試想一下,如果有個模型號稱有99%的準確率,那這個模型好不好呢?答案是不一定,在處理分類問題時,我們很常會遇到的一個狀況就是"資料不平衡",也就是負樣本的數量遠小於正樣本。
舉個例子,我們在分析信用卡盜刷的資料時,盜刷算是負樣本,發生的次數絕對比正常交易來的多,因此,若完全不做任何處理,我們的模型會大量的學習到正樣本的資料,在預測時很容易發生過度擬合(Over-fitting)的問題,假設正常比盜刷的比例是99:1,我們的模型預測100份資料都是正常,這樣的準確率是99%,可是他完全沒有預測到錯誤的那筆,那這個模型還有用嗎?因此,處理資料不平衡的問題也是一項重要的前處理!
不平衡資料通常發生在良率分析、好壞分辨等案例,因為壞的都是少數案例,我們想要訓練模型挑出這些資料所做的分析。
那所謂不平衡的標準是多少呢?我們可以用鐵達尼號資料集看一下。
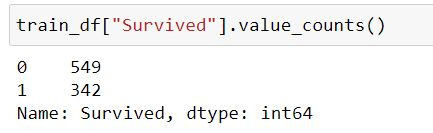
train_df['Survived'].value_counts()
import matplotlib.pyplot as plt
plt.figure( figsize=(10,5) )
train_df['Survived'].value_counts().plot( kind='pie', colors=['lightcoral','skyblue'], autopct='%1.2f%%' )
plt.title( 'Survival' ) # 圖標題
plt.ylabel( '' )
plt.show()
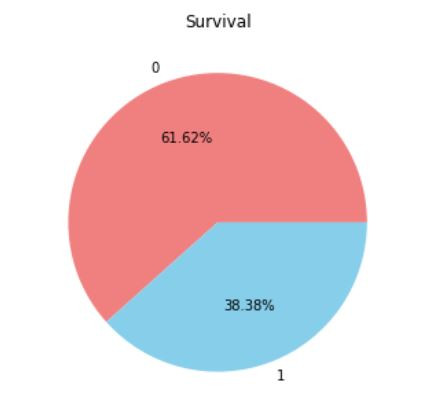
可以看到比例存活與罹難的比例大概是6:4,這樣就是個差不多正常的比例。可以處理也可以不處理,接著讓我們來看看另一份資料集。
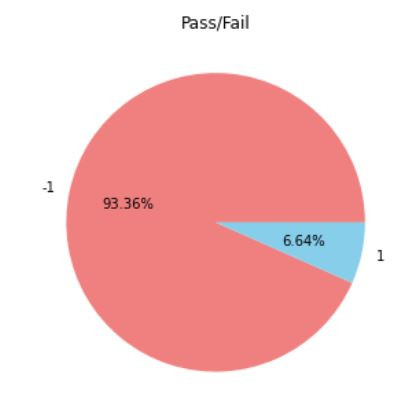
這樣的資料集就是比例相當懸殊的,我們必須經過處理後才能丟進模型訓練,否則就會發生過度擬合的問題,而處理方法分為上採樣(OverSampling)以及下採樣(UnderSampling)。
下採樣的方法是透過刪除較多的樣本數,使兩個類別的樣本數量達到平衡,這樣的方法雖然方便,但其實缺點也很明顯,我們會失去大量的數據,以上面半導體的資料集來舉例,我們假如使用下採樣的方法,我們最後的資料集只會有原本的10%,這樣的方法其實是很不推薦的。
上採樣的作法與下採樣相反,是透過一些方法提升樣本數較少的資料,最常見的方法之一就是SMOTE,他是一種數據合成的方法,概念是在少數樣本附近的位置,"人工合成"出一些樣本,程式碼也非常簡單,我們以Secom的資料集來做示範。
要先做資料分割的動作的原因是,測試集是為了讓我們檢視最真實的評估結果,因此盡量保留它的完整性,不要去做過多的加工處理。
import numpy as np
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3,random_state=11)
import matplotlib.pyplot as plt
plt.figure( figsize=(10,5) )
y_train.value_counts().plot( kind='pie', colors=['lightcoral','skyblue'], autopct='%1.2f%%' )
plt.title( 'Pass/Fail' ) # 圖標題
plt.ylabel( '' )
plt.show()
from imblearn.over_sampling import SMOTE
X_train, y_train = SMOTE().fit_resample(X_train, y_train)
上採樣的效果明顯比下採樣還要來的好,但也存在一個缺點,因為我們會大量的對少數樣本附近進行複製,很可能合成出一些雜訊或是靠近正樣本的資料,而下採樣的方法中有一個叫做Tomek Link的方法,他的概念是能刪除一些邊界辨識度不高的樣本,因此我們可以先採用上採樣合成樣本後,再進行下採樣,把一些是雜訊的資料點剃除,程式碼也非常簡單。
from imblearn.under_sampling import TomekLinks
X_res, y_res = TomekLinks().fit_resample(X_train, y_train)
資料不平衡的狀況在真實情況中蠻常發生的,今天也介紹了一些常見的處理方法,不管使用何種方法最好都透過交叉驗證去檢視資料的合理性,雖然合成的方法可能會缺少一點解釋力,畢竟資料是憑空出現的,我們也不好去解釋他,因此最好的處理方法還是想盡辦法去找到更多資料,希望這篇文章對大家有所幫助。

