虛擬變數
temp_department=pd.get_dummies(df_X["歸屬部門"],prefix="歸屬部門")
#將原先資料的特徵刪除
df_X=df_X.drop("歸屬部門",1)
#將原先資料與虛擬變數合併
df_X=pd.concat([df_X,temp_department],axis=1)
機器學習模型需要資料才能訓練,如果將所有資料都丟給模型做訓練,這樣就沒有額外資料來評估模型的好壞,而為了避免模型可能會有過擬合 (Over-fitting) 的情形發生,需透過驗證/測試集評估模型是否過擬合。(如下圖)就有點類似學校考試的概念,如果一直給學生考一樣的考試,那他到最後幾乎就是把答案背起來而已,不會去暸解題目內容,看似這個學生考得很高分,但實際上他根本就不會,因此在丟給模型訓練前,我們要先將資料分配好。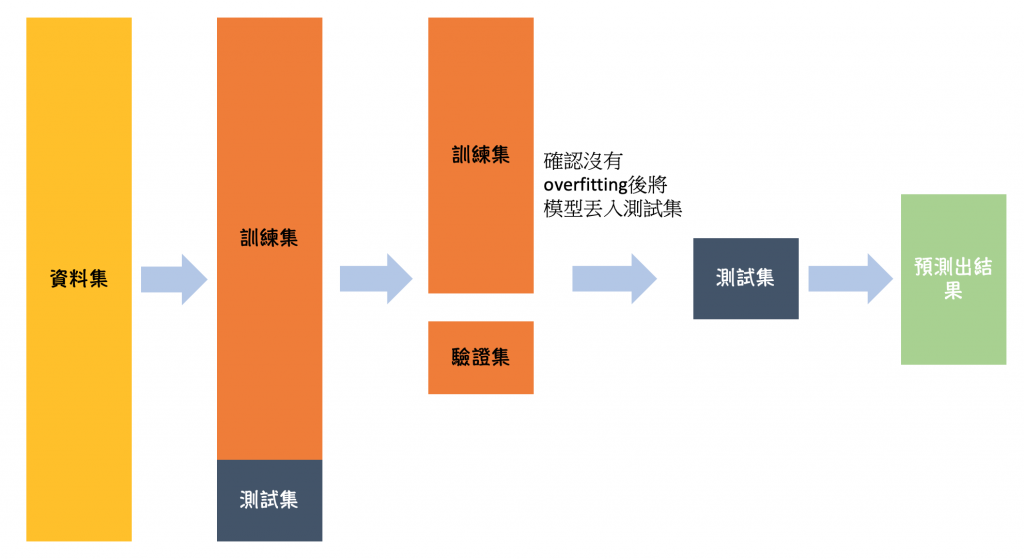
一般來說會將資料分成三份:
而在切分資料時又分成兩種方式:
一般然說我們會將訓練資料與測試資料切割成8:2或7:3的比例
wilt_all = pd.read_csv('wilt_all.csv') #載入資料
#利用模型等比例切割
right_ratio_x_train, right_ratio_x_test, right_ratio_y_train, right_ratio_y_test = train_test_split(wilt_all, labels, test_size=0.2, random_state=666)
#轉換
right_ratio_y_train = le.transform(right_ratio_y_train)
right_ratio_y_test = le.transform(right_ratio_y_test)
把結果print出來
print('right_ratio_y_train class n:', sum(right_ratio_y_train==0))
print('right_ratio_y_train class w:', sum(right_ratio_y_train==1))
print('right_ratio_y_train ratio n:', sum(right_ratio_y_train==0)/len(right_ratio_y_train))
print('right_ratio_y_train ratio w:', sum(right_ratio_y_train==1)/len(right_ratio_y_train))
print('------------------------------------------')
print('right_ratio_y_test class n:', sum(right_ratio_y_test==0))
print('right_ratio_y_test class w:', sum(right_ratio_y_test==1))
print('right_ratio_y_test ratio n:', sum(right_ratio_y_test==0)/len(right_ratio_y_test))
print('right_ratio_y_test ratio w:', sum(right_ratio_y_test==1)/len(right_ratio_y_test))
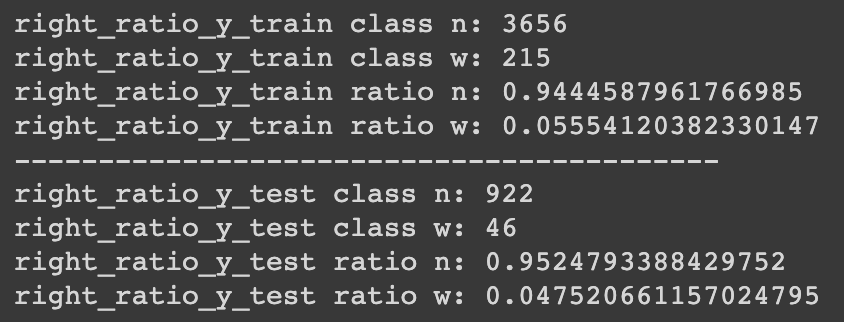
可以發現資料已經被我們等比例切割了。
為了避免正常切割,導致有些資料訓練不到。因此衍生出將資料切成k份讓每個資料都輪流當訓練集跟驗證集。如下圖所示。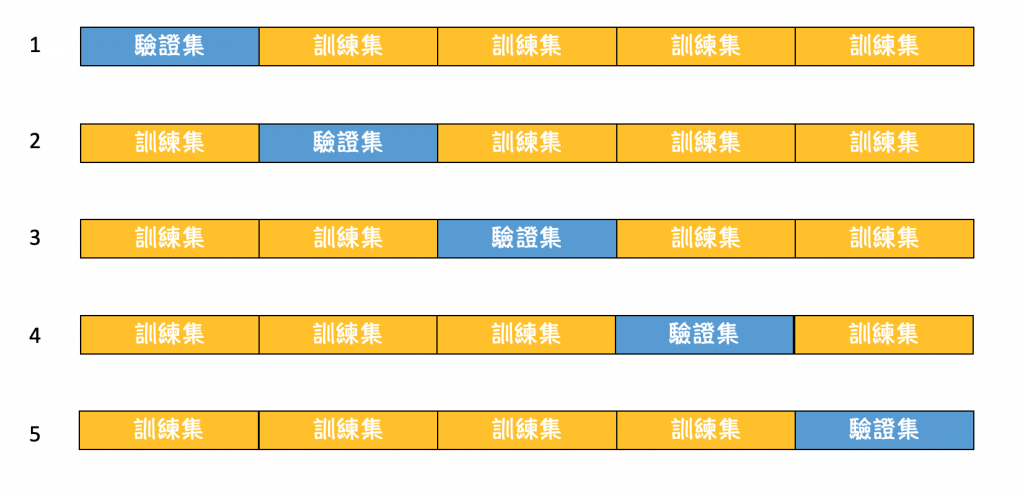
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import cross_val_score
#能夠利用cross validation計算模型之表現,看模型表現是否平均
NB_model = GaussianNB()
scores = cross_val_score(NB_model, right_ratio_x_train, right_ratio_y_train, cv=5, scoring='f1')
scores
資料編碼跟資料分割都是資料前處理中重要的步驟,大家可以試著去找資料來做看看,順便判斷哪些資料需要做資料編碼,哪些不需要。不知不覺我們的挑戰也進行三分之一了,希望目前的教學對大家都有些許幫助,有什麼問題也歡迎拿出來一起討論喔。

